

本篇目錄:
一、數(shù)據(jù)頁與索引頁
二、聚簇索引與非聚簇索引
三、唯一索引
四、索引的創(chuàng)建
五、索引的使用規(guī)則
六、數(shù)據(jù)庫索引失效情況
本篇正文:
一、數(shù)據(jù)頁與索引頁
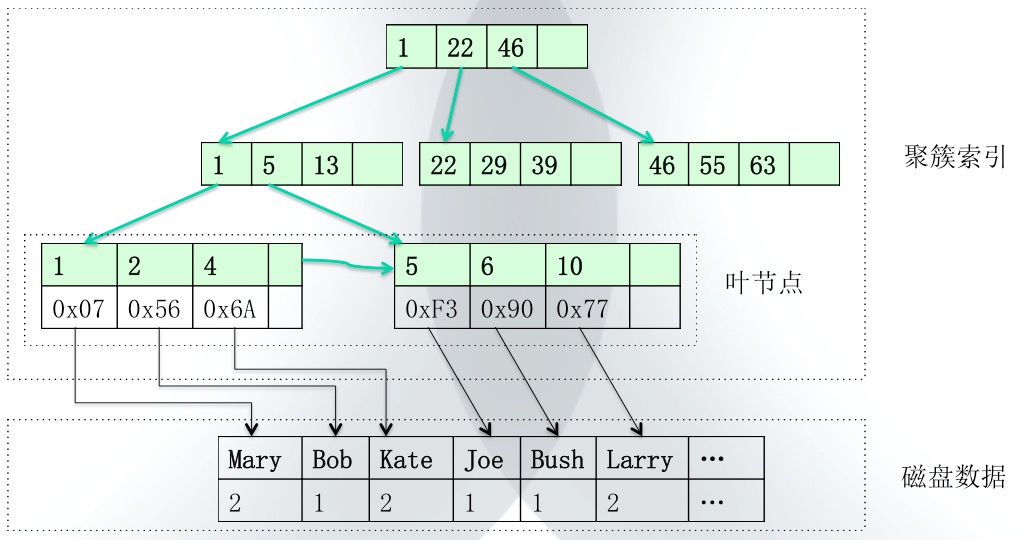
數(shù)據(jù)庫的表存儲分為數(shù)據(jù)頁存儲和索引頁存儲,索引頁中儲存的是指數(shù)據(jù)頁的指針。索引頁所占的存儲空間比數(shù)據(jù)頁要小很多。
二、聚簇索引與非聚簇索引
索引(Index)的存儲方式分為兩種:聚簇索引( Index)和非聚簇索引( Index)。
聚簇索引:它并不是一種單獨的索引類型,而是一種數(shù)據(jù)存儲方式,它指定了數(shù)據(jù)在表中的物理存儲順序。因為單個表在磁盤上只能有一個物理記錄排序方式,所以一個表只能有一個聚簇索引。指定索引列后,數(shù)據(jù)會按照索引列重新一一排序(未指定情況下是按照主鍵排序的),并將其存儲為表的副本。此副本(數(shù)據(jù)頁)和索引頁存儲需要額外占用的空間大小,至少是該表的120%。此外,在插入新行、更新行的索引列值時,DBMS將自動對數(shù)據(jù)重新排序,經(jīng)常大量插入行或更新索引列的值時mysql數(shù)據(jù)庫索引有哪些,盡量不要使用聚簇索引。
非聚簇索引:非聚簇索引的順序不影響數(shù)據(jù)的物理存儲順序的。如果說聚簇索引是一本詞典的a-z排序方式(物理存儲方式),那么非聚簇索引就是詞典后面的各種附錄索引。不同的附錄索引里的關鍵字排序是不一樣的,但是可以根據(jù)這個索引快速定位到單詞所在的頁數(shù)(物理位置)。其查詢速度沒有聚簇索引快,但是在一定程序上可以提高查詢效率。一張表最多可以創(chuàng)建249個非聚簇索引,每個非聚簇索引都需要進行索引頁的存儲。因為它占用很多空間的,所以非聚簇索引并不是越多越好。
三、唯一索引
唯一索引:一種特殊的索引,不允許索引值重復。也就是指定的索引列,不能出現(xiàn)重復的值,有點類似主鍵。創(chuàng)建該索引時,DBMS會檢查是否有重復的索引值,如果有會報錯,創(chuàng)建索引失敗。索引創(chuàng)建后,會在每次使用 或 語句添加數(shù)據(jù)時進行檢查。
四、索引的創(chuàng)建
數(shù)據(jù)庫創(chuàng)建索引需要有唯一的名字,指明索引名和索引列,且索引名不可與表名重復。
以MySQL的創(chuàng)建索引為例
聚簇索引創(chuàng)建語句:
index []
on [] ([], [], ...)
非聚簇索引創(chuàng)建語句:
index []
on []([], [],...)
聚簇唯一索引創(chuàng)建語句:
index []
on []([], [],...)
非聚簇唯一索引創(chuàng)建語句:
index []
on []([], [],...)
五、索引的使用規(guī)則
1、小數(shù)據(jù)的表不需要創(chuàng)建索引,因為沒啥卵用,這并不能提高查詢效率。
2、用戶查詢的字段數(shù)據(jù)有很多數(shù)值或者很多NULL時,創(chuàng)建索引可以提高查詢效率。
3、查詢返回的數(shù)據(jù)結果行少于總量的25%,索引可顯著提高查詢效率;反之,索引的作用就不大了。
4、索引列必須在where中頻繁使用,或者是order by用到的列,否則其作用就不大。
5、初始化表數(shù)據(jù)時,先裝入數(shù)據(jù),后創(chuàng)建索引。否則,每加一條數(shù)據(jù)都要更新索引,開銷大。
6、索引提高了檢索速度,降低了數(shù)據(jù)的更新速度。對表進行大量寫入和更新時,建議先移除索引,再創(chuàng)建索引,可節(jié)省時間,提高效率。所以索引不是越多越好。
7、索引會占用數(shù)據(jù)庫空間,設計數(shù)據(jù)庫時需要考慮其大小。
8、表和其索引盡量存儲于不同的磁盤上,可提高查詢速度。這個涉及到硬盤數(shù)據(jù)的讀取原理。
六、數(shù)據(jù)庫索引失效情況Last on 2018/07/07, to be ...
1、沒有查詢條件,或者查詢條件沒有建立索引(廢話)
2、在查詢條件上沒有引導列(廢話)
3、查詢條件中,使用函數(shù)在索引列上,或者對索引列進行運算(+,-,*,/,!)
錯誤: * from user where id/3 > 1000
正確: * from user where id > 3000
4、like中包含前模糊匹配的會失效
有效:
* from user where name like '';
* from user where name like '%';
* from user where name like '%';
* from user where name like '%';
* from user where name like '%';
查詢效率依次降低,所以說查詢信息越精確越好
失效:
* from user where name like '%';
* from user where name like '%%';
5、查詢條件中沒有引用組合索引中第一位置的索引列
特別說明:如果創(chuàng)建的索引是(name,city,sex),那么where city = 'YYY' and name = 'XXX'的效率和where name = 'XXX' and city = 'YYY'是一樣的,因為MySQL優(yōu)化器會自動調整查詢條件的先后順序,以匹配最適應的索引進行查詢。但是where city = 'YYY' and sex = '1'就不能發(fā)揮索引的作用了。
擴展:sex這一列值比較單一,就是0和1,所以它上面建立索引效率提示不大哦~
6、字符型的字段mysql數(shù)據(jù)庫索引有哪些,查詢內容為數(shù)字時,不加引號
7、in, not in使用要慎重,連續(xù)范圍查詢區(qū)間
(1) 可以用 and就不要用in
num from a where num in(1,2,3,4,5)
改為
num from a where num 1 and 5
(2) 有的時候可以用來優(yōu)化in,比如
num from a where num in( num from b)
改為:
num from a where ( 1 from b where num=a.num)
8、表字段為time類型,而查詢條件內容為date類型,或者相反情況
9、不建議在where中進行is null和is not null請慎用,.6.21上,is null是有效果的,is not null是全表掃描,個人猜測速度和表內null所占比例有關。
10、where查詢子句中有!=,都會促使引擎放棄索引,使用全表掃描
11、where查詢條件中使用or連接條件,會促使引擎放棄索引,使用全表掃描,可以用union all聯(lián)結查詢結果
12、where查詢中使用參數(shù),會促使引擎放棄索引,使用全表掃描。因為SQL只有在運行時才會解析局部變量,但優(yōu)化程序不能將訪問計劃的選擇推遲到運行時;它必須在編譯時進行選擇。然而,如果在編譯時建立訪問計劃,變量的值還是未知的,因而無法作為索引選擇的輸入項。
如下面語句將進行全表掃描: id from t where num=@num
可以改為強制查詢使用索引: id from t with(index(索引名)) where num=@num
MySQL優(yōu)化索引查詢,可參見以下博客: