筆者使用Spark已超過一年,現在公司大部分的批處理任務和機器學習任務都運行在Spark平臺之上,已經成為歷史。目前生產環境剛從Spark 1.4.1升級到最新版Spark 1.6.1,使用Yarn來調度和管理資源。本文將從升級到Spark 1.6過程當中遇到的若干問題和大家分享,我也會指出目前Spark存在的問題,希望引起重視。
內存問題
集合內存溢出
這個問題的具體錯誤信息: to 163 bytes of , got 0。這個是Spark在申請不到運行內存的時候主動拋出來的,在處理大數據量的場景下很容易復現。在Spark 1.6,默認的仍然是Sort方式頁面數據加載出錯是怎么回事,實際上是-sort和sort合并之后的版本,為了詳細闡述這個問題產生的根源,先回顧一下-sort的流程(如圖1所示)。
圖1 -sort的流程
的key和value會以二進制的格式存儲寫入到m當中,用二進制形式存儲的好處是可以減少序列化和反序列化的時間。然后判斷當前Page是否有足夠的內存,如果有足夠的空間就寫入到當前Page(注:Page是一塊連續的內存)。寫入Page之后,會把內存地址和編碼成一個8字節的長整形記錄在當中。當前Page或者內存不夠的時候會去申請內存,如果內存不夠就要把當前數據Spill到磁盤了,如果還是申請不到內存就會報該。
為什么Spill都無法釋放內存呢?通過添加日志信息的方式,發現了有一個對象申請了很多內存,但是卻不登記姓名,屬于黑戶一般的存在。
于是在社區發現了這個issue:SPARK-11293。明明發現了問題卻不解決,讓人很無奈。
之前使用的Spark 1.4版本也存在該問題,只是沒有主動拋錯誤,最后演變成。的具體實現有p和,它們主要負責做聚合和排序。雖然自身也有Spill機制,但它的Spill不是必須的,有非常大的概率會把所有的數據保存在內存當中,等遍歷完集合里面的所有數據,才會釋放內存。在不修改代碼的情況下,有兩種方式可以減少它發生的概率:
增加出錯階段的數,在數據分布比較均勻的情況下,可以減少每個Task處理的平均數據量。
設置spark..spill.,該參數主要用于測試,因為單元測試的時候可以明確知道寫了幾條測試數據。它的默認值是Long.,當插入的數據條數超過了這個閾值之后,就會強行把數據寫入到磁盤。
這兩種方法都存在比較明顯的缺陷,第一種方式不適用于數據傾斜的場景,第二種方式用戶很難明確的知道自己設置多少才可以,調大了沒作用,調小了會產生大量的磁盤I/O開銷,需要反復不斷嘗試。如果第二種方式換成內存的大小就比較直觀了,而且可以設置成默認的參數,這種修改方式最簡單,修改的代碼總共不超過10行。
修改方式如下:

修改接口,使它繼承自對象,合法申請內存,絕不走后門。
增加系統參數spark..spill.shold,默認值設置成640m,修改的方法,當超過閾值時把數據spill到磁盤。
存儲內存占用運行內存
在Spark 1.6之前,內存分為存儲內存和運行內存,兩者之間不能相互借用,在任務不進行緩存的情況下,存儲內存等于是浪費了。Spark 1.6推出了統一內存管理( ),默認情況下-的75%會拿出來供存儲內存和運行內存使用(各占一半),存儲內存和運行內存可以相互借用,避免了浪費的情況,有效的提高了內存的使用率。
聽起來是挺好的,但是運行任務的時候發現了一個問題:存儲內存把所有內存占完了,的時候它再慢慢從內存中剔除,多浪費了一次加載和剔除的時間。
為什么會發生這種情況呢?因為Cache操作發生在操作之前,這個時候運行內存是空閑的,它就順勢把運行內存給占完了,等進行操作的時候,已無內存可用,只能要求存儲內存歸還。
為了避免這種狀況,可對策略稍微做一下修改:存儲內存不能借用運行內存,運行內存可以借用空閑的存儲內存。
具體修改在類當中:
設置參數spark..on。
修改函數,該值會影響在Job UI上顯示的最大內存。
def : Long = {
if (ry) {
} else {
- yPool.
}
}
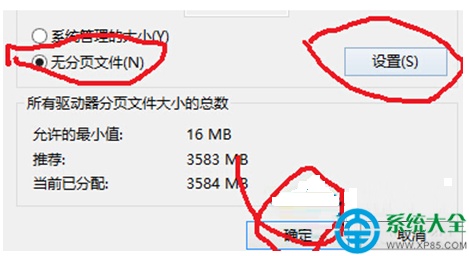
3 . 修改函數,增加以下的代碼,修改的值。
if (ry &&
( - .) <
yPool.) {
= - .
}
死鎖問題

該問題多發生在Cache數據比較多,存儲內存不夠用的場景下。用命令打印線程信息直接顯示出來,具體的信息請看這個issue: SPARK-13566。
該問題的起因是緩存的數據塊Block缺乏讀寫鎖,當內存不夠的時候,清理變量的線程和 Task的線程剔除Block同時選中了一個Block,并且相互鎖定了對方需要的對象。先鎖定了,然后請求該, Task先鎖定了,然后要在內存中刪除該Block的時候需要鎖定,非常典型的死鎖。
在JIRA開了一個issue之后,大神回復說在Spark 2.0會添加對Block的讀寫鎖保護頁面數據加載出錯是怎么回事,但是該PR修改非常多,很難應用在Spark 1.6當中,可是該問題非常嚴重,需要cache的數據比內存大的時候很容易復現。臨時的一種解決方法如下:
在當中添加一個全局的[, Long]來記錄鎖定該Block的任務ID;在鎖定之前記錄,訪問完刪除記錄。
鎖定之前都要先判斷是否在該當中已存在,如果已存在,函數退出。
考慮到任務可能失敗的可能性,在任務結束之后釋放跟該任務ID相關的所有鎖。
詳細的代碼可以查看該issue當中的PR。
使用超額的內存被Yarn給Kill掉
相信在Yarn上跑過Spark程序的朋友都會碰到過這個問題: usage: 12.1 GB of 12 GB used; 13.9 GB of 48 GB used. 。
在同樣的參數下,在Spark 1.4上正常運行的程序,在Spark 1.6上運行很容易出現這個問題。Spark在向Yarn申請內存的時候,一共申請了(內存 + 額外內存),額外內存默認是內存的10%,最小是384M。在大多數情況下,10%的額外內存已經是不夠的了,很容易被Yarn殺死。筆者嘗試過把參數spark..io.設置為false,禁止Netty使用堆外內存,也嘗試過把參數spark..設置成0.6甚至更小,但是沒有任何作用。
該問題出現頻率非常高,通過設置參數spark.yarn..可以解決,但設置多少合適呢,讓用戶自己去設置?用戶知道的參數應該越少越好,可以把精力放在業務代碼的實現上。按照比例去設置更合理一些,畢竟不能保證所有人都不會去更改默認配置。于是修改代碼,把該參數變成可通過比例去設置。當該比例設置成20%的時候,超過限制的情況減少,少數情況還是會超,但是不會導致整個任務失敗。該問題也發生在階段,通過增加數的方法可以減少。
希望Spark的開發者能夠重視這個問題,嚴格地控制堆外內存的使用。把內存的設置分成內存+額外內存也是Spark的獨創做法,就好比收完了房租,還要加收一筆垃圾處理費一樣。這是一種對內存使用估計不準確的無奈舉措,一直標榜自身是內存計算框架,卻不能很好的限制內存的使用。期待Spark有一天可以像、Samza這些框架設置了多少就是多少。
其他細節吐槽
UI的若干問題
在Spark 1.3以及之前版本的主頁上,列表都是顯示的機器名,從Spark 1.4之后就改成顯示IP列表了,讓人非常無奈。偶爾有臺機器掛了,如何從茫茫的IP海中搜索出來這臺“失聯的MH370”呢?如果它可以像Yarn一樣顯示Dead的節點也很好處理,可惜沒有。
在主頁列表居然放在最上面,試想一下每次打開頁面都要越過幾百臺節點才能看到 的列表是一種什么樣的感受。
執行了SQL之后,在Job UI會看到一個SQL的Tab頁,可是有的程序執行之后看到了不只一個,SQL1、SQL2…… 而且這些界面什么數據都沒有。查看了源代碼,發現它有這個遞增的機制。可以關注一下SPARK-11206,把這個issue的PR合并到1.6的分支可以解決多個SQL Tab頁的問題,但是在某些程序上仍然沒辦法正確顯示SQL Tab頁的內容。
煩人的提示信息
Spark-sql啟動的時候總會顯示一堆set spark.hive.=1.2.1的信息,重點還不僅僅是煩人,用spark-sql –e或者spark-sql –f 執行SQL完畢之后,它會把這些信息和結果輸出在一起。通過查看源代碼,這些信息輸出到標準輸出流。向Spark社區提過issue,直到現在都無人處理。該代碼位于文件的508行,只需要把state.out改成state.err就行。
不讓轉正就罷工
偶爾掛掉會引發個別的Task fail,該問題雖然不會殺死任務,但是總有人問這個錯誤怎么回事?Spark代碼里面異常退出采用.exit(1)的方式,因此從端看到的信息是org...util.Shell$。沒人看懂這個提示,被用戶問得實在沒辦法了,登陸到服務器上看輸出的錯誤信息,發現 but was null的錯誤提示信息。查了一下JIRA,發現有個類似的issue:SPARK-13112。報錯在以下的位置:
case (data) =>
if ( == null) {
(" but was null")
.exit(1)
原因是接收到發過來的任務,但是并沒有完成初始化。
是在什么時候完成初始化呢?它是在接收到的注冊成功的消息之后才會。那這里就有個疑問了,為什么要等收到的注冊成功消息了之后才去初始化呢?當收到的執行任務的消息,說明已經注冊成功了。發送消息是異步的,那就有可能先收到執行任務的消息再收到注冊成功的消息。
在求助社區無果后,于是改了兩行代碼,先實例化好再去注冊,該問題解決。
Spark SQL的喜與憂
先說喜吧,測試了一下用戶提供的幾組SQL語句,Spark 1.6比Spark 1.4有20%以上的性能提升!
憂的是在語法兼容性上沒有大的改觀,錯誤提示依舊難以看懂。很快就發現了一個類型轉換的問題:SPARK-13772。測試的時候發現:if語句不能同時存在和兩種不同類型,否則就會報錯。該語句在Spark 1.4上是正常的。查看源代碼之后發現它是在匹配的時候使用了錯誤的函數導致的,詳細代碼可查看issue里包含的PR。
結束語
從Spark 1.4升級到Spark 1.6,性能提升很明顯,用戶普遍反映任務運行速度變快了。碰到的問題也很多,尤其是內存方面,截止至最新發布的Spark 1.6.1,上述問題都沒有解決,有類似問題的請參照我提供的方法或者issue里的PR自行解決。
Spark正在朝著精細化管理內存的方向發展,內存管理這個部分的代碼改動非常大,從目前的情況來看,是處于失控的狀態的,突出的兩個問題表現為:
內存申請的邏輯存在明顯缺陷,體現在內存不足時無法通過spill機制來釋放,只能啟動自殺的方式來結束任務。內存消費者A在內存不足時不能要求消費者B釋放,只能通過把數據寫到磁盤的方式來釋放,原因是所有內存消費者的spill函數里都有一段檢查代碼,防止別的內存消費者觸發自身的spill函數。即使內存消費者A釋放了內存,它也不一定能申請到,它還需要受到任務可使用最大內存的限制(最大可使用內存=運行內存/運行的任務數)。
堆外內存的使用處于無監管狀態,目前只能靠加內存的方式來避免問題。從代碼上看,社區是有對通過分配的堆外內存進行管理的計劃,只是目前該部分工作還沒有完成。
作者簡介:岑玉海,滴滴出行數據架構工程師,專注于分布式存儲和分布式計算。
責編:仲浩()