

ETL構建數據倉庫五步法在數據倉庫構建中疋TL貫穿于項目始終尼是整個數據倉庫的生命線包括了從數據清洗,整合,到轉換,加載等的各個過程,如果說數據倉庫是一座大廈,那么ETL就是大廈的根基,ETL抽取整合數據的好壞直接影響到最終的結果展現。所以ETL在整個數據倉庫項目中起著十分關鍵的作用,必須擺到十分重要的位置。一、什么是是數據抽取()、轉換()、加載(Load)的簡寫,它是將OLTP系統中的數據經過抽取,并將不同數據源的數據進行轉換、整合,得出一致性的數據,然后加載到數據倉庫中。簡而言之ETL是完成從OLTP系統到OLAP系統的過程(圖一:pic1.jpg)。二、數據倉庫的架構數據倉庫('DW)是基于OLTP系統的數據源,為了便于多維分析和多角度展現將其數據按特定的模式進行存儲而建立的關系型數據庫,它不同于多維數據庫,數據倉庫中的數據是細節的,集成的,數據倉庫是面向主題的,是以OLAP系統為分析目的。它包括星型架構(圖二:pic2.jpg)與雪花型架構(圖三:pic3.jpg),其中星型架構中間為事實表關于同志近三年現實表現材料材料類招標技術評分表圖表與交易pdf視力表打印pdf用圖表說話 pdf,四周為維度表,類似星星;雪花型架構中間為事實表,兩邊的維度表可以再有其關聯子表,而在星型中只允許一張表作為維度表與事實表關聯,雪花型一維度可以有多張表,而星型不可以。
考慮到效率時,星型聚合快,效率高,不過雪花型結構明確,便于與OLTP系統交互。在實際項目中,我們將綜合運用星型架構與雪花型架構。三、ETL構建企業級數據倉庫五步法的流程(一)、確定主題即確定數據分析或前端展現的某一方面的分析主題,例如我們分析某年某月某一地區的啤酒銷售情況,就是一個主題。主題要體現某一方面的各分析角度(維度)和統計數值型數據(量度),確定主題時要綜合考慮,一個主題在數據倉庫中即為一個數據集市,數據集市體現了某一方面的信息,多個數據集市構成了數據倉庫。(二)、確定量度在確定了主題以后,我們將考慮要分析的技術指標,諸如年銷售額此類,一般為數值型數據,或者將該數據匯總,或者將該數據取次數,獨立次數或取最大最小值等,這樣的數據稱之為量度。量度是要統計的指標,必須事先選擇恰當,基于不同的量度可以進行復雜關鍵性能指標(KPI)等的計算。(三)、確定事實數據粒度在確定了量度之后我們要考慮到該量度的匯總情況和不同維度下量度的聚合情況,考慮到量度的聚合程度不同,我們將采用“最小粒度原則”,即將量度的粒度設置到最小,例如我們將按照時間對銷售額進行匯總,目前的數據最小記錄到天,即數據庫中記錄了每天的交易額,那么我們不能在ETL時將數據進行按月或年匯總,需要保持到天,以便于后續對天進行分析。
而且我們不必擔心數據量和數據沒有提前匯總帶來的問題,因為在后續的建立CUBE時已經將數據提前匯總了。(四)、確定維度維度是要分析的各個角度,例如我們希望按照時間,或者按照地區,或者按照產品進行分析,那么這里的時間、地區、產品就是相應的維度,基于不同的維度我們可以看到各量度的匯總情況,我們可以基于所有的維度進行交叉分析。這里我們首先要確定維度的層次()和級別(Level)(圖四:pic4.jpg),維度的層次是指該維度的所有級別,包括各級別的屬性;維度的級別是指該維度下的成員,例如當建立地區維度時我們將地區維度作為一個級別,層次為省、市、縣三層,考慮到維度表要包含盡量多的信息,所以建立維度時要符合“矮胖原則”,即維度表要盡量寬,盡量包含所有的描述性信息,而不是統計性的數據信息。還有一種常見的情況,就是父子型維度(圖五:pic5.jpg),該維度一般用于非葉子節點含有成員等情況,例如公司員工的維度,在統計員工的工資時,部門主管的工資不能等于下屬成員工資的簡單相加,必須對該主管的工資單獨統計,然后該主管部門的工資等于下屬員工工資加部門主管的工資,那么在建立員工維度時,我們需要將員工維度建立成父子型維度,這樣在統計時,主管的工資會自動加上,避免了都是葉子節點才有數據的情況。
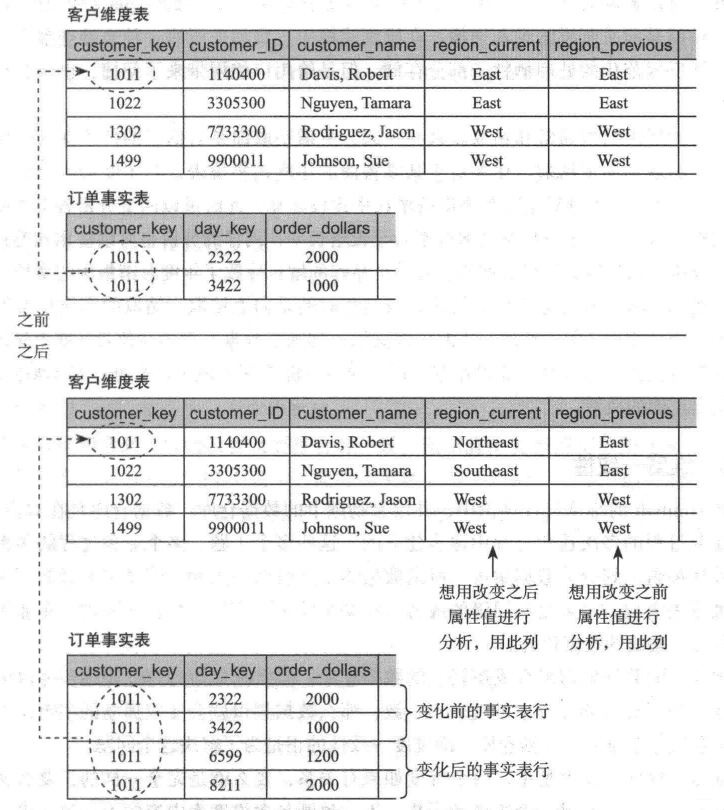
另外,在建立維度表時要充分使用代理鍵,代理鍵是數值型的ID號碼,好處是代理鍵唯一標識了每一維度成員信息,便于區分,更重要的是在聚合時由于數值型匹配,JOIN效率高,便于聚合,而且代理鍵對緩慢變化維度有更重要的意義,它起到了標識歷史數據與新數據的作用,在原數據主鍵相同的情況下,代理鍵起到了對新數據與歷史數據非常重要的標識作用。有時我們也會遇到維度緩慢變化的情況,比如增加了新的產品,或者產品的ID號碼修改了,或者產品增加了一個新的屬性,此時某一維度的成員會隨著新的數據的加入而增加新的維度成員,這樣我們要考慮到緩慢變化維度的處理,對于緩慢變化維度,有三種情況:1、緩慢變化維度第一種類型:歷史數據需要修改。這樣新來的數據要改寫歷史數據,這時我們要使用,例如產品的ID號碼為123,后來發現ID號碼錯誤了,需要改寫成456,那么在修改好的新數據插入時,維度表中原來的ID號碼會相應改為456,這樣在維度加載時要使用第一種類型,做法是完全更改。2、緩慢變化維度第二種類型:歷史數據保留,新增數據也要保留。這時要將原數據更新,將新數據插入,需要使用/,比如某一員工2005年在A部門,2006年時他調到了B部門。
那么在統計2005年的數據時就應該將該員工定位到A部門;而在統計2006年數據時就應該定位到B部門,然后再有新的數據插入時,將按照新部門(B部門)進行處理,這樣我們的做法是將該維度成員列表加入標識列,將歷史的數據標識為“過期”,將目前的數據標識為“當前的”。另一種方法是將該維度打上時間戳,即將歷史數據生效的時間段作為它的一個屬性,在與原始表匹配生成事實表時將按照時間段進行關聯,這樣的好處是該維度成員生效時間明確。3、緩慢變化維度第三種類型:新增數據維度成員改變了屬性。例如某一維度成員新加入了一列,該列在歷史數據中不能基于它瀏覽,而在目前數據和將來數據中可以按照它瀏覽,那么此時我們需要改變維度表屬性,即加入新的列,那么我們將使用存儲過程或程序生成新的維度屬性,在后續的數據中將基于新的屬性進行查看。(五)、創建事實表在確定好事實數據和維度后,我們將考慮加載事實表。在公司的大量數據堆積如山時,我們想看看里面究竟是什么,結果發現里面是一筆筆生產記錄,一筆筆交易記錄…那么這些記錄是我們將要建立的事實表的原始數據點卩關于某一主題的事實記錄表。我們的做法是將原始表與維度表進行關聯,生成事實表(圖六:pic6.jpg)。
注意在關聯時有為空的數據時(數據源臟),需要使用外連接,連接后我們將各維度的代理鍵取出放于事實表中,事實表除了各維度代理鍵外,還有各量度數據,這將來自原始表,事實表中將存在維度代理鍵和各量度,而不應該存在描述性信息,卩符合“瘦高原則”,卩要求事實表數據條數盡量多(粒度最小),而描述性信息盡量少。如果考慮到擴展,可以將事實表加一唯一標識列,以為了以后擴展將該事實作為雪花型維度,不過不需要時一般建議不用這樣做。事實數據表是數據倉庫的核心,需要精心維護,在JOIN后將得到事實數據表,一般記錄條數都比較大,我們需要為其設置復合主鍵和索引,以為了數據的完整性和基于數據倉庫的查詢性能優化,事實數據表與維度表一起放于數據倉庫中,如果前端需要連接數據倉庫進行查詢,我們還需要建立一些相關的中間匯總表或物化視圖,以方便查詢。三、ETL中高級技巧的運用(一)、準備區的運用在構建數據倉庫時,如果數據源位于一服務器上數據倉庫有幾種etl算法,數據倉庫在另一服務器端,考慮到數據源端訪問頻繁,并且數據量大,需要不斷更新,所以可以建立準備區數據庫(圖七:pic7.jpg)。先將數據抽取到準備區中,然后基于準備區中的數據進行處理,這樣處理的好處是防止了在原OLTP系統中中頻繁訪問,進行數據運算或排序等操作。
例如我們可以按照天將數據抽取到準備區中,基于數據準備區,我們將進行數據的轉換,整合,將不同數據源的數據進行一致性處理。數據準備區中將存在原始抽取表,一些轉換中間表和臨時表以及ETL日志表等。(二)、時間戳的運用時間維度對于某一事實主題來說十分重要,因為不同的時間有不同的統計數據信息,那么按照時間記錄的信息將發揮很重要的作用。在ETL中,時間戳有其特殊的作用,在上面提到的緩慢變化維度中,我們可以使用時間戳標識維度成員;在記錄數據庫和數據倉庫的操作時,我們也將使用時間戳標識信息,例如在進行數據抽取時,我們將按照時間戳對OLTP系統中的數據進行抽取,比如在午夜0:00取前一天的數據,我們將按照OLTP系統中的時間戳取到減一天,這樣得到前一天數據。(三)、日志表的運用在對數據進行處理時,難免會發生數據處理錯誤,產生出錯信息,那么我們如何獲得出錯信息并及時修正呢?方法是我們使用一張或多張Log日志表,將出錯信息記錄下來,在日志表中我們將記錄每次抽取的條數,處理成功的條數,處理失敗的條數,處理失敗的數據,處理時間等等,這樣當數據發生錯誤時,我們很容易發現問題所在,然后對出錯的數據進行修正或重新處理。
四)、使用調度在對數據倉庫進行增量更新時必須使用調度(圖八:pic8.jpg),即對事實數據表進行增量更新處理,在使用調度前要考慮到事實數據量,需要多長時間更新一次,比如希望按天進行查看,那么我們最好按天進行抽取,如果數據量不大,可以按照月或半年對數據進行更新,如果有緩慢變化維度情況,調度時需要考慮到維度表更新情況,在更新事實數據表之前要先更新維度表。調度是數據倉庫的關鍵環節,要考慮縝密,在ETL的流程搭建好后,要定期對其運行,所以調度是執行ETL流程的關鍵步驟新產品開發流程的步驟課題研究的五個步驟成本核算步驟微型課題研究步驟數控銑床操作步驟每一次調度除了寫入Log日志表的數據處理信息外還要使用發送Email或報警信息等,這樣也方便的技術人員對ETL流程的把握,增強了安全性和數據處理的準確性。四、總結ETL構建數據倉庫需要簡單的五步,掌握了這五步的方法我們將構建一個強大的數據倉庫,不過每一步都有很深的需要研究與挖掘,尤其在實際項目中,我們要綜合考慮,例如如果數據源的臟數據很多,在搭建數據倉庫之前我們首先要進行數據清洗,以剔除掉不需要的信息和臟數據。總之,ETL是數據倉庫的核心,掌握了ETL構建數據倉庫的五步法,就掌握了搭建數據倉庫的根本方法。不過,我們不能教條,基于不同的項目,我們還將要進行具體分析,如父子型維度和緩慢變化維度的運用等。在數據倉庫構建中,ETL關系到整個項目的數據質量,所以馬虎不得數據倉庫有幾種etl算法,必須將其擺到重要位置,將ETL這一大廈根基筑牢!
