

python自然語言處理實戰
第五章 關鍵詞提取算法
中管方法分析:
1.有監督方法及語料庫技術
將關鍵詞抽取任務轉化為分類問題或標注問題。
有監督機器學習的分類方法主要借助決策樹、樸素貝葉斯、支持向量機、最大熵模型、隱馬爾可夫模型、條件隨機場等。
主要有兩個研究方向:
一個方向是將關鍵詞抽取看做是二分類任務;
另一個方向是基于語言模型。
優勢:通過大量文本訓練得到,相比于無監督的抽取方法得到的規則更加科學、有效,抽取的關鍵詞的質量有大幅度的提高。
缺陷:
(1)需要大量文本訓練,大規模人工標注的訓練預料難以獲取;
(2)抽取效果受訓練語料的規模和領域性影響較大,只要訓練集不同,構造的分類模型也會有差異,最終影響模型的準確性。
(3)訓練語料的質量往往會直接影響到模型的準確性,從而影響著關鍵詞抽取的結果。已標注關鍵詞的文本有限,
訓練集需要自己去標注,人工標注帶有一定的主觀因素,會造成實驗數據具有不真實性。
如何獲取一個高質量的訓練集合是此類算法的瓶頸問題。
所以有監督的自動關鍵詞抽取算法應用不是很廣泛。
大型語料庫逐漸轉變為大批小型的針對特定應用的語料庫構建。
2.半監督方法和無監督方法
不需要訓練語料,不需要人工參與,利用抽取系統完成關鍵詞抽取。
2.1 基于統計的方法: 僅僅是 文檔-詞維度
主流的簡單統計方法是TFIDF及其改進方法。
TFIDF是衡量一個詞對一篇文檔的區分程度。
利用文檔中詞語的統計信息抽取文檔的關鍵詞。
優點:簡單,易于實現,不需要訓練數據,也不需要構建外部知識庫,泛化性強。
考慮詞的位置、詞性和關聯信息特征。
比如在文本中名詞作為一種定義現實實體的詞,帶有更多的關鍵信息。
再比如在某些場景中文本的起始段落和結尾段落比其他部分更重要。
缺陷:
單純以詞頻衡量一個詞的重要性不夠全面,有時重要的詞可能出現的次數不多。
而且這種算法無法體現詞的位置、詞性和關聯信息等特征,更無法反映詞匯的語義信息。
****************************************************************
IDF本質上是一種試圖抑制噪音的加權。
單純的認為文檔頻率小的詞越重要,文檔頻率大的單詞就越無用。
這樣導致的問題是一些不能代表文本的低頻次IDF值很高;
有些能夠很好代表文本的高頻詞IDF值卻很高。
主要原因是TFIDF沒有考慮特征項在文檔集合類間和類內的分布情況。
沒有考慮語義。
*****************************************************************
2.2 基于主題的方法: 提升到文檔-主題-詞的維度
主要思想是:文檔是若干主題的分布;每個主題又是詞語的概率分布。
主題表示為一個方面,一個概念,表現為相關詞的集合。
主題模型是語義挖掘的核心。
LSA/LSI/LDA算法
最主要的主題模型是LDA 隱含狄利克雷分布
已知詞和文檔的對應關系,我們的目的是找出 主題的詞分布,文檔的主題分布。
主題模型的優點是:
(1) 可以獲得文本語義相似性的關系。根據主題模型可以得到主題的概率分布,可以通過概率分布計算文本之間的相似度。
(2) 可以解決多義詞的問題。
(3) 可以去除文檔中噪音的影響。
(4) 無監督、完全自動化。無需人工標注,可以直接通過模型得到概率分布。
(5) 語言無關。
2.3 基于網絡圖的方法
主流的基于網絡圖的算法的是算法
基于網絡圖的算法和上述算法不同的一點是,統計分析和基于主題的方法都需要基于一個現成的語料庫。
比如TF-IDF需要統計每個詞在語料庫中多少個文檔中出現過,也就是逆文檔頻率。
基于主題的模型需要通過大規模文檔的學習,來發現文檔的隱含主題。
算法可以脫離語料庫的背景,僅對單篇文檔進行分析就可以提取文檔的關鍵詞。
算法的基本思想來源于Google的算法。
算法是一種網頁排名算法。基本思想有兩條:
(1) 鏈接質量
(2) 鏈接數量
最開始將所有網頁的得分都設置為1,通過多次迭代來對每個網頁的分數進行收斂。
收斂時的分數就是網頁的最終得分。
是有向無權圖
原來的文本:
隨著知識經濟的快速發展。對專利文本的分析與研究可以幫助人們了解新技術,推測技術的發展方向。自動關鍵詞抽
取在中文專利文本的分析與研究中有著至關重要的意義。介紹一些目前已有的自動關鍵詞抽取技術成果,包括有監
督方法和無監督方法.并對關鍵詞抽取的評價指標做簡單的介紹。
使用jieba分詞然后去掉中的停止詞得到的分詞:
知識經濟/發展/專利/文本/分析/研究/幫助/人們/了解/技術/推測/技術/發展/方向
自動/關鍵詞/抽取/中文/專利/文本/分析/研究/有著/至關重要/意義
介紹/目前/已有/自動/關鍵詞/抽取/技術/成果/包括/監督/方法/無/
監督/方法/關鍵詞/抽取/評價/指標/做/介紹
人類語言是一種復雜網絡,具有復雜網絡的小世界特性與無標度特性。
語言網絡圖
詞匯選擇最根本的原因在于這些詞匯本身具有的含義能夠表達期望的內容。
基于復雜網絡的關鍵詞抽取是一種無監督方法。
在整個語言網絡圖上尋找起重要作用和中心作用的詞或短語,將這些詞抽取出來作為關鍵詞。
網絡圖的代表算法是基于應用于關鍵詞抽取領域的算法。
算法優點:
(1) 無需訓練數據,節省了大量成本;
(2) 適應性強。本身是無監督學習方法,具有很強的適應能力和擴展能力,對文本沒有主題方面的限制;
(3) 速度快,雖然是矩陣運算,但是收斂速度快。
4.關鍵詞抽取的評價
關鍵詞抽取的目標是選擇一組詞語,覆蓋文檔的主題。
關鍵詞抽取的評價主要有兩種形式:一種是單純借助人工的評價方式,由領域專家進行評價,
這種方式可操作性強但缺點也明顯,比如認識分歧、詞或短語的組合歧義等;
另一種是借鑒信息檢索模型中的評價指標,包括準確率、召回率、綜合指標F或F1來評價算法的準確性。
一些常用的無監督關鍵詞提取算法
TF-IDF算法、算法、主題模型算法(LSA、LSI、LDA等)
1.TF-IDF算法
需要一個現成的語料庫:需要統計每個詞在語料庫中的多少個文檔中出現過。
基于統計的計算方法
用于評估一個文檔集中某個詞對文檔的重要程度。
可解釋性很強:當一個詞對一個文檔越重要,那么它越可能是文檔的關鍵詞。
這里需要注意的是,越重要不一定越多。
TF-IDF算法 = TF*IDF
通過考慮詞性和位置可以提升算法。
通常名詞作為一種定義現實實體的詞帶有更多的關鍵信息;
本文的起始段落和結尾段落也會帶有更多的管建新。
和n-grams結合使用
2.算法
可以脫離語料庫,僅對單篇文檔進行分析就可以提取文檔的關鍵詞
最早用于文檔的自動摘要。
算法基本思想來源于Google的算法。
算法是一種網頁排名算法
基本思想是:考慮鏈接數量和鏈接質量。
鏈接分析算法:主要用來評價搜索系統覆蓋網頁重要性的一種方法。

是有向無權圖,進行自動摘要是有權圖。
3.LSA/LSI/LDA算法
這些是主題模型
TF-IDF算法和算法都是 詞-文檔維度的關系,存在的問題是不能獲取隱含信息
而主題模型的維度是詞-主題-文檔維度的關系。
3.1 LSA/LSI算法
LSA Latent 潛在語義分析
LSI Latent Index 潛在語義索引
LSA主要通過SVD奇異值分解,將詞、文檔映射到一個低緯的語義空間,挖掘出詞、文檔的
淺層語義信息,從而對詞、文檔進行更本質的表達。
核心是通過SVD暴力求解,簡單直接的求解出近似的word-topic-分布信息。
定位是初級的主題模型
缺點:
1.SVD計算復雜度高,特征空間維度較大的,計算效率十分低下
2.LSA得到的分布信息是基于已有數據集的,當新的文檔進入,需要對整個空間重新訓練
3.LSA對詞的頻率分布不敏感、物理解釋性薄弱
優化辦法是
pLSA
通過使用EM算法對分布信息進行擬合替代SVD進行暴力破解
3.2 LDA算法
主題模型的主流方法
LDA Latent 隱含狄利克雷分布
LDA算法假設文檔中主題的先驗分布和主題中詞的先驗分布都服從狄利克雷分布。
先驗分布+數據(似然)=后驗分布
4.深度學習
基于深度學習的實體關系抽取方法與經典抽取方法相比,主要優勢在于深度學習的神經網絡
可以自動學習句子特征,無需復雜的特征工程。
*************************************************************************************************************************************************
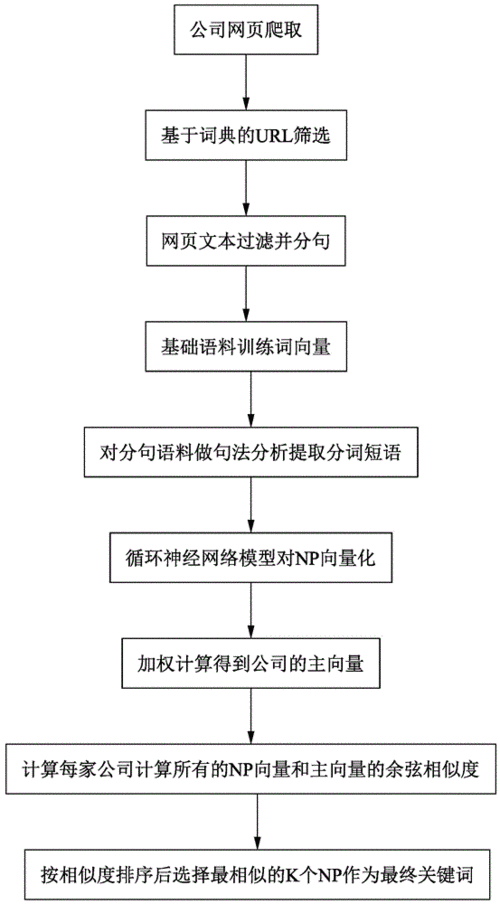
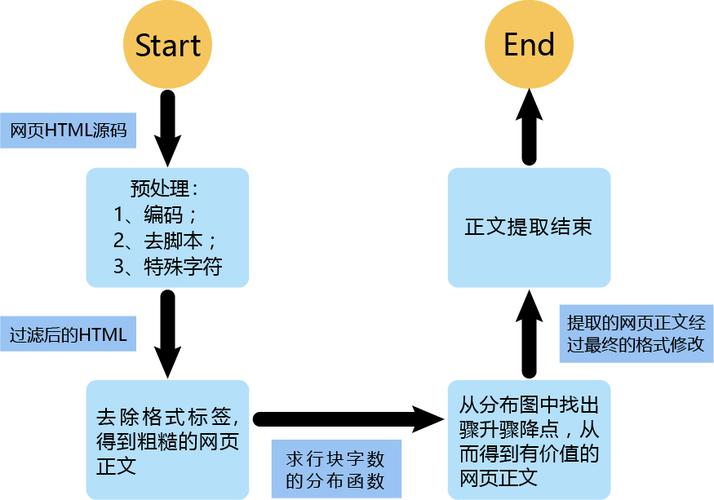
PPT里面添加一些自己在關鍵詞提取中做的一些嘗試
*************************************************************************************************************************************************
參考資料:
1.python自然語言處理實戰 第五章 關鍵詞提取 book
2.自動關鍵詞抽取研究綜述 趙京勝、朱巧明等 論文
3.An of Graph-Based Keyword Methods and
基于詞向量的文本分類推斷
這里可以在PPT上添加一頁