

在服務開發中,單機都會存在單點故障的問題,及服務部署在一臺服務器上,一旦服務器宕機服務就不可用,所以為了讓服務高可用,分布式服務就出現了,將同一服務部署到多臺機器上,即使其中幾臺服務器宕機,只要有一臺服務器可用服務就可用。
redis也是一樣,為了解決單機故障引入了主從模式,但主從模式存在一個問題:節點故障后服務,需要人為的手動將slave節點切換成為maser節點后服務才恢復。redis為解決這一問題又引入了哨兵模式,哨兵模式能在節點故障后能自動將salve節點提升成節點,不需要人工干預操作就能恢復服務可用。
但是主從模式、哨兵模式都沒有達到真正的數據存儲,每個redis實例中存儲的都是全量數據,所以redis 就誕生了,實現了真正的數據分片存儲。但是由于redis 發布得比較晚(2015年才發布正式版 ),各大廠等不及了,陸陸續續開發了自己的redis數據分片集群模式,比如:、Codis等。
1.主從模式
redis單節點雖然有通過RDB和AOF持久化機制能將數據持久化到硬盤上,但數據是存儲在一臺服務器上的,如果服務器出現硬盤故障等問題,會導致數據不可用,而且讀寫無法分離,讀寫都在同一臺服務器上,請求量大時會出現I/O瓶頸。
為了避免單點故障 和 讀寫不分離,Redis 提供了復制()功能實現數據庫中的數據更新后,會自動將更新的數據同步到其他slave數據庫上。
如上redis主從結構特點:一個可以有多個salve節點;salve節點可以有slave節點,從節點是級聯結構。
主從模式優缺點
優點: 主從結構具有讀寫分離,提高效率、數據備份,提供多個副本等優點。
不足: 最大的不足就是主從模式不具備自動容錯和恢復功能,主節點故障,集群則無法進行工作,可用性比較低,從節點升主節點需要人工手動干預。
普通的主從模式,當主數據庫崩潰時,需要手動切換從數據庫成為主數據庫:
在從數據庫中使用SLAVE NO ONE命令將從數據庫提升成主數據繼續服務。
啟動之前崩潰的主數據庫,然后使用命令將其設置成新的主數據庫的從數據庫,即可同步數據。
2.哨兵模式
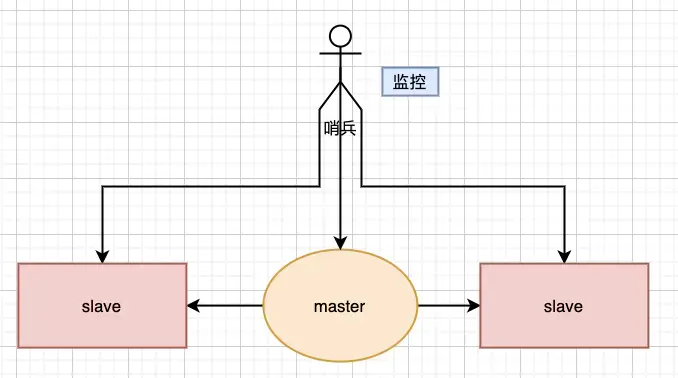
第一種主從同步/復制的模式,當主服務器宕機后,需要手動把一臺從服務器切換為主服務器,這就需要人工干預,費事費力,還會造成一段時間內服務不可用,這時候就需要哨兵模式登場了。
哨兵模式是從Redis的2.6版本開始提供的,但是當時這個版本的模式是不穩定的,直到Redis的2.8版本以后,這個哨兵模式才穩定下來。
哨兵模式核心還是主從復制,只不過在相對于主從模式在主節點宕機導致不可寫的情況下,多了一個競選機制:從所有的從節點競選出新的主節點。競選機制的實現,是依賴于在系統中啟動一個進程。
如上圖,哨兵本身也有單點故障的問題,所以在一個一主多從的Redis系統中,可以使用多個哨兵進行監控,哨兵不僅會監控主數據庫和從數據庫,哨兵之間也會相互監控。每一個哨兵都是一個獨立的進程,作為進程,它會獨立運行。
(1)哨兵模式的作用:
監控所有服務器是否正常運行:通過發送命令返回監控服務器的運行狀態,處理監控主服務器、從服務器外,哨兵之間也相互監控。
故障切換:當哨兵監測到宕機,會自動將slave切換成,然后通過發布訂閱模式通知其他的從服務器,修改配置文件,讓它們切換。同時那臺有問題的舊主也會變為新主的從,也就是說當舊的主即使恢復時,并不會恢復原來的主身份,而是作為新主的一個從。
(2)哨兵實現原理
哨兵在啟動進程時,會讀取配置文件的內容,通過如下的配置找出需要監控的主數據庫:
sentinel?monitor?master-name?ip?port?quorum
#master-name是主數據庫的名字
#ip和port?是當前主數據庫地址和端口號
#quorum表示在執行故障切換操作前,需要多少哨兵節點同意。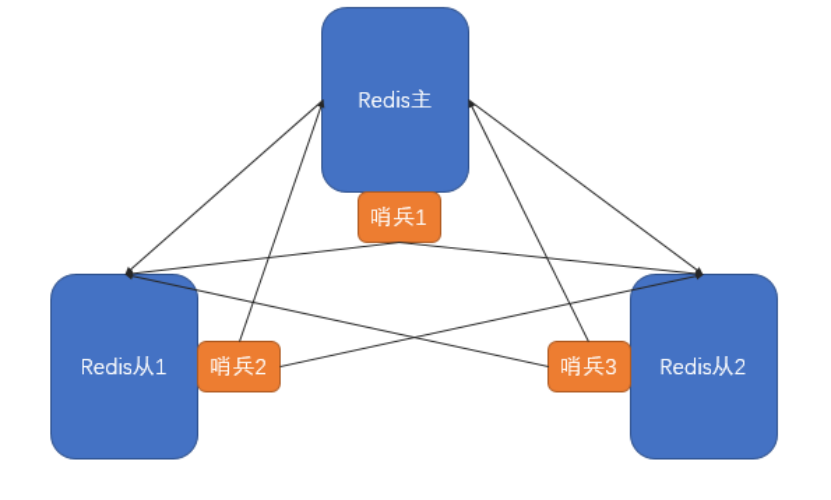
這里之所以只需要連接主節點,是因為通過主節點的info命令,獲取從節點信息,從而和從節點也建立連接,同時也能通過主節點的info信息知道新增從節點的信息。
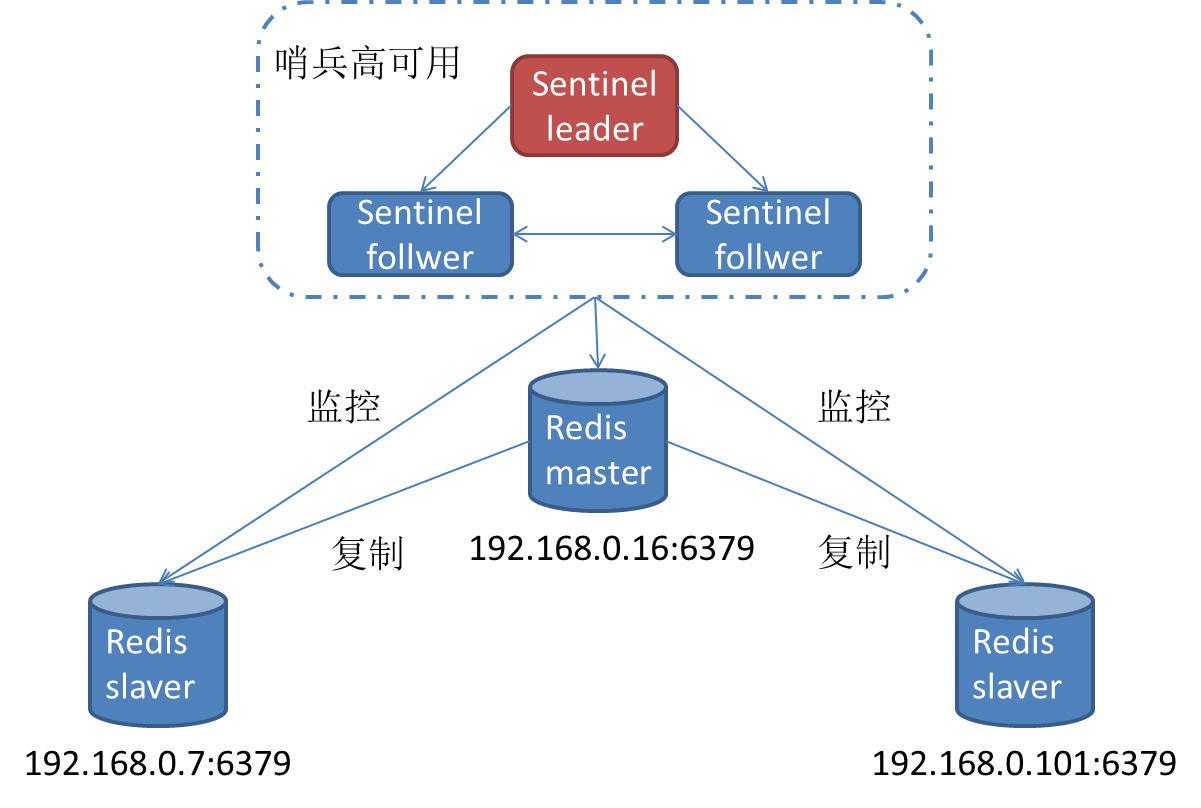
一個哨兵節點可以監控多個主節點,但是并不提倡這么做,因為當哨兵節點崩潰時,同時有多個集群切換會發生故障。哨兵啟動后,會與主數據庫建立兩條連接。
訂閱主數據庫:hello頻道以獲取同樣監控該數據庫的哨兵節點信息
定期向主數據庫發送info命令,獲取主數據庫本身的信息。
跟主數據庫建立連接后會定時執行以下三個操作:
(1)每隔10s向和 slave發送info命令。作用是獲取當前數據庫信息,比如發現新增從節點時,會建立連接,并加入到監控列表中,當主從數據庫的角色發生變化進行信息更新。
(2)每隔2s向主數據里和從數據庫的:hello頻道發送自己的信息。作用是將自己的監控數據和哨兵分享。每個哨兵會訂閱數據庫的:hello頻道,當其他哨兵收到消息后,會判斷該哨兵是不是新的哨兵,如果是則將其加入哨兵列表,并建立連接。
(3)每隔1s向所有主從節點和所有哨兵節點發送ping命令,作用是監控節點是否存活。
(3)主觀下線和客觀下線
哨兵節點發送ping命令時,當超過一定時間(down-after-)后,如果節點未回復,則哨兵認為主觀下線。主觀下線表示當前哨兵認為該節點已經下面,如果該節點為主數據庫,哨兵會進一步判斷是夠需要對其進行故障切換,這時候就要發送命令( is--down-by-addr)詢問其他哨兵節點是否認為該主節點是主觀下線,當達到指定數量()時,哨兵就會認為是客觀下線。
當主節點客觀下線時就需要進行主從切換,主從切換的步驟為:
選出一個從數據庫后,哨兵發送slave no one命令升級為主數據庫,并發送命令將其他從節點的主數據庫設置為新的主數據庫。
(4)哨兵模式優缺點
1.優點
2.不足-問題
主從模式或哨兵模式每個節點存儲的數據都是全量的數據,數據量過大時,就需要對存儲的數據進行分片后存儲到多個redis實例上。此時就要用到Redis 技術。
3.各大廠的Redis集群方案
Redis在3.0版本前只支持單實例模式,雖然Redis的開發者早在博客上就提出在Redis 3.0版本中加入集群的功能,但3.0版本等到2015年才發布正式版。各大企業等不急了,在3.0版本還沒發布前為了解決Redis的存儲瓶頸,紛紛推出了各自的Redis集群方案。這些方案的核心思想是把數據分片()存儲在多個Redis實例中,每一片就是一個Redis實例。
(1)客戶端分片
客戶端分片是把分片的邏輯放在Redis客戶端實現,(比如:jedis已支持Redis 功能,即),通過Redis客戶端預先定義好的路由規則(使用一致性哈希),把對Key的訪問轉發到不同的Redis實例中,查詢數據時把返回結果匯集。這種方案的模式如圖所示。
客戶端分片的優缺點:
優點:客戶端技術使用hash一致性算法分片的好處是所有的邏輯都是可控的,不依賴于第三方分布式中間件。服務端的Redis實例彼此獨立,相互無關聯,每個Redis實例像單服務器一樣運行,非常容易線性擴展,系統的靈活性很強。開發人員清楚怎么實現分片、路由的規則,不用擔心踩坑。
1.一致性哈希算法:
是分布式系統中常用的算法。比如,一個分布式的存儲系統,要將數據存儲到具體的節點上,如果采用普通的hash方法,將數據映射到具體的節點上,如mod(key,d),key是數據的key,d是機器節點數,如果有一個機器加入或退出這個集群,則所有的數據映射都無效了。
一致性哈希算法解決了普通余數Hash算法伸縮性差的問題,可以保證在上線、下線服務器的情況下盡量有多的請求命中原來路由到的服務器。
2.實現方式:一致性hash算法,比如散列算法、算法
比如Jedis的Redis 實現,采用一致性哈希算法( ),將key和節點name同時,然后進行映射匹配,采用的算法是。
采用一致性哈希而不是采用簡單類似哈希求模映射的主要原因是當增加或減少節點時,不會產生由于重新匹配造成的。一致性哈希只影響相鄰節點key分配,影響量小。
不足:
客戶端分片有一個最大的問題就是,服務端Redis實例群拓撲結構有變化時,每個客戶端都需要更新調整。如果能把客戶端分片模塊單獨拎出來,形成一個單獨的模塊(中間件),作為客戶端 和 服務端連接的橋梁就能解決這個問題了,此時代理分片就出現了。
(2)代理分片
redis代理分片用得最多的就是,由開源的Redis代理,其基本原理是:通過中間件的形式,Redis客戶端把請求發送到,根據路由規則發送到正確的Redis實例,最后把結果匯集返回給客戶端。
通過引入一個代理層,將多個Redis實例進行統一管理,使Redis客戶端只需要在上進行操作,而不需要關心后面有多少個Redis實例,從而實現了Redis集群。
的優點: 的不足:
作為最被廣泛使用、最久經考驗、穩定性最高的Redis代理,在業界被廣泛使用。
(3)Codis
不能平滑增加Redis實例的問題帶來了很大的不便,于是豌豆莢自主研發了Codis,一個支持平滑增加Redis實例的Redis代理軟件,其基于Go和C語言開發,并于2014年11月在上開源。
在Codis的架構圖中,Codis引入了Redis Group,其通過指定一個主和一個或多個從,實現了Redis集群的高可用。當一個主掛掉時,Codis不會自動把一個從提升為主,這涉及數據的一致性問題(Redis本身的數據同步是采用主從異步復制,當數據在主寫入成功時,從是否已讀入這個數據是沒法保證的),需要管理員在管理界面上手動把從提升為主。
如果手動處理覺得麻煩redis集群數據一致性,豌豆莢也提供了一個工具Codis-ha,這個工具會在檢測到主掛掉的時候將其下線并提升一個從為主。
Codis中采用預分片的形式,啟動的時候就創建了1024個slot,1個slot相當于1個箱子,每個箱子有固定的編號,范圍是1~1024。slot這個箱子用作存放Key,至于Key存放到哪個箱子,可以通過算法“crc32(key)24”獲得一個數字,這個數字的范圍一定是1~1024之間,Key就放到這個數字對應的slot。
例如,如果某個Key通過算法“crc32(key)24”得到的數字是5,就放到編碼為5的slot(箱子)。1個slot只能放1個Redis Group,不能把1個slot放到多個Redis Group中。1個Redis Group最少可以存放1個slot,最大可以存放1024個slot。因此,Codis中最多可以指定1024個Redis Group。
Codis最大的優勢在于支持平滑增加(減少)Redis Group(Redis實例),能安全、透明地遷移數據,這也是Codis 有別于等靜態分布式 Redis 解決方案的地方。Codis增加了Redis Group后,就牽涉到slot的遷移問題。

例如,系統有兩個Redis Group,Redis Group和slot的對應關系如下。
當增加了一個Redis Group,slot就要重新分配了。Codis分配slot有兩種方法:
第一種:通過Codis管理工具手動重新分配,指定每個Redis Group所對應的slot的范圍,例如:可以指定Redis Group和slot的新的對應關系如下。
第二種:通過Codis管理工具的功能,會自動根據每個Redis Group的內存對slot進行遷移,以實現數據的均衡。
4.Redis
Redis 的哨兵模式雖然已經可以實現高可用,讀寫分離 ,但是存在幾個方面的不足:
redis在3.0上加入了 集群模式,實現了 Redis 的分布式存儲,也就是說每臺 Redis 節點上存儲不同的數據。模式為了解決單機Redis容量有限的問題,將數據按一定的規則分配到多臺機器,內存/QPS不受限于單機redis集群數據一致性,可受益于分布式集群高擴展性。
Redis 是一種服務器技術(分片和路由都是在服務端實現),采用多主多從,每一個分區都是由一個Redis主機和多個從機組成,片區和片區之間是相互平行的。Redis 集群采用了P2P的模式,完全去中心化。
如上圖,官方推薦,集群部署至少要 3 臺以上的節點,最好使用 3 主 3 從六個節點的模式。Redis 集群具有如下幾個特點:
redis 主要是針對海量數據+高并發+高可用的場景,海量數據,如果你的數據量很大,那么建議就用redis ,數據量不是很大時,使用就夠了。redis 的性能和高可用性均優于哨兵模式。
Redis 采用虛擬哈希槽分區而非一致性hash算法,預先分配一些卡槽,所有的鍵根據哈希函數映射到這些槽內,每一個分區內的節點負責維護一部分槽以及槽所映射的鍵值數據。
版權聲明:本文為CSDN博主「有鹽先生」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。