

三、文本挖掘所需工具
本次文本挖掘將使用R語言實現,除此還需加載幾個R包,它們是tm包、tmcn包、包和包。其中tmcn包和包無法在CRAN鏡像中下載到,有關這兩個包的下載方法可參見下文>>>
四、實戰
本文所用數據集來自于實驗室數據,具體可至鏈接下載>>>
本文對該數據集做了整合,將各個主題下的新聞匯總到一張csv表格中,數據格式如下圖所示:
手把手教你做文本挖掘
具體數據可至文章后面的鏈接。
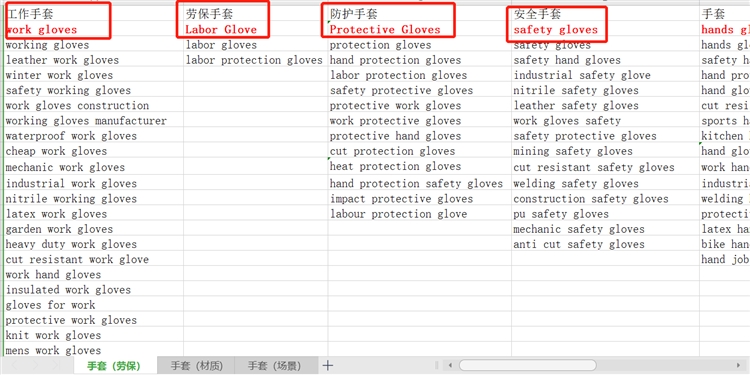
手把手教你做文本挖掘
手把手教你做文本挖掘
接下來需要對新聞內容進行分詞,在分詞之前需要導入一些自定義字典,目的是提高切詞的準確性。由于文本中涉及到軍事、醫療、財經、體育等方面的內容,故需要將搜狗字典插入到本次分析的字典集中。
手把手教你做文本挖掘
手把手教你做文本挖掘
如果需要卸載某些已導入字典的話,可以使用()函數。
分詞前將中文中的英文字母統統去掉。

手把手教你做文本挖掘
圖中圈出來的詞對后續的分析并沒有什么實際意義,故需要將其剔除,即刪除停止詞。
手把手教你做文本挖掘
手把手教你做文本挖掘
停止詞創建好后,該如何刪除76條新聞中實際意義的詞呢?下面通過自定義刪除停止詞的函數加以實現。
手把手教你做文本挖掘
手把手教你做文本挖掘

相比與之前的分詞結果,這里瘦身了很多,剔除了諸如“是”、“的”、“到”、“這”等無意義的次。
判別分詞結果的好壞,最快捷的方法是繪制文字云數據挖掘方法有哪些,可以清晰的查看哪些詞不該出現或哪些詞分割的不準確。
手把手教你做文本挖掘
手把手教你做文本挖掘
仍然存在一些無意義的詞(如說、日、個、去等)和分割不準確的詞語(如黃金周切割為黃金,醫藥切割為藥等),這里限于篇幅的原因,就不進行再次添加自定義詞匯和停止詞。
手把手教你做文本挖掘
手把手教你做文本挖掘

此時語料庫中存放了76條新聞的分詞結果。
手把手教你做文本挖掘
手把手教你做文本挖掘
從圖中可知,文檔-詞條矩陣包含了76行和7939列,行代表76條新聞,列代表7939個詞;該矩陣實際上為稀疏矩陣數據挖掘方法有哪些,其中矩陣中非0元素有11655個,而0元素有,稀疏率達到98%;最后,這7939個詞中,最頻繁的一個詞出現在了49條新聞中。
由于稀疏矩陣的稀疏率過高,這里將剔除一些出現頻次極地的詞語。
手把手教你做文本挖掘
手把手教你做文本挖掘
這樣一來,矩陣中列大幅減少,當前矩陣只包含了116列,即116個詞語。
為了便于進一步的統計建模,需要將矩陣轉換為數據框格式。
手把手教你做文本挖掘
手把手教你做文本挖掘
總結
所以在實際的文本挖掘過程中,最為困難和耗費時間的就是分詞部分,既要準確分詞,又要剔除無意義的詞語,這對文本挖掘者是一種挑戰。
完 謝謝觀看
完 謝謝觀看