

圖像到圖像轉換是一項非常重要的研究課題,也出現了很多圖像轉換方法,但是相關圖像到圖像轉換模型都脫離不了監督訓練。因而,越來越多的研究人員開始探索無監督設置下的圖像到圖像轉換方法。2019 年 5 月,英偉達的一項研究探索 few-shot 無監督的圖像到圖像轉換算法,并實現了逼真的轉換效果。近日,韓國延世大學等機構的研究者實現了完全無監督設置下的圖像到圖像轉換。
選自arXiv,作者: Baek等,機器之心編譯,參與:小舟、杜偉。
我們都知道,最近出現的各種圖像到圖像轉換模型都至少使用圖像級(即輸入 - 輸出對)或集合級(即域標簽)監督中的一種。但實際上,即使是集合級的監督也可能成為數據收集過程中嚴重的瓶頸。
因此,在本篇論文中,來自韓國延世大學、Naver 株式會社 Clova AI 和瑞士洛桑聯邦理工學院的研究者在完全無監督設置下完成圖像到圖像的轉換,即既沒有圖像對也沒有域標簽。值得關注的是,本文是一作 Baek 在 Clova AI 實習期間完成的。
那么研究者是如何實現無監督的圖像到圖像轉換呢?
他們提出了一種真正的無監督圖像到圖像轉換方法(truly image-to-image , TUNIT),在該方法中,通過信息論(-)方法學習分離圖像域以及使用預估域標簽生成相應的圖像,二者同時進行。
在各種數據集上的實驗結果表明,該方法能夠成功分離域,并且在這些域之間實現圖像轉換。此外,在提供域標簽子集的半監督設置下,該模型的性能優于現有的集合級監督方法。
論文詳解請戳:

如何實現的
首先,研究者闡明,本文中的無監督圖像到圖像轉換屬于無任何監督的任務,也就是沒有圖像級和集合級監督。其中有來自 K 個域(K≥2)的圖像 X,沒有標簽 y橋梁博士輸出圖形教程,K 是數據集的一個未知屬性。
圖 2:三種監督級別,以往的圖像到圖像轉換方法通常依賴 (a) 圖像級和 (b) 集合級監督,而本研究提出的方法在執行圖像到圖像轉換任務時使用的是 (c) 無任何監督的數據集。
接著,研究者提出了一個名為引導網絡( )的模型,它集成了域分類器和風格編碼器。通過將風格代碼饋入到生成器以及將偽域標簽饋入到鑒別器,該模型指導轉換過程。
最后,通過使用來自鑒別器的反饋,生成器合成目標域(例如品種)的圖像,同時尊重參考圖像的風格(例如毛發圖案),保持源圖像的內容(例如姿勢),具體架構如下圖 3 所示。
圖 3:該研究所提方法的概覽。
學習生成域標簽,編碼風格特征

在該研究的框架中,引導網絡 E 同時發揮著無監督域分類器和風格編碼器的作用。引導網絡 E 由 和 兩部分組成,它們分別學習提供域標簽和風格代碼。
帶有域指導的圖像到圖像轉換
對于成功的圖像轉換,轉換模型應該提供包含目標域視覺特征的逼真圖像。為此,研究者采用了 3 種損失:1)生成逼真圖像的對抗損失;2)鼓勵模型不要忽略風格代碼的風格對比損失;3)保留域不變(-)特征的圖像重建損失。
最后共同訓練鑒別器、生成器和引導網絡,具體公式如下所示:
效果怎么樣
所提策略的效果
對于這種可以同時執行表示學習和訓練轉換網絡的訓練策略,研究者進行了深入探究。盡管可以輕松想到分別訓練引導網絡和生成對抗網絡(GAN),但研究者證實了這會大大降低整體性能。
為了分析不同訓練策略的效果,研究者在訓練迭代的過程中繪制了逐級 FID,并提供了 tSNE 可視化圖,如下圖 4 所示:
(二維碼自動識別)
從 FID 的比較來看,相較于聯合訓練策略,單獨訓練策略得到的平均 FID 分值要高得多,標準差也更高。這清楚地表明,聯合訓練在圖像質量和性能穩定兩方面更加高效。
不帶任何標簽的圖像到圖像轉換
為了證實該方法能夠處理無監督情況下的圖像到圖像的轉換,研究者分別在 AFHQ、 和 LSUN Car 數據集上對模型進行了評估。
圖 6:在 AFHQ wild 上訓練引導網絡時,它的風格空間的 t-SNE 可視化圖。
圖 7:無監督情況下,在 AFHQ 上的圖像到圖像轉換結果。
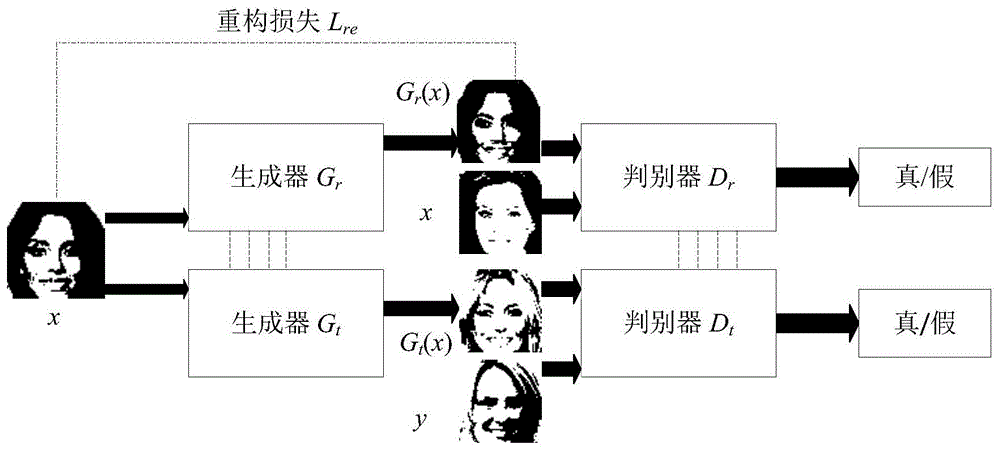
圖 8:無監督情況下,在 FFHQ 和 LSUN Car 上的圖像到圖像轉換結果。
帶有少量標簽的圖像到圖像轉換
研究者將該模型與在半監督學習設置下兩個方案訓練的 SOTA 模型做了比較,他們將數據集 D 劃分為標注集 Dsup 和未標注集 Dun橋梁博士輸出圖形教程,變化比率 γ = |Dsup|/|D|。
第一個方案是只用 D_sup 訓練模型;第二個方案是為了解決訓練轉換模型時可用樣本數量不公平的問題。
Na?ve 方案
下圖 10(a)和(b)展示了在 和 -10 上使用逐級 FID 的定量結果。
圖 10:na?ve 方案中,不同比例的標注圖像的 FID 曲線變化圖。
下圖 9 展示了該研究的結果與使用 na?ve 方案訓練的基線方法的定性結果比較。

圖 9:不同比例的標注圖像的定性結果比較。
替代方案
用 na?ve 方案訓練的基線方法不能完全利用訓練樣本,因為它根本不考慮 D_un。因此,為了更好地利用全部訓練樣本,研究者使用 D_sup 從頭開始訓練輔助分類器,以生成 D_un 的偽標簽。
圖 11:替代方案下 上的 FID 曲線變化圖。
下圖 12 展示了 -10 上的分類準確度和 FID 分數。
圖 12:(a)替代方案下 -10 上的 FID 曲線變化圖;(b)-10 上的分類準確度曲線。
輔助分類器的準確性隨著訓練樣本(帶標簽)的數量的增加而提高。更高的分類精度自然可以提高轉換質量。盡管 FUNIT 的 8% 的情況和 1% 的情況下的分類精度相似(約為 86%),但轉換性能顯示出了明顯的差距(FUNIT 是 59.6,該研究的模型是 47.9)。這意味著準確性不是唯一的評判轉換性能的因素。基于廣泛的比較與評估,研究者表明提出的模型對半監督方案是有效的,并且相比于基線有顯著的改善。