

導言:
基于深度學習的可端到端訓練的自然場景檢測與識別算法(text )由于其簡潔高效且統一的結構,逐漸取代了過去將檢測與識別分階段訓練然后拼接在一起的方案,成為自然場景文本檢測與識別的主流研究方向之一。端到端自然場景文本檢測和識別網絡一般都共享特征提取分支,根據提取的特征進行文本檢測,然后將檢測得到的文本特征送入識別模塊進行文本識別。
背景:
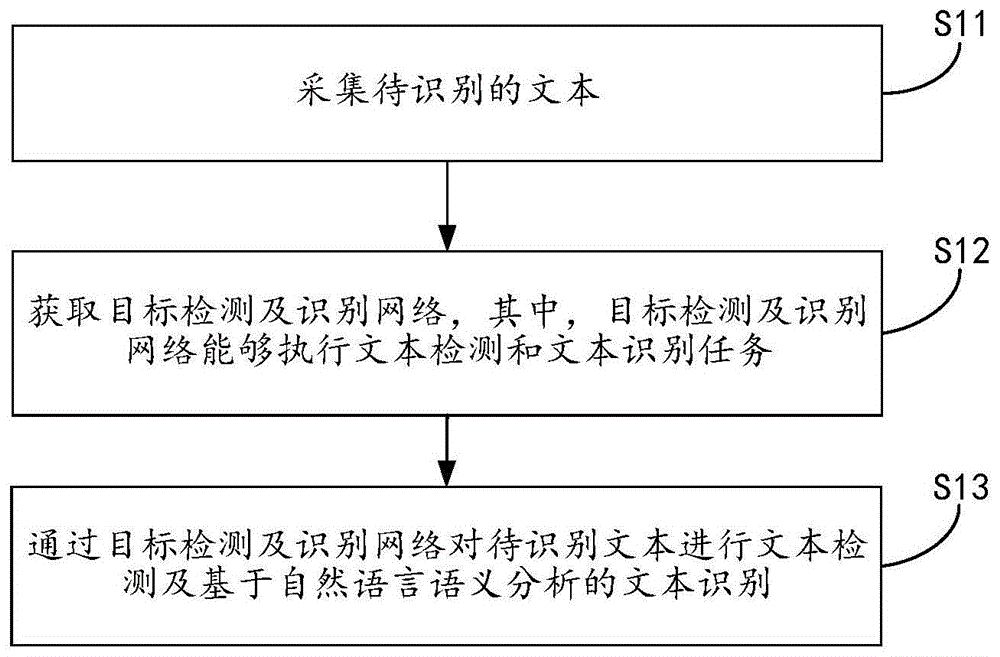
目前的主流算法也可以分成單階段和兩階段兩大類兩階段的方法都是基于目標檢測和實例分割中常用的算法 R-CNN 和Mask R-CNN。Li 等人(2017a)提出了第1個基于深度學習的端到端自然場景文本檢測和識別算法,該方法基于 R-CNN 進行檢測,將通過RoI- 提取的共享特征送入基于注意力機制()的識別器進行文本識別,但該方法只能檢測識別水平方向的文本。Lyu 等人(2018b) 基于Mask R-CNN 提出了,該方法在RoI-Align 之后額外增加了一個單字實例分割的分支,對文本的識別也是依賴于該分支的單字符分類。
它能夠檢測并識別任意形狀的文本,但訓練的時候需要依賴字符級別的標注。作者后續在這個工作的基礎上提出了 v2(Liao 等,2021),它加入了基于機制的序列識別分支以提高識別器性能,其結構如圖13 所示。Qin 等人(2019) 也是在Mask R-CNN 上進行改進,在預測出分割結果和文本最大外接檢測框之后通過RoI 的操作得到只有文本區域的特征圖送入文本識別網絡。后來Liao 等人(2020a)考慮到RPN 得到的文本候選區域對于任意形狀的文本不魯棒,于是提出了 v3,它首先設計了一個-free 的分割區域提取網絡( ,SPN)替代RPN 預測任意形狀文本的顯著圖,然后根據每個文本的掩碼mask 進行Hard RoI 操作,得到該文本的特征并送入識別網絡,檢測和識別分支的設計思路都沿用作者之前的 v2。
兩階段的端到端文本檢測識別算法的性能通常受到RoI- 等特征對齊操作的影響,所以很多學者也提出了單階段的方法。Liao 等人(2017)提出的(Liao 等人,2017) 和 + +(Liao 等人,2018a)都是基于單階段目標檢測器SSD進行改進,在得到文本檢測框之后送入CRNN(Shi等人,2017b)進行文本識別。其中 只能識別水平文本,而 ++ 由于加入了角度預測,所以能識別任意方向的四邊形文本。He 等人(2018)使用EAST 算法先檢測到任意方向的文本,然后通過Text Align 層在檢測框內進行采樣得到文本區域特征送入識別分支進行識別。Liu 等人(2018c)提出的FOTS(fast text )也是和He 等人的思想類似,同樣使用EAST 作為檢測分支,不同之處在于FOTS 是通過RoI 轉換任意方向文本的特征送入識別器進行文本識別。Xing等人(2019)提出的 則是和Mask 一樣使用單字符實例分割作為識別單元,檢測單元則是基于單字檢測和文本行檢測的結合。
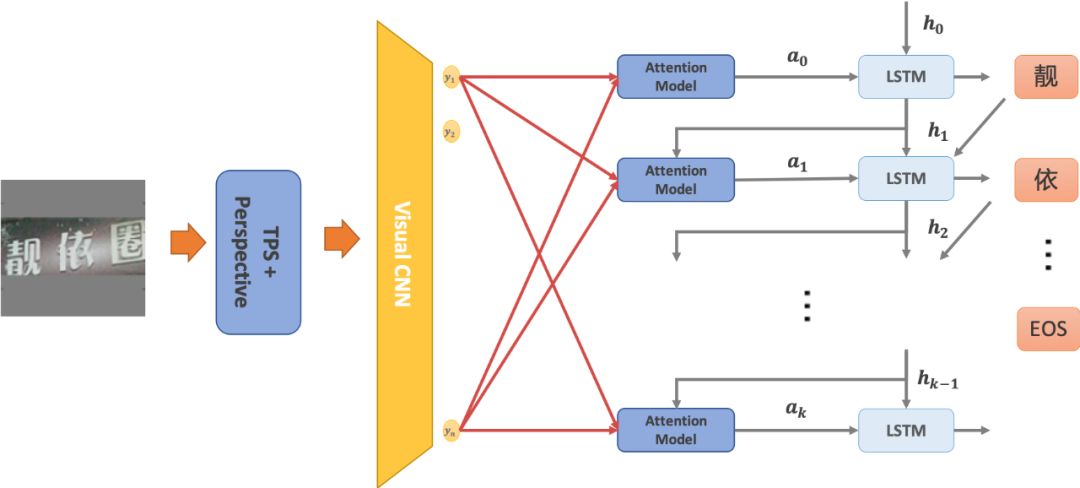
此外, 引入了和CRAFT 類似的迭代字符檢測方法以得到單字檢測結果,提高端到端的性能。基于文本組件的方法還有Feng 等人(2019a)提出的Text-,它不需要與 一樣的單字符級別標注,其檢測分支先檢測文本的任意四邊形組件,然后通過RoI slide 操作與CTC 算法結合進行文本識別。Qiao 等人(2020a)提出的 基于分割的方法對任意形狀的文本進行檢測,然后通過一個形狀變換模塊(shape )將檢測到的文本區域矯正成規則形態并送入識別分支。Wang 等人(2020a)的工作則是通過檢測任意形狀文本的邊界點,并通過TPS 變換對文本進行矯正,然后送入識別分支輸出最后的結果。
Liu 等人(2020)基于不需要錨點框(-free)的單階段目標檢測器FCOS(fully one-stage ) (Tian等,2019)提出了( -curve ),用三次貝塞爾曲線對不規則文本進行建模,通過學習貝塞爾曲線控制點檢測文本實例,并提出了 Align 更高效地連接檢測與識別的特征,極大提高了端到端文本檢測與識別的效率和性能,的結構如圖14 所示。Baek 等人(2020)以他們之前自然場景文本檢測的工作CRAFT 為基礎,提出,在檢測到不規則文本后對區域特征做TPS變換得到矯正后的文本特征結合單字檢測的結果,然后將其送入識別器進行文本識別。
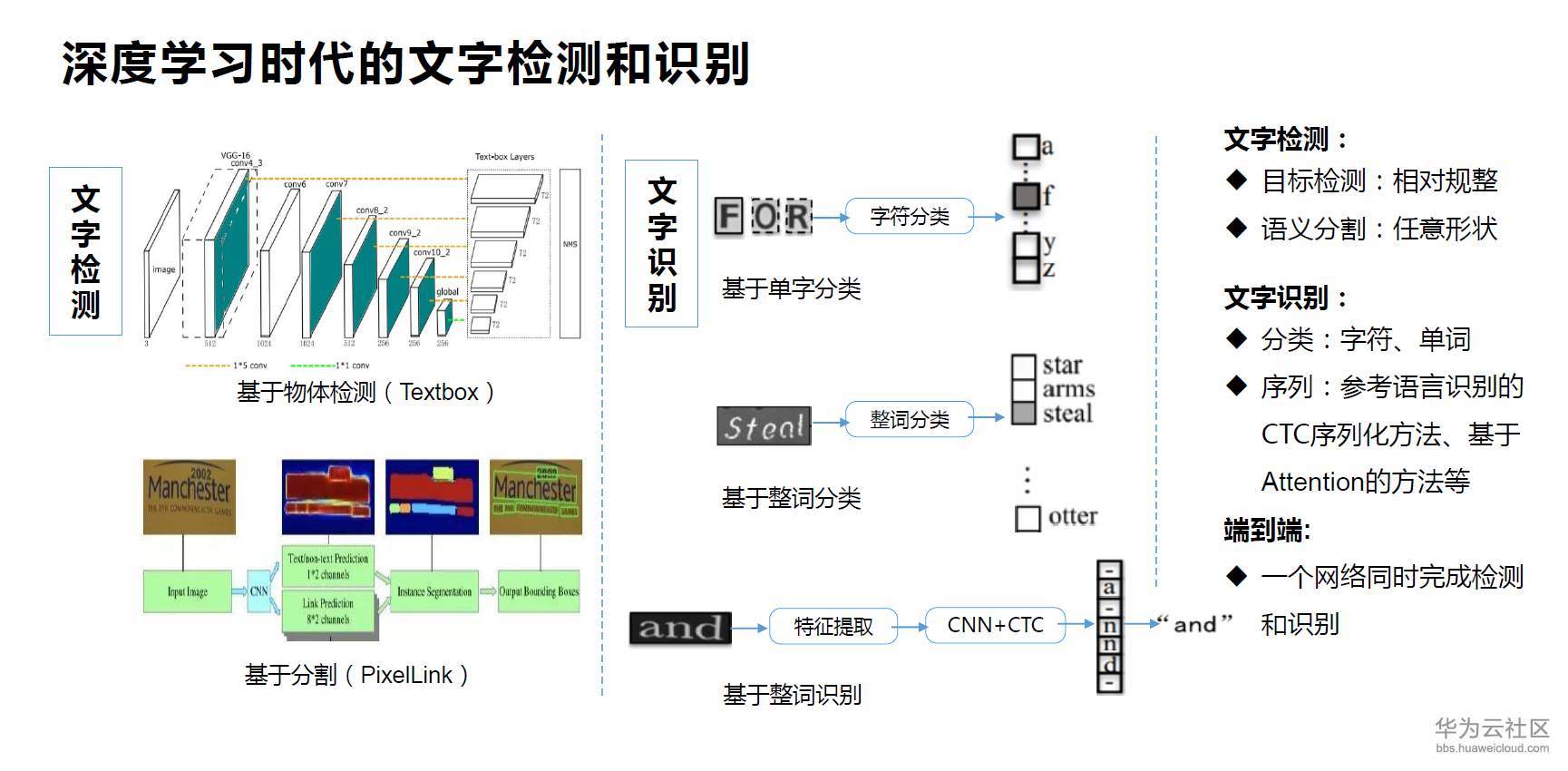
常用的端到端文本檢測與識別模型 FOTS
FOTS由中國科學院深圳先進技術研究所發表的論文《FOTS: Fast Text with a 》提出。一個統一的端到端可訓練的快速定向文本定位(FOTS)網絡,用于同時檢測和識別,在兩個互補的任務之間共享計算和視覺信息。特別地,引入了旋轉旋轉來共享檢測和識別之間的卷積特征。得益于卷積共享策略,FOTS與基線文本檢測網絡相比,計算消耗很小,并且聯合訓練方法學習了更多的通用特征,使FOTS方法比這兩階段方法表現得更好。實驗ICDAR 2015,ICDAR 2017 MLT和ICDAR 2013數據集表明,該方法優于最先進的方法,在上取得89.84%的F1,幀率達到22.6fps。
在本文中,提出同時考慮文本檢測和識別。它產生了快速端到端訓練的文本定位系統(FOTS)。與之前的兩階段文本定位相比,FOTS的方法通過卷積神經網絡學習更一般的特征,這些特征在文本檢測和文本識別之間共享,而這兩個任務的監督是互補的。由于特征提取通常需要大部分時間,因此它將計算范圍縮小為一個單一的檢測網絡,如圖1所示。連接檢測和識別的關鍵是,它根據定向的檢測邊界框從特征圖中得到合適的特征。
FOTS算法原理:
FOTS是一個端到端可訓練的框架,它可以同時檢測和識別自然場景圖像中的所有單詞。它由共享卷積、文本檢測分支、旋轉操作和文本識別分支四個部分組成。
其體系結構如圖2所示。首先利用共享卷積的方法提取特征圖。在特征圖之上建立了基于全卷積網絡的面向文本檢測分支來預測檢測邊界框。旋轉操作符從特征圖中提取與檢測結果對應的文本建議特征。然后將文本建議特征輸入循環神經網絡(RNN)編碼器和基于神經網絡的時序類分類(CTC)解碼器進行文本識別。由于網絡中的所有模塊都是可微的,所以整個系統可以進行端到端進行訓練。

共享卷積層的主干網絡是-50 。受FPN 的啟發,FOTS連接了低級特征映射和高級語義特征映射。由共享卷積產生的特征圖的分辨率為輸入圖像的1/4。文本檢測分支使用共享卷積產生的特征輸出文本的密集每像素預測。利用檢測分支產生的面向文本區域的建議,所提出的旋轉旋轉將相應的共享特征轉換為固定高度的表示,同時保持原始區域的高寬比。最后,文本識別分支識別區域提案中的單詞。采用CNN和LSTM對文本序列信息進行編碼,然后采用CTC解碼器。
文本檢測分支(the text )
受EAST與DDRN的啟發,FOTS采用完全卷積網絡作為文本檢測器。 由于自然場景圖像中有許多小文本框,FOTS將共享卷積中原始輸入圖像的1/32到1/4大小的特征映射放大。 在提取共享特征之后,應用一個轉換來輸出密集的每像素的單詞預測。 第一個通道計算每個像素為正樣本的概率。 與EAST類似,原始文本區域的縮小版本中的像素被認為是正的。 對于每個正樣本,以下4個通道預測其到包含此像素的邊界框的頂部,底部,左側,右側的距離,最后一個通道預測相關邊界框的方向。 通過對這些正樣本應用閾值和NMS產生最終檢測結果。
操作
對定向特征區域進行變換,得到軸對齊的特征圖,如圖4所示。在這項工作中,我們固定了輸出高度,并保持高寬比不變,以處理文本長度的變化。與和相比,RoI旋轉提供了一個更通用的提取感興趣區域特征的操作。FOTS還與RRPN中提出的進行了比較。通過最大池化將旋轉區域轉換為固定大小的區域,同時我們使用雙線性插值來計算輸出的值。該操作避免了RoI與提取的特征之間的不一致,并使輸出特征的長度成為變量,更適合于文本識別。
以共享卷積生成的特征圖作為輸入,生成所有文本提案的特征圖,高度固定和高寬比不變。與目標分類不同,文本識別對檢測噪聲非常敏感。預測文本區域的一個小誤差可能會切斷幾個字符,這對網絡訓練有害,因此FOTS在訓練過程中使用地面真實文本區域而不是預測的文本區域。在測試時,應用閾值化和NMS來過濾預測的文本區域。旋轉后,轉換后的特征映射被輸入到文本識別分支。
文本識別分支(the text )
文本識別分支的目標是利用共享卷積提取和的區域特征來預測文本標簽。考慮到文本區域中標簽序列的長度,LSTM的輸入特征只減少了兩次(減少為1/4)沿著寬度軸通過共享的卷積從原始圖像。否則,將消除緊湊文本區域中可區分的特征,特別是那些窄形字符的特征。FOTS的文本識別分支包括 序列卷積、僅沿高度軸縮減的池、一個雙向LSTM 、一個全連接和最終的CTC解碼器。
實驗結果:
FOTS選擇三個具有挑戰性的公共基準數據集:ICDAR 2015、ICDAR 2017 MLT和ICDAR 2013對方法進行評估。
ICDAR 2015是ICDAR 2015魯棒閱讀競賽的挑戰4,該競賽通常用于定向場景文本檢測和定位。該數據集包括1000張訓練圖像和500張測試圖像。這些圖像由谷歌眼鏡捕獲,不考慮位置,因此場景中的文本可以是任意方向。對于文本識別任務,它提供了三個特定的詞匯列表,供測試階段參考,分別命名為“”、“WEAK”和“”。“”詞典為每張圖片提供100個單詞,包括圖片中出現的所有單詞。“WEAK”詞匯包括整個測試集中出現的所有單詞。“”詞匯是一個90k單詞詞匯。在訓練中,首先使用ICDAR 2017 MLT訓練和驗證數據集中的9000張圖像對模型進行訓練,然后使用1000張ICDAR 2015訓練圖像和229張ICDAR 2013訓練圖像對模型進行微調。
ICDAR 2017 MLT是一個大型多語言文本數據集,包括7200個訓練圖像、1800個驗證圖像和9000個測試圖像。該數據集由來自9種語言的完整場景圖像組成,其中的文本區域可以是任意方向的,因此更具多樣性和挑戰性。這個數據集沒有文本檢測任務,所以只報告文本檢測結果。
ICDAR 2013由229張訓練圖像和233張測試圖像組成,但與上述數據集不同,它只包含水平文本。本識別任務提供了“”、“WEAK”和“”詞匯。。雖然FOTS方法是針對定向文本設計的,但該數據集的結果表明,所提出的方法也適用于水平文本。由于訓練圖像太少,首先使用ICDAR 2017 MLT訓練和驗證數據集中的9000張圖像來訓練預訓練模型,然后使用229張ICDAR 2013訓練圖像進行微調。
與以往將文本檢測和識別分為兩個不相關的任務的工作不同,FOTS將這兩個任務聯合訓練,并且文本檢測和識別可以相互受益。為了驗證這一點,我們構建了一個兩階段系統,其中文本檢測和識別模型分別進行訓練。在FOTS網絡中,檢測網絡是通過去除識別分支來構建的,同樣,檢測分支也是從原始網絡中去除的,從而得到識別網絡。對于識別網絡,從源圖像裁剪的文本行區域被用作訓練數據,類似于以前的文本識別方法【《An end-to-end for image-based and its to scene text 》、《 scene text in deep .》、《Star-net: A for scene text 》】。
如表2、3、4所示, FOTS顯著優于文本定位任務中的兩階段方法“”和文本定位任務中的“Our Two-Stage”。結果表明,FOTS的聯合訓練策略使模型參數達到了更好的收斂狀態。
FOTS在檢測方面表現更好,因為文本識別監控有助于網絡學習詳細的字符級特征。為了進行詳細分析,我們總結了文本檢測的四個常見問題,未命中:丟失一些文本區域,錯誤:將一些非文本區域錯誤地視為文本區域,拆分:將整個文本區域錯誤地拆分為幾個單獨的部分,合并:將幾個獨立的文本區域錯誤地合并在一起。如圖5所示,與“”方法相比,FOTS大大減少了所有這四種類型的錯誤。
具體來說ps怎么識別圖中字體,“”方法側重于整個文本區域特征,而不是字符級特征,因此當文本區域內部存在較大差異或文本區域與其背景具有相似模式等情況下,該方法效果不佳。因為文本識別監管迫使模型考慮字符的細微細節,FOTS學習具有不同模式的單詞中不同字符之間的語義信息。它還增強了具有相似模式的角色和背景之間的差異。如圖5所示,對于未命中的情況,“我們的檢測”方法未命中文本區域,因為它們的顏色與其背景相似。

對于錯誤的情況,“”方法錯誤地將背景區域識別為文本,因為它具有“類似文本”的模式(例如,具有高對比度的重復結構條紋),而FOTS在考慮擬議區域中的字符細節的認識損失訓練后避免了這種錯誤。對于拆分情況,“”方法將文本區域拆分為兩個,因為該文本區域的左側和右側具有不同的顏色,而FOTS將該區域作為一個整體進行預測,因為該文本區域中的字符模式是連續且相似的。對于合并案例,“”方法錯誤地將兩個相鄰的文本邊界框合并在一起,因為它們太近且具有相似的模式,而FOTS利用文本識別提供的字符級信息并捕獲兩個單詞之間的空間
在ICDAR 2015數據集的實驗結果如下圖所示:
在ICDAR 2017數據集的實驗結果如下圖所示:
在ICDAR 2013數據集的實驗結果如下圖所示:
將FOT與最先進的方法進行比較。如表2、3、4所示,FOTS的方法在所有數據集中都比其他方法有很大的優勢。由于ICDAR 2017 MLT沒有文本檢測任務,實驗只報告文本檢測結果。ICDAR 2013中的所有文本區域都由水平邊界框標記,而其中許多區域略微傾斜。由于FOTS的模型是使用ICDAR 2017 MLT數據進行預訓練的,因此它還可以預測文本區域的方向。FOTS的最終文本定位結果保持預測方向以獲得更好的性能,并且由于評估協議的限制ps怎么識別圖中字體,FOTS的檢測結果是網絡預測的最小水平外接矩形。值得一提的是,在2015年ICDAR文本識別任務中,FOTS的方法在方面比之前的最佳方法【《 text in by . 》、《An end-to-end for image-based and its to scene text 》】要好15%以上。對于單尺度測試,對于ICDAR 2015、ICDAR 2017 MLT和ICDAR 2013,FOTS分別將輸入圖像的長邊大小調整為2240、1280、920,以獲得最佳結果,FOTS采用3-5尺度進行多尺度測試。
結論:
FOTS,一個面向場景文本識別的端到端可訓練框架。提出了一種新的旋轉操作,將檢測和識別統一到端到端的流水線中。FOTS具有模型小,速度快,精度高,支持多角度等特點,在標準基準測試上的實驗表明,FOTS的方法在效率和性能方面明顯優于以前的方法。