

機器之心編譯
參與:王宇欣、吳攀 、邵明
隨著機器學習越來越流行,也出現了越來越多能很好地處理任務的算法。但是,你不可能預先知道哪個算法對你的問題是最優的。如果你有足夠的時間,你可以嘗試所有的算法來找出最優的算法。本文介紹了如何依靠已有的方法(模型選擇和超參數調節)去指導你更好地去選擇算法。本文作者為華盛頓大學 和 for 的數據科學博士后 。
步驟 0:了解基本知識

在我們深入學習之前,我們先重溫基礎知識。具體來說,我們應該知道機器學習里面三個主要類別:監督學習,無監督學習和強化學習。
步驟 1:對問題進行分類
接下來,我們要對問題進行分類,這包含兩個過程:
就是這么簡單!
更一般地說,我們可以詢問我們自己:我們的算法要實現什么目標,然后以此來找到正確的算法類別。
上面的描述包括了幾個我們還沒有提到的專業術語:
步驟 2:尋找可用的算法
現在我們已經將問題進行了分類,我們就可以使用我們所掌握的工具來識別出適當且實用的算法。

Azure 創建了一個方便的算法列表,其展示了哪些算法可用于哪種類別的問題。雖然該表單是針對 Azure 軟件定制的,但它具有普遍的適用性(該表單的 PDF 版本可查閱 ):
一些值得注意的算法如下:
步驟 3:實現所有適用的算法
對于任何給定的問題,通常有多種候選算法可以完成這項工作。那么我們如何知道選擇哪一個呢?通常,這個問題的答案并不簡單,所以我們必須反復試驗。

原型開發最好分兩步完成。在第一步中,我們希望通過最小量的特征工程快速且粗糙地實現一些算法。在這個階段,我們主要的目標是大概了解哪個算法表現得更好。這個步驟有點像招聘:我們會盡可能地尋找可以縮短我們候選算法列表的理由。
一旦我們將列表減少至幾個候選算法,真正的原型開發開始了。理想情況下,我們會建立一個機器學習流程,使用一組經過仔細選擇的評估標準來比較每個算法在數據集上的表現。在這個階段機器學習防止過擬合,我們只處理一小部分的算法,所以我們可以把注意力轉到真正神奇的地方:特征工程。
步驟 4:特征工程
或許比選擇算法更重要的是正確選擇表示數據的特征。從上面的列表中選擇合適的算法是相對簡單直接的,然而特征工程卻更像是一門藝術。
主要問題在于我們試圖分類的數據在特征空間的描述極少。利如,用像素的灰度值來預測圖片通常是不佳的選擇;相反,我們需要找到能提高信噪比的數據變換。如果沒有這些數據轉換,我們的任務可能無法解決。利如,在方向梯度直方圖(HOG)出現之前,復雜的視覺任務(像行人檢測或面部檢測)都是很難做到的。

雖然大多數特征的有效性需要靠實驗來評估,但是了解常見的選取數據特征的方法是很有幫助的。這里有幾個較好的方法:
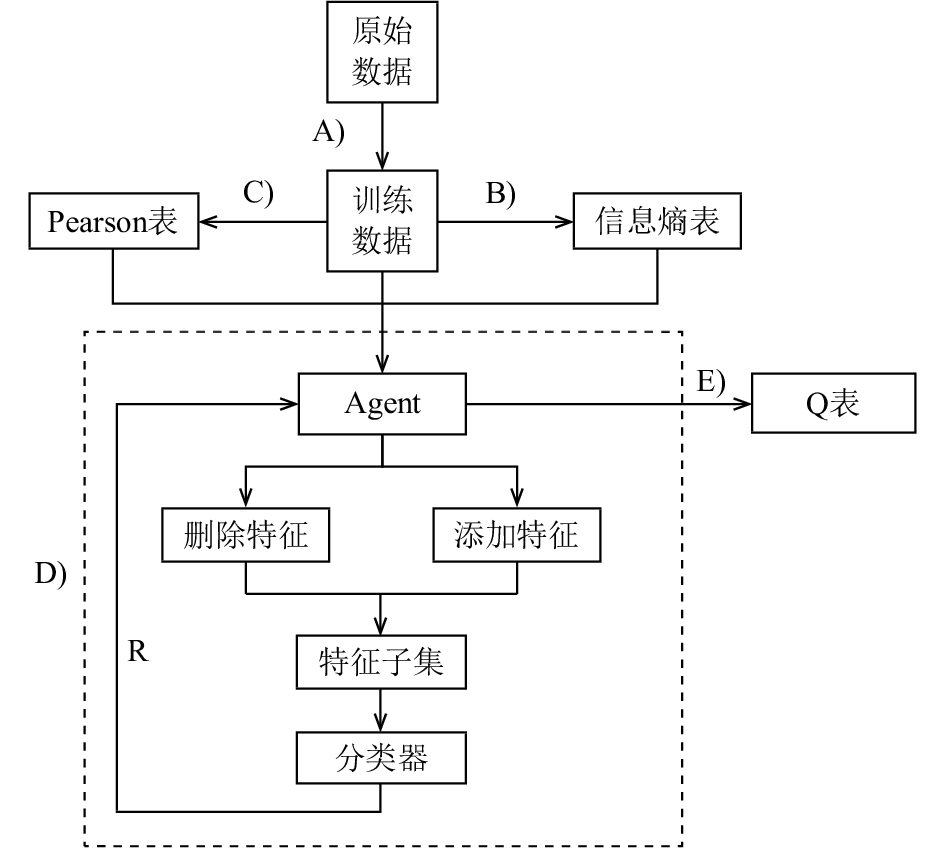
當然機器學習防止過擬合,你也可以想出你自己的特征描述方法。如果你有幾個候選方法,你可以使用封裝好的方法進行智能的特征選擇。
使用交叉驗證的準則來移除和增加特征!
步驟 5:超參數優化
最后,你可能想優化算法的超參數。例如,主成分分析中的主成分個數,k 近鄰算法的參數 k,或者是神經網絡中的層數和學習速率。最好的方法是使用交叉驗證來選擇。
一旦你運用了上述所有方法,你將有很好的機會創造出強大的機器學習系統。但是,你可能也猜到了,成敗在于細節,你可能不得不反復實驗,最后才能走向成功。