

最近網(wǎng)頁數(shù)據(jù)爬取工具,有同學(xué)問我。
我不想寫代碼,如何快速爬取幾個(gè)數(shù)據(jù)量不太大的網(wǎng)頁?
為啥有人開發(fā)個(gè)爬蟲插件的入門教程,要收費(fèi)好幾千?很難學(xué)會(huì)嗎?
說實(shí)話,爬蟲插件并沒有那么難!!!
但爬蟲插件真的很強(qiáng)悍,能幫我們解決各種小問題;比如,你想爬取秒殺頁面的商品信息進(jìn)行對(duì)比;你想爬取國家統(tǒng)計(jì)局官網(wǎng)發(fā)布的你感興趣的數(shù)據(jù);等等。
既然說到這里,我就簡單的介紹一下網(wǎng)絡(luò)爬蟲。網(wǎng)絡(luò)爬蟲的主要目的是爬取互聯(lián)網(wǎng)上的網(wǎng)頁。你可以把互聯(lián)網(wǎng)中的每一個(gè)網(wǎng)頁想象成一個(gè)點(diǎn),那么整個(gè)互聯(lián)網(wǎng)將是彼此連通的。是不是很像我們大學(xué)學(xué)過的圖論?如果從任何一個(gè)網(wǎng)頁出發(fā),在時(shí)間資源允許的情況下,使用廣度優(yōu)先算法(BFS)或者深度優(yōu)先算法(DFS)是可以爬完整個(gè)互聯(lián)網(wǎng)的。對(duì)這兩種算法不太熟悉的同學(xué)可以去背書了。
下面以比較流行的 架構(gòu)圖為例,流線為數(shù)據(jù)流向。
看了這幅圖,是不是對(duì)一般的爬蟲有了大致的了解了。

專業(yè)的網(wǎng)絡(luò)爬蟲(比如百度/谷歌的爬蟲)為了節(jié)約資源和時(shí)間,因此,設(shè)計(jì)是相當(dāng)復(fù)雜的。這些爬蟲一般是基于分布式集群構(gòu)建的,有些機(jī)子負(fù)責(zé)調(diào)度,有些機(jī)子負(fù)責(zé)下載,有些機(jī)子專門基于網(wǎng)頁進(jìn)行分析,等等。并非簡單的用 BFS/DFS 就能解決的,比如,我們以調(diào)度器為例,它就需要來管理下載優(yōu)先級(jí),當(dāng)引擎發(fā)送過來 請(qǐng)求,就需要按照優(yōu)先級(jí)進(jìn)行整理排列,入隊(duì),當(dāng)引擎需要時(shí),交還給引擎。
雖然關(guān)于各種語言的爬蟲框架很多,要是用這些框架來爬這點(diǎn)數(shù)據(jù),確實(shí)有點(diǎn)大材小用了,而且還得要編碼調(diào)試,各種麻煩!!!
下載
我發(fā)現(xiàn) 商店里面有一款爬蟲插件,剛好解決這個(gè)痛點(diǎn),它的名字叫做 Web ,目前有 22w 的用戶下載。
官方地址:.io
官方安裝地址:如何離線安裝?
由于不少同學(xué)不能訪問商店,因此,我?guī)痛蠹蚁螺d好了網(wǎng)頁數(shù)據(jù)爬取工具,大家可以離線安裝這款插件。

離線安裝包地址: /s/XSQ?pwd=4hof
在地址欄,輸入 :/// ,回車,便會(huì)出現(xiàn)如下界面。
把壓縮包內(nèi)的.crx文件直接拖拽到該頁面,便會(huì)自動(dòng)跳轉(zhuǎn)到Web 官網(wǎng),表明已經(jīng)安裝成功了!
這個(gè)爬蟲操作真的特別簡單,照著官方文檔,幾分鐘就學(xué)會(huì)了。
我這里就說幾個(gè)關(guān)鍵點(diǎn)吧。
入門教程1、啟動(dòng)
一般初次使用,不知道怎么打開它,用快捷鍵 ctrl+shift+i 打開開發(fā)者工具。
:你所有的爬蟲。
new :創(chuàng)建一個(gè)新爬蟲的起始地址。
2、選擇器
對(duì)于一個(gè)選擇器而言,就有如下幾種元素,它主要作用是為爬蟲分析網(wǎng)頁的功能,提供了可視化選擇的功能,如下圖所示。
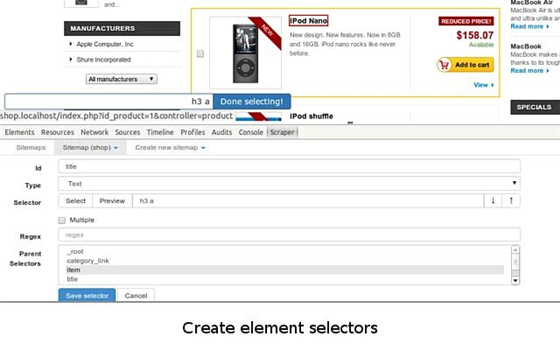
好了,再來細(xì)說一下,選擇器內(nèi)部的幾個(gè)元素。
Id: 選擇器的ID;
Type:要抓取內(nèi)容的類型,有文本、圖片以及元素集等;
:選擇器。點(diǎn)擊 按鈕可以選擇我們要抓取的內(nèi)容,點(diǎn)擊 按鈕可以預(yù)覽選擇的內(nèi)容,而點(diǎn)擊 data 按鈕可以預(yù)覽抓取的數(shù)據(jù);
:勾選了這個(gè)按鈕可以并聯(lián)相同的內(nèi)容;
Regex:正則表達(dá)式;
Delay:延遲。為了讓頁面有足夠的時(shí)間加載數(shù)據(jù);
:父選擇器。
有的同學(xué)可能會(huì)問,如果我要在一個(gè)頁面選擇多個(gè)元素,該怎么辦呢?上面的提到的 Type 屬性里面的 就起到這個(gè)作用,如我這里。
3、關(guān)系圖
我覺得這個(gè)功能特別棒,幫我們看到這個(gè)爬蟲的層級(jí)關(guān)系圖。
最后,就是爬取數(shù)據(jù)了,爬取后的數(shù)據(jù)還可以導(dǎo)出為 excel,便于你分析。
大家可以去玩一下這個(gè)爬蟲插件,會(huì)幫你快速分析一些簡單的數(shù)據(jù)。
就寫到這里吧。
這個(gè)插件學(xué)會(huì)了,省掉了幾千塊錢的智商稅!