

來自twt社區同行交流,歡迎更多同行參與
對象存儲的壓測如何做?我們公司對于對象存儲的選型,基本上已經定了ceph,目前正在大力研究ceph ,對于后續的非結構化,及結構化數據今后將準備往ceph 分布式存儲上批量應用,對于這方面有幾個問題
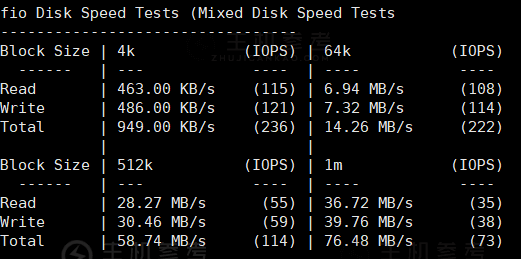
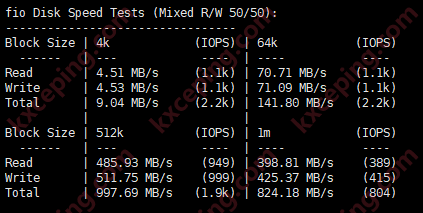
1: 因為用的14.2.10版的, 可參考的案列不是很多, 目前我們用 存儲 ,壓測效果 不是很理想, 想準備采用分層緩存, 將ssd 做前端緩存池, sata 做后端存儲池, 這種方案 較之前方法,在性能上會不會有很大提升,?因為之前 壓測結果來看, 4k隨機讀iops 能達到 12w, 但隨機寫的iops 只能達到 5000多 ,這方面不知道為什么會差這么多?
2: 由于我 對于壓測方面 也沒什么經驗,對于塊存儲對象存儲有什么用,文件存儲,對象存儲方面的壓測能否在這方嗎分享下經驗,以下是我自己摸索的, 請指教:
1):塊存儲:用fio
隨機讀
fio --=./test -=64 -= -=1 -rw= -bs=4k -size=2G -=64 -=30 - -name=test-rand-read
隨機寫

fio --=./test -=64 -= -=1 -rw= -bs=4k -size=2G -=64 -=30 - -name=test-rand-write
2):文件存儲:用的也是 fio ,對于文件存儲的壓測,在引擎這塊需要特殊選擇嗎?
3):對象存儲:用的是 , 這個壓測 結果 ,我們重點關注什么參數結果了 ?是(op/s )還是 (B/s) ?
問題來自社區會員@山雞 某保險企業
@榮重實 XSKY 技術總監:
使用對象存儲,先從自身業務出發,明確要存的數據類型和數據大小范圍;海量小文件肯定是主要關注ops,而且要看平均時延,對小文件的性能,開源Ceph的優化肯定是不足的,另外現在的cache tier技術,所有數據都會過cache,很容易就會把cache層沖爆;對于比較大的文件類型,關注就好;對象存儲底層數據落盤會落大塊,所以如果小文件肯定會有實際存儲空間的浪費。
對于硬件的配置,比如cpu內存SSD,都是影響測試數值的關鍵因素,感覺性能不足,還要檢查測試用例和測試模型,跟實際硬件配置綜合考量。
@:
把size設置大點看下,讀的性能是不是波動很大。
@ 成都歐珀通信科技有限公司 運維工程師:
對象存儲的壓測用的比較多的是,從您壓測的結果來看,隨機讀應該是內存讀寫。對象存儲壓測的結果跟服務器數量,硬盤類別、數量以及對象存儲的存儲池配置都有很大的關系,沒有壓測硬件配置和ceph的配置信息,很難對結果進行評估。
@ 戴爾科技 ASE:
對于塊和文件的測試對象存儲有什么用,說的文件已經比較多,我就不再班門弄斧了。
對于對象,是一個用得比較多的工具,一般來說,針對不同的應用情況,來決定你對OPS、響應時間、帶寬、成功率等等指標的敏感程度。
一般來說,對性能要求較高,可以是OPS、時延比較重要;帶寬對并發比較重要。