

今天這篇文章,給大家講述一下數據倉庫的ETL基礎算法,作為我們一起探討的內容。希望大家留言、評論,我們一起學習。
ETL定義:
是數據抽取()、轉換()、清洗()、裝載(Load)的過程。是構建數據倉庫的重要一環數據倉庫有幾種etl算法,用戶從數據源抽取出所需的數據,經過數據清洗,最終按照預先定義好的數據倉庫模型,將數據加載到數據倉庫中去
一 ETL工具
首先我們來看下常用的ETL工具都有哪些,我說一下我用過的ETL工具,,,,目前我接觸的有這三種,基本上都是基于圖形化開發的工具,簡單的拖拉拽就可以替代原先的SQL代碼,開發效率高,運行穩定,但是這種太不易于后期的維護和擴展,可讀性也不強。所以現在的銀行業大都慢慢地放棄了,現在都是基于大數據平臺開發(A/O分離),然后通過ETL調度,編寫存儲過程實現數據流動。
二 ETL是數據倉庫的基礎
數據倉庫系統以事實發生數據為基礎,自產數據較少。一個企業往往包含多個業務系統,均可能成為數據倉庫的數據源。
三 ETL在BI架構中的定位
四 源數據概況
1
流水事件表:此類源表用于記錄交易等動作的發生,在源系統中會新增、大部分不會修改和刪除,少量表存在刪除情況。如定期存款登記簿;
常規狀態表:此類源表用于記錄數據信息的狀態。在源系統中會新增、修改,也存在刪除的情況。如客戶信息表;

代碼參數表:此類源表用于記錄源系統中使用到的數據代碼和參數
2
數據文件大多數以1天為固定的周期從源系統加載到數據倉庫。數據文件包含增量,全量以及待刪除的增量。
增量數據文件:數據文件的內容為數據表的增量信息,包含表內新增及修改的記錄。
全量數據文件:數據文件的內容為數據表的全量信息,包含表內的所有數據。
待刪除的增量:數據文件的內容為數據表的增量信息,包含表內新增、修改及刪除的記錄,通常刪除的記錄以字段='D'標識該記錄。
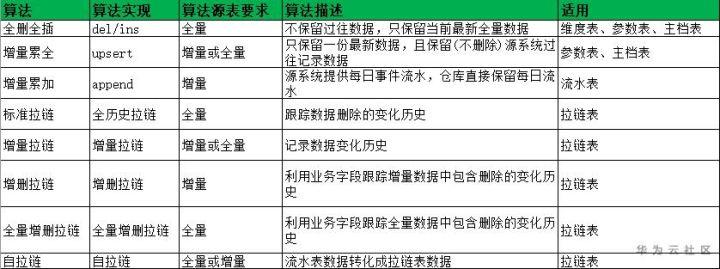
五 ETL算法概述
1 ETL標準算法
歷史拉鏈:根據業務分析要求,對數據變化都要記錄,需要基于日期的連續歷史軌跡;
追加(事件表):根據業務分析要求,對數據變化都要記錄,不需要基于日期的連續歷史軌跡;
(主表):根據業務分析要求,對數據變化不需要都要記錄,當前數據對歷史數據有影響;

全刪全加算法(參數表):根據業務分析要求,對數據變化不需要都要記錄,當前數據對歷史數據無影響;
2 ETL標準算法選擇
3 歷史拉鏈法
所謂拉鏈數據倉庫有幾種etl算法,就是記錄歷史,記錄一個事務從開始,一直到當前狀態的所有變化信息(參數新增開始結束日期)。
4 追加算法
一般用于事件表,事件之間相對獨立,不存在對歷史信息進行更新。
5 算法
是和組合體,一般用于對歷史信息變化不需要進行跟蹤保留、只需其最新狀態且數據量有一定規模的表,如客戶資料表。
6 全刪全加算法
一般用于數據量不大的參數表,把歷史數據全部刪除,然后重新全量加載。
算法的復雜度比較:
具體算法概述1:
0210算法
0211算法
0212算法

具體算法概述2
0610算法
0611算法
0612算法
0613算法
0614算法
0615算法
0616算法
0617算法
0618算法
0619算法
總結:
按照實際工作經驗來看,ETL算法常用的有:
歷史拉鏈 ----最常用,記錄事物變化
追加(事件表) ---根據業務需求
全刪全加算法(參數表) --根據業務需求
可以根據實際需求選擇不同的算法。
