

01
首先,先回顧一下什么是數(shù)據(jù)庫。
1. 數(shù)據(jù)庫
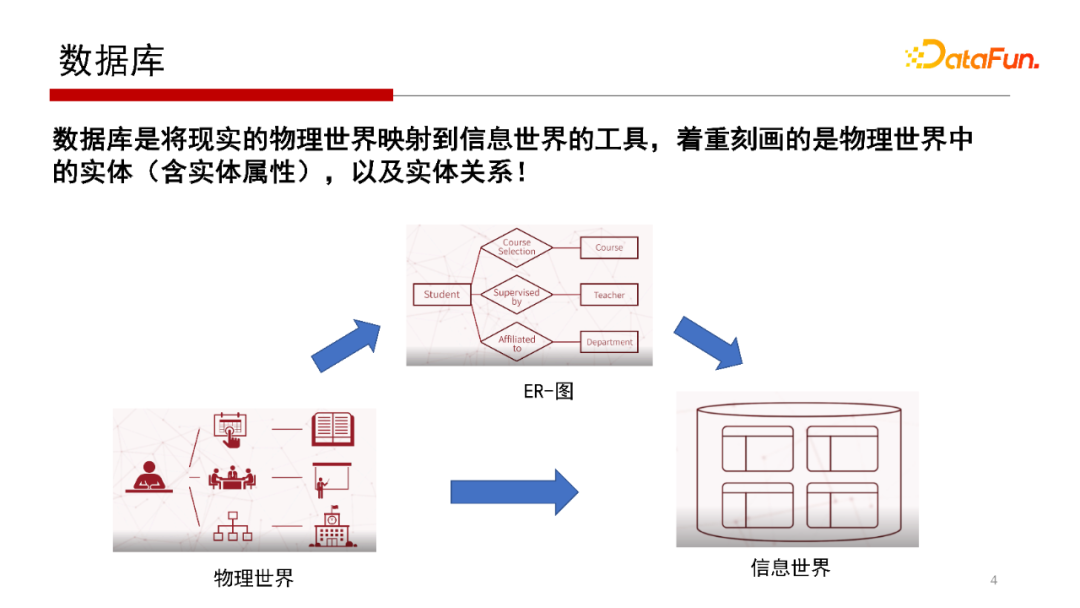
數(shù)據(jù)庫研究的核心就是將物理世界映射到信息世界,在數(shù)據(jù)庫學(xué)習(xí)課程中會學(xué)到一個概念模型E-R圖。E-R圖表示實體與實體之間的關(guān)系,也會將實體的屬性包含在內(nèi)。
2. 回顧-關(guān)系型數(shù)據(jù)庫(RDBMS)
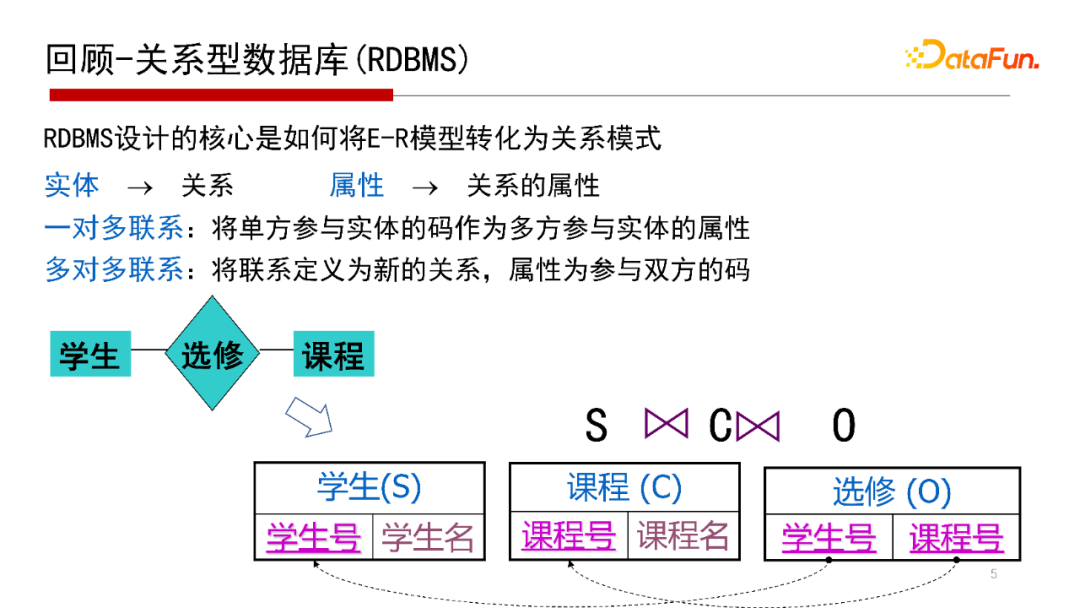
我們再回顧一下關(guān)系型數(shù)據(jù)庫是怎么實現(xiàn)E-R關(guān)系映射的。E-R圖是一個概念模型,是在對信息世界、物理世界建模的時候需要一個概念模型( Model)。那么,如何將一個概念模型進(jìn)行一個物理實現(xiàn)呢?如果底層用的是關(guān)系數(shù)據(jù)庫,需要將E-R圖結(jié)構(gòu)映射到一個二維的關(guān)系表中,如“學(xué)生選修課程”的E-R圖,映射到學(xué)生表、課程表和選修表這樣的二維關(guān)系表中,這是關(guān)系數(shù)據(jù)庫設(shè)計的基本思路。
3. 圖數(shù)據(jù)庫-
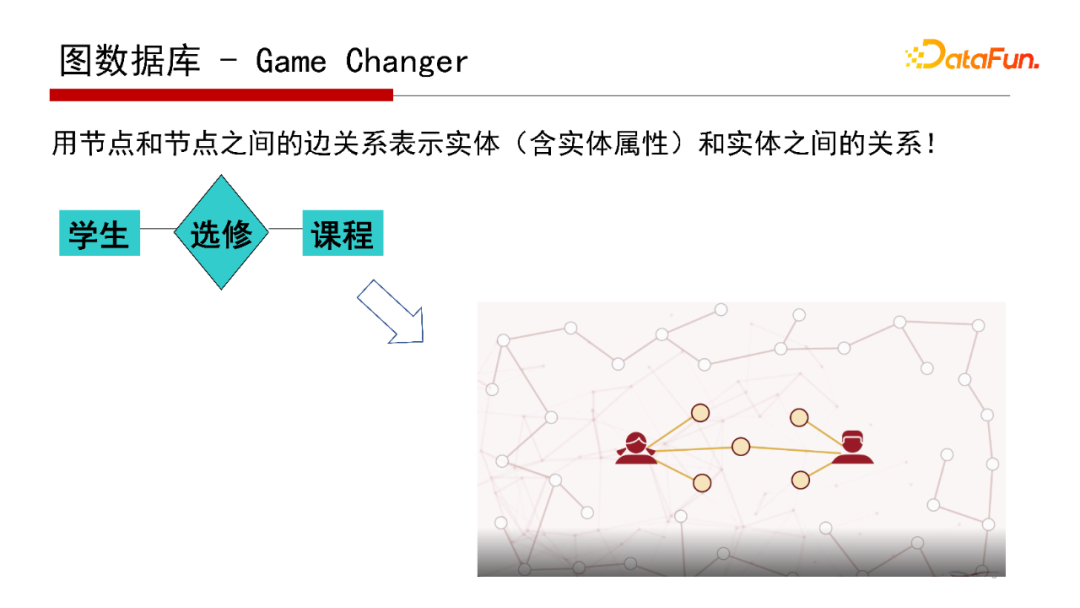
如果采用圖數(shù)據(jù)庫作為底層的物理實習(xí),就是把E-R圖表示的概念模型映射成圖數(shù)據(jù)庫中的節(jié)點和邊,因為E-R圖和圖數(shù)據(jù)庫均采用“圖”的形式進(jìn)行表達(dá),因此這樣的映射更加直接。那么,E-R圖與圖數(shù)據(jù)庫的模型有什么區(qū)別呢?
首先,兩類模型定位不一樣。E-R圖是概念模型,更像類(class)圖,定義的是類之間的邏輯關(guān)系,不是數(shù)據(jù)的實例()之間的關(guān)聯(lián);而圖數(shù)據(jù)庫的模型是物理實現(xiàn)的數(shù)據(jù)模型,圖數(shù)據(jù)庫中的每個點和邊表示實例(也稱為實體)的屬性與實例之間的關(guān)聯(lián)。
其次,兩類模型作用不同。作為概念模型,E-R圖用于幫助用戶和數(shù)據(jù)庫開發(fā)者對于應(yīng)用需求和所涉及到的數(shù)據(jù)的含義進(jìn)行正確理解的工具;而圖數(shù)據(jù)庫中的圖模型是數(shù)據(jù)庫系統(tǒng)的物理實現(xiàn)模型。
關(guān)系數(shù)據(jù)庫需要完成從E-R圖到關(guān)系表結(jié)構(gòu),以及關(guān)系表之間主外鍵的映射,圖數(shù)據(jù)庫則需要把E-R圖( Model)映射成用點和邊表示實體與實體之間關(guān)系的數(shù)據(jù)模型。
4. 關(guān)系數(shù)據(jù)庫 VS 圖數(shù)據(jù)庫
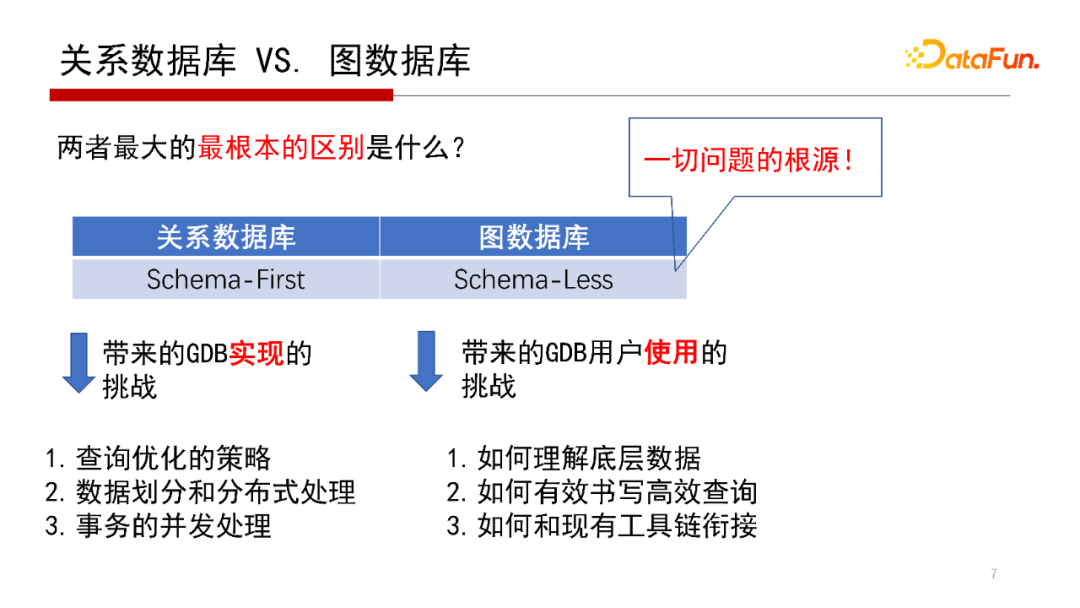
關(guān)系數(shù)據(jù)庫與圖數(shù)據(jù)庫兩者之間有什么區(qū)別呢?
首先,我想強(qiáng)調(diào)的是兩者不是替代關(guān)系,至少就目前的技術(shù)和研究的發(fā)展?fàn)顟B(tài)而言;但是兩者確實有很多區(qū)別,因此造成了在使用場景和內(nèi)核系統(tǒng)設(shè)計中的巨大區(qū)別。
這里認(rèn)為最核心的區(qū)別是,關(guān)系數(shù)據(jù)庫是Schema-First(模式優(yōu)先),圖數(shù)據(jù)庫是Schema-Less(少模式)。使用關(guān)系數(shù)據(jù)庫第一步是先建表結(jié)構(gòu)以及定義表之間主外鍵關(guān)系,這個表結(jié)構(gòu)和表之間主外鍵關(guān)系稱為Schema。關(guān)系數(shù)據(jù)庫特點是Schema-First,意思是先有表結(jié)構(gòu)才有數(shù)據(jù);圖數(shù)據(jù)庫有時候稱為Schema-Less,甚至有人認(rèn)為是Non-Schema,是Schema-Less的數(shù)據(jù),意思是導(dǎo)入的數(shù)據(jù)并不是完全與預(yù)先設(shè)計的Schema完全符合。
例如,假設(shè)描述人物信息時,有些人有10個屬性,另外一些人只有5個屬性,如果在關(guān)系數(shù)據(jù)庫中只能取兩者屬性的合集才能定義表結(jié)構(gòu);在圖數(shù)據(jù)庫當(dāng)中每個人按需(on-demand)分配屬性值就可以,以及邊表示的關(guān)系也可以是不一樣。
關(guān)系數(shù)據(jù)庫是Schema-First,也就是首先要有表結(jié)構(gòu),才能灌入數(shù)據(jù);而圖數(shù)據(jù)庫跟NoSQL有點兒相似,只要有數(shù)據(jù)來,哪怕數(shù)據(jù)并不符合前置定義的Schema,數(shù)據(jù)仍然可以灌入。
兩者的區(qū)別帶來了在實現(xiàn)和使用上的兩個大的區(qū)別:
在實現(xiàn)方面,即DBMS(數(shù)據(jù)庫管理系統(tǒng))內(nèi)核實現(xiàn)層面。傳統(tǒng)關(guān)系數(shù)據(jù)庫RDBMS的很多查詢優(yōu)化策略(即查詢引擎的執(zhí)行策略)、數(shù)據(jù)劃分和分布式的處理,以及事務(wù)的并發(fā)處理都是定義在表結(jié)構(gòu)上的,因此關(guān)系數(shù)據(jù)庫的很多技術(shù)是依賴于Schema的;而在圖數(shù)據(jù)庫中,因為沒有像關(guān)系數(shù)據(jù)庫一樣的Schema,相關(guān)的技術(shù)都需要重新考慮。這是從實現(xiàn)角度帶來的數(shù)據(jù)庫系統(tǒng)DBMS本身帶來的技術(shù)挑戰(zhàn)。
在使用方面,即用戶如何使用DBMS系統(tǒng)層面。對于使用者來說,使用關(guān)系數(shù)據(jù)庫到使用圖數(shù)據(jù)庫最重要的是概念和思維方式的轉(zhuǎn)變,關(guān)系數(shù)據(jù)庫是用表結(jié)構(gòu)理解數(shù)據(jù),圖數(shù)據(jù)庫則是以圖的思路來理解數(shù)據(jù)和數(shù)據(jù)質(zhì)量管理。另外,兩者查詢語句也不一樣,和現(xiàn)有工具鏈也存在銜接的問題。因為兩者定位不同,所以不能說圖數(shù)據(jù)庫和關(guān)系數(shù)據(jù)庫是一個替代關(guān)系,但從工具鏈角度、生態(tài)來說圖數(shù)據(jù)庫是一個新的變化。
5. 圖數(shù)據(jù)庫
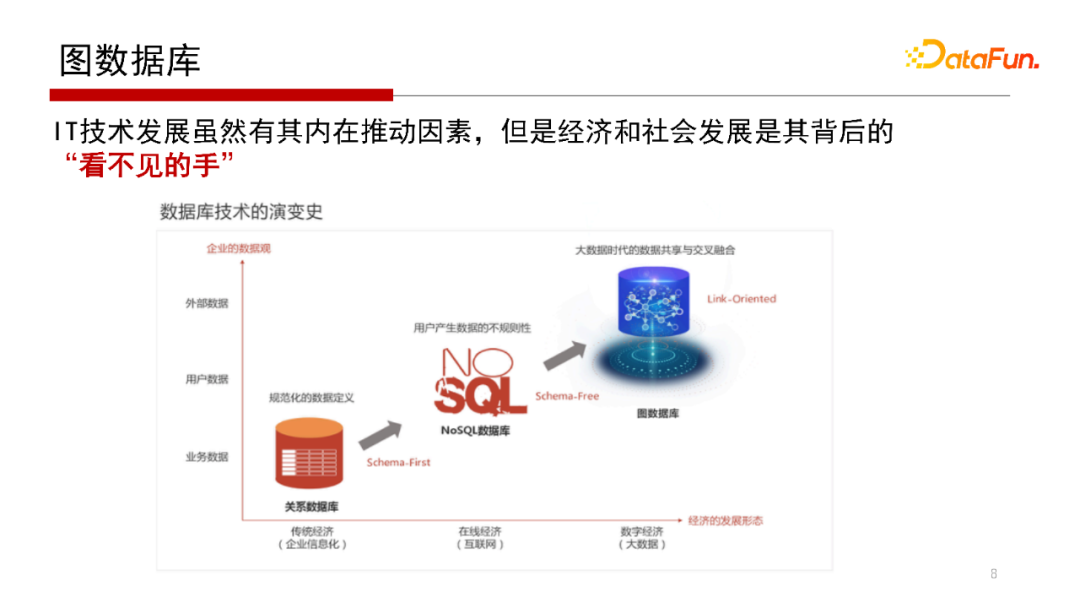
隨著研究與實踐應(yīng)用的進(jìn)行,我們越來越發(fā)現(xiàn),雖然IT技術(shù)發(fā)展有內(nèi)在的推動因素,但是經(jīng)濟(jì)和社會發(fā)展也是“無形的手”。這里我們不去詳細(xì)討論從數(shù)據(jù)管理系統(tǒng)(DBMS)早期從層次、網(wǎng)狀數(shù)據(jù)庫到關(guān)系數(shù)據(jù)庫轉(zhuǎn)變的過程。其實這個早期過程的核心解決的是如何將數(shù)據(jù)庫系統(tǒng)的應(yīng)用程序開發(fā)人員與數(shù)據(jù)庫系統(tǒng)的內(nèi)核開發(fā)人員進(jìn)行有效隔離,以提高生產(chǎn)效率的問題,這是一個軟件系統(tǒng)演化的過程:完成了從最原始的文件系統(tǒng)管理數(shù)據(jù),到構(gòu)建起一個獨立的數(shù)據(jù)庫系統(tǒng)軟件來管理數(shù)據(jù)。
這里,我們重點觀察一下從關(guān)系數(shù)據(jù)庫到近些年NoSQL再到Graph 。這一步一步轉(zhuǎn)變,并不是說完全替代,只是隨著經(jīng)濟(jì)和社會發(fā)展出現(xiàn)了NoSQL、出現(xiàn)了Graph 。這里我們也不從軟件系統(tǒng)演化的技術(shù)邏輯去做分析,而是從市場主體的企業(yè)的數(shù)據(jù)觀角度去試圖理解這點變化。前面已經(jīng)提到關(guān)系數(shù)據(jù)庫是Schema-First,其特點是需要有一個表結(jié)構(gòu),表結(jié)構(gòu)來自E-R圖,E-R圖從需求來,需求來自企業(yè)本身對這個任務(wù)有一個很清晰的業(yè)務(wù)邏輯,它適合傳統(tǒng)經(jīng)濟(jì)場景,解決的是傳統(tǒng)企業(yè)的信息化問題。傳統(tǒng)企業(yè)只有把問題信息化才有業(yè)務(wù)邏輯,才有需求,才能明確地畫出E-R圖。有了E-R圖后才可以映射成表和表結(jié)構(gòu),通常情況下這個表結(jié)構(gòu)不會做太大變化,因為關(guān)系數(shù)據(jù)庫表結(jié)構(gòu)或Schema做變化是一個非常耗時的任務(wù)。
在互聯(lián)網(wǎng)經(jīng)濟(jì)時代,數(shù)據(jù)不僅僅是企業(yè)內(nèi)部業(yè)務(wù)系統(tǒng)產(chǎn)生的,有很多數(shù)據(jù)的產(chǎn)生也不滿足提前預(yù)設(shè)的Schema,這類數(shù)據(jù)通常稱為Users Content(UGC)。這樣的數(shù)據(jù)存儲需求催生了 Key-Value為代表的NoSQL數(shù)據(jù)庫系統(tǒng),以解決在線經(jīng)濟(jì)中互聯(lián)網(wǎng)情景下用戶產(chǎn)生的數(shù)據(jù)不規(guī)則、不滿足預(yù)設(shè)Schema的數(shù)據(jù)存儲問題。
前面提到的NoSQL關(guān)注的是用戶及相關(guān)數(shù)據(jù),傳統(tǒng)關(guān)系數(shù)據(jù)庫關(guān)注的是企業(yè)的內(nèi)部業(yè)務(wù)數(shù)據(jù);而圖數(shù)據(jù)庫關(guān)注的是外部數(shù)據(jù)。在大數(shù)據(jù)、數(shù)據(jù)經(jīng)濟(jì)時代講究的是數(shù)據(jù)之間融合和關(guān)聯(lián)。因為一個企業(yè)在做業(yè)務(wù)執(zhí)行、決策判定的時候,需要大量的外部數(shù)據(jù)。在企業(yè)經(jīng)營時,需要跟其他單位做一些數(shù)據(jù)的交換,獲取一些外部數(shù)據(jù),而外部數(shù)據(jù)獲得與企業(yè)本身掌握的數(shù)據(jù)之間要完成數(shù)據(jù)的關(guān)聯(lián),而這種數(shù)據(jù)關(guān)聯(lián)以“圖”的形式表示是最為合適的;圖的點和邊之間的關(guān)聯(lián),是能夠表達(dá)數(shù)據(jù)之間深層次的語義相關(guān)性的,因此認(rèn)為圖數(shù)據(jù)庫是數(shù)字經(jīng)濟(jì)和大數(shù)據(jù)時代的一種重要的數(shù)據(jù)模型。
從上面的分析可以看出,技術(shù)的發(fā)展通常是有著經(jīng)濟(jì)和社會發(fā)展作為背后的推動和選擇因素。
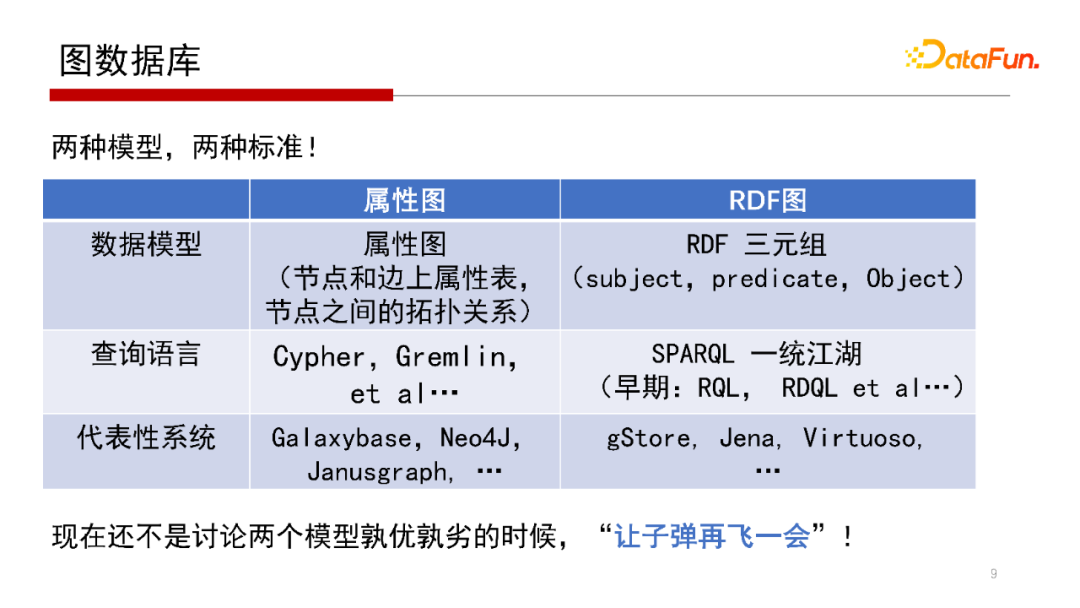
目前看,圖數(shù)據(jù)庫通常有兩大類,一種是屬性圖,另一種是RDF圖。
其中,屬性圖在節(jié)點和邊上有屬性表,從某種角度上講,它仍帶有關(guān)系數(shù)據(jù)庫的基本特性,類似表結(jié)構(gòu)的形式,實際是采用Key-Value形式來存儲的。針對屬性圖的節(jié)點和邊上的屬性表的定義,各個廠商的差別也比較大。例如有些模型中不允許同一個節(jié)點分屬不同的類別。因各個廠商有自己的查詢語言,其中查詢語言使用比較多,用戶規(guī)模比較大、有一定影響力的查詢語言包括Cypher、Apache開源項目的Gremlin等。
RDF圖全稱是--,是從語義網(wǎng)演變來的,借用了很多語義網(wǎng)的協(xié)議標(biāo)準(zhǔn),具體就是語義網(wǎng)框架下的數(shù)據(jù)語言與查詢語言的標(biāo)準(zhǔn),包括RDF三元組和SPARQL。RDF三元組表示其圖結(jié)構(gòu)是用主謂賓的形式來表達(dá)的,查詢語言是SPARQL,當(dāng)然早期語言還有RQL、RDQL等。這類圖數(shù)據(jù)庫系統(tǒng)最大的好處是協(xié)議統(tǒng)一,從數(shù)據(jù)模型到查詢語言的模型都有一套嚴(yán)格的規(guī)范標(biāo)注。代表性的系統(tǒng)包括我們北京大學(xué)數(shù)據(jù)管理實驗室(PKUMOD)的gStore系統(tǒng)、Apache開源項目Jena等。
這兩個模型孰優(yōu)孰劣,現(xiàn)在還不是很好討論,因為兩個模型各有各的優(yōu)劣。例如,語義網(wǎng)特點是比較容易支持后期的推理,而且其標(biāo)準(zhǔn)化做得比較好。而目前圖數(shù)據(jù)庫也正在做標(biāo)準(zhǔn)化的事情。評判兩個模型的優(yōu)劣也不應(yīng)該僅從技術(shù)角度做評判,因此認(rèn)為還不是評判的時候。下面我們簡單介紹一下相關(guān)模型。
6.RDF圖數(shù)據(jù)模型

RDF圖的特點是主、謂、賓表示方式,無論是表示實體、屬性還是實體與實體的關(guān)系,都用主謂賓的表示。
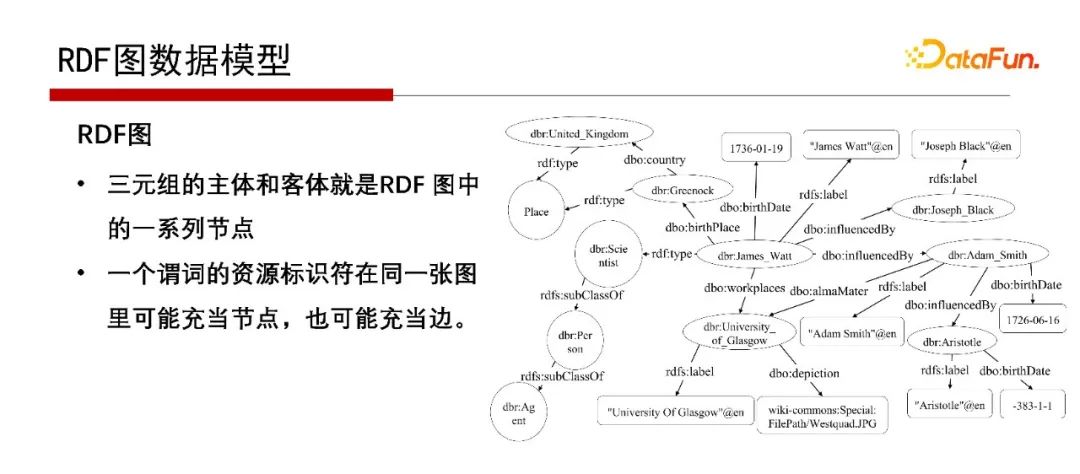
那為什么是圖的形式呢?因為主語和賓語就是兩個點,它們之間的關(guān)系就是一條邊,因此是RDF Graph;不是把RDF數(shù)據(jù)看成Graph圖,而是它本身就是Graph圖,只是它不僅可以表示成三列表的形式,也可以表示成Graph圖的形式。
7. SPARQL查詢語言

查詢語言SPARQL與SQL很像,也是一種描述性語言,具體如何執(zhí)行依賴數(shù)據(jù)庫引擎。
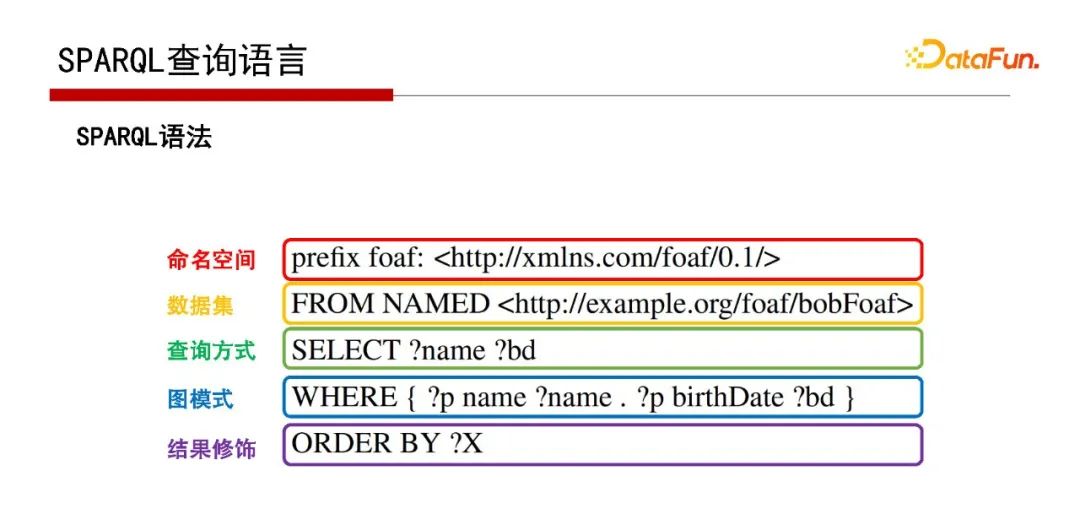
此為SPARQL查詢語言的語法示例。

除基本的圖模式外,還有復(fù)雜的圖模式,如帶有、UNION等的語句,見以上示例,這里不再贅述。
8. 屬性圖模型
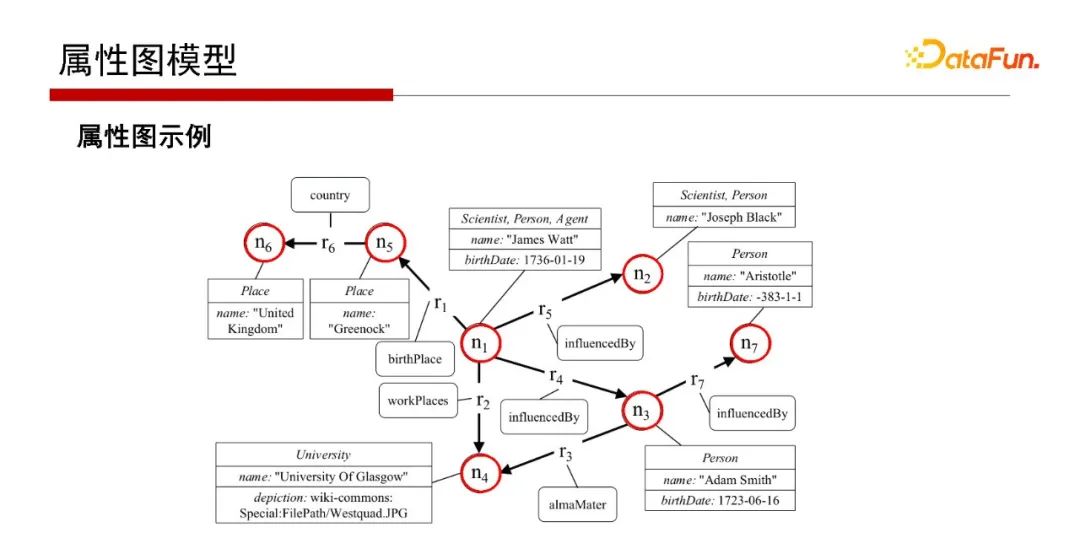
屬性圖如之前所講,其點和邊都是有屬性表的,如Person,Person的名字name、Person的;如邊r7上目前只畫了標(biāo)簽,但實際也可以是屬性表的。這是屬性圖的一個非常好的優(yōu)勢。
9.Cypher查詢語言

屬性圖的查詢語言Cypher,如示例簡單解釋一下Cypher查詢語言的含義,找到屬性圖中任務(wù)的出生地點以及受多少人影響,這個查詢語言是:
MATCH(r:Person),首先是找一個人,類型是Person,將所有的Person復(fù)制到一張中間表中,中間表的名字為r;
MATCH(r)-[:]->(pl:Person),r表中的每個記錄是否有,左連接方式,如果有,則找出;
MATCH(r)-[:*]->(p:Person),再看這些人受哪些人影響,因為帶*,則把直接影響或多跳即間接影響的人都找到。

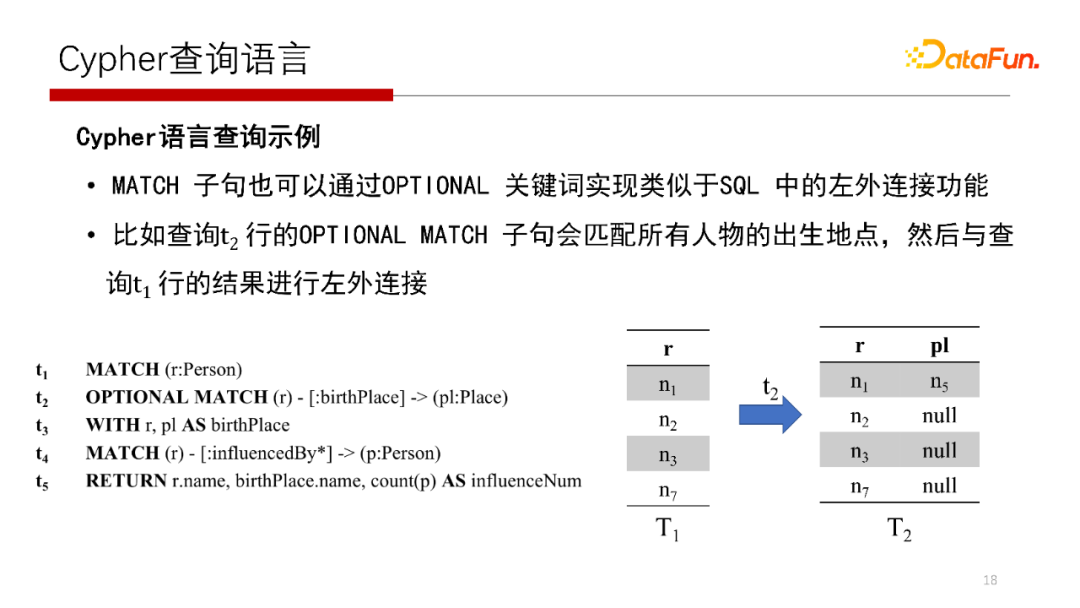

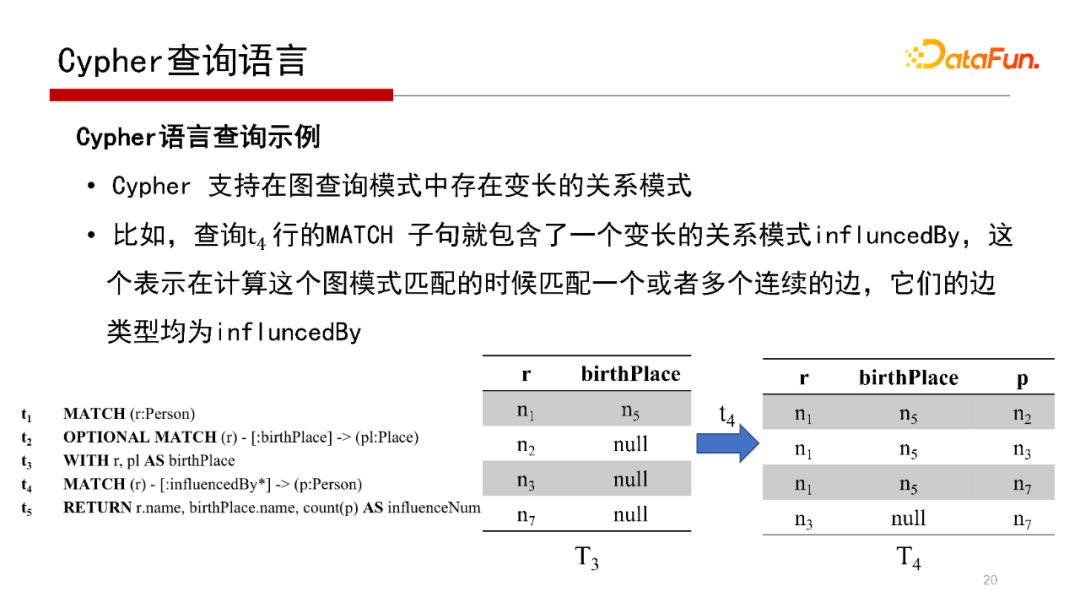
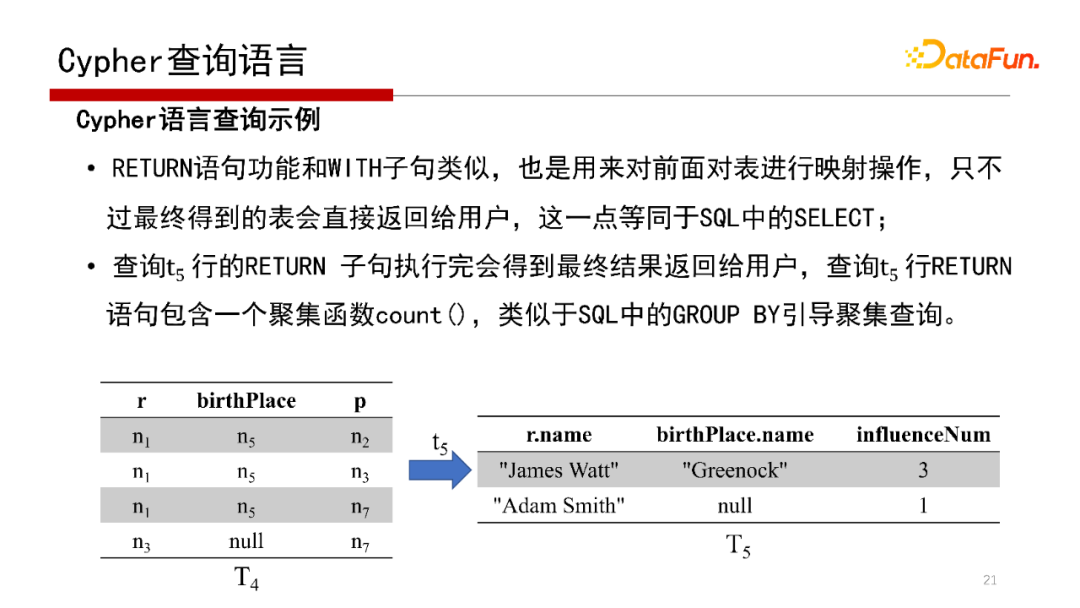
Cypher查詢語言的執(zhí)行見上圖,這里不再贅述。
02
子圖匹配查詢及其優(yōu)化方法
前面講了數(shù)據(jù)模型、數(shù)據(jù)模型的查詢語言,那與本期主題“子圖匹配”有什么關(guān)系呢?
1.子圖匹配
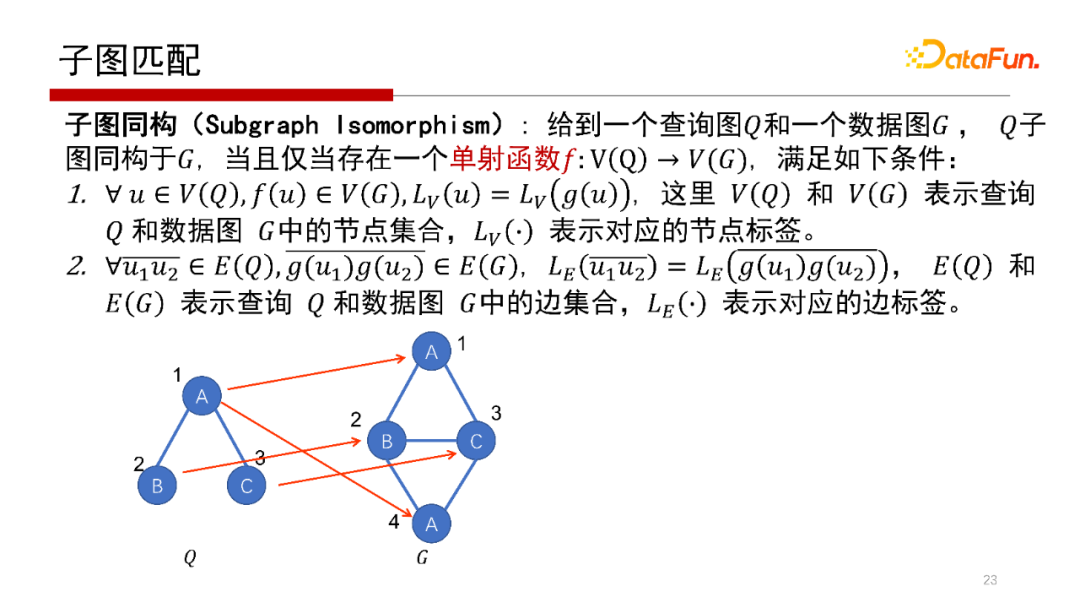
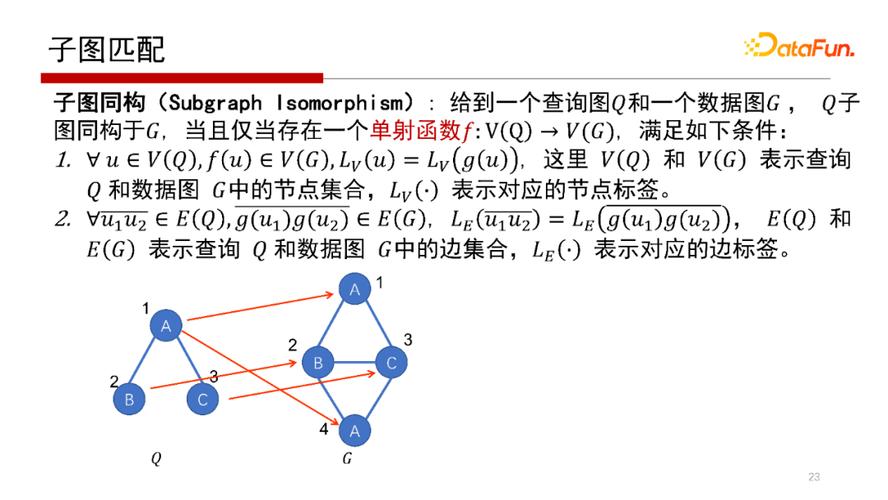
子圖匹配核心概念是給到一個查詢圖Q和一個數(shù)據(jù)圖G,Q里的每一個點通過一個單射函數(shù)映射到G當(dāng)中去,即單射函數(shù)f:V(Q)→V(G)。Q中的每一個點在單射函數(shù)(f)作用下唯一映射到G的每個點上去,如上圖中Q的1、2、3在G的中的第一個子圖匹配是(1、2、3),第二個子圖匹配是(2、3、4)。子圖匹配的本質(zhì)就是給一個Q,找到Q在G中的所有匹配,如示例中找到所有的二叉結(jié)構(gòu)。
2. 問題的復(fù)雜性

從計算復(fù)雜性來講,子圖匹配是一個非常復(fù)雜的問題。如果對查詢圖Q不加限制,子圖匹配的判定是NP-的;列舉所有的子圖匹配出現(xiàn)的位置是NP-Hard。雖然匹配算法本身是指數(shù)的,但在實踐中,可以采用大量的過濾策略來檢索搜索空間,從而提高查詢的性能。
3. 子圖匹配與圖數(shù)據(jù)庫
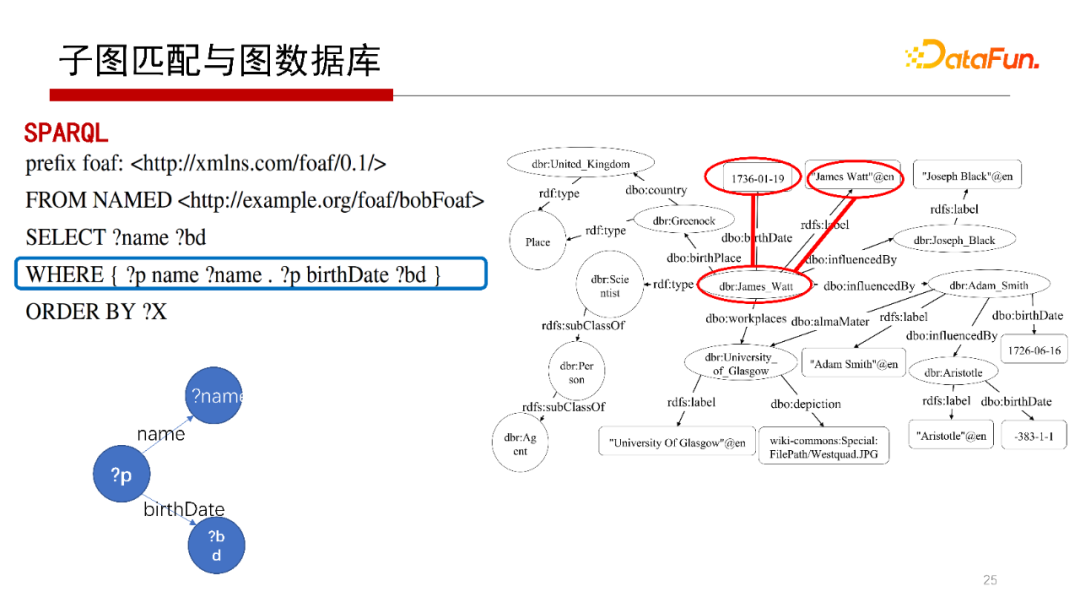
子圖匹配與圖數(shù)據(jù)庫有什么關(guān)系?
上面的SPARQL查詢的WHERE子句部分,可以表達(dá)為一個查詢圖,如這頁中的左下圖。其中帶有“?”的“?p”表示變量的含義。我們在這個例子中可以找到圖G中的子圖匹配,如紅色表示的部分。執(zhí)行上述SPARQL語句,本質(zhì)上就是Q到G的子圖匹配問題。其中,Q可能會更復(fù)雜,它不僅僅是Basic Graph Pattern(基礎(chǔ)圖模式),這個后面有機(jī)會再闡述。
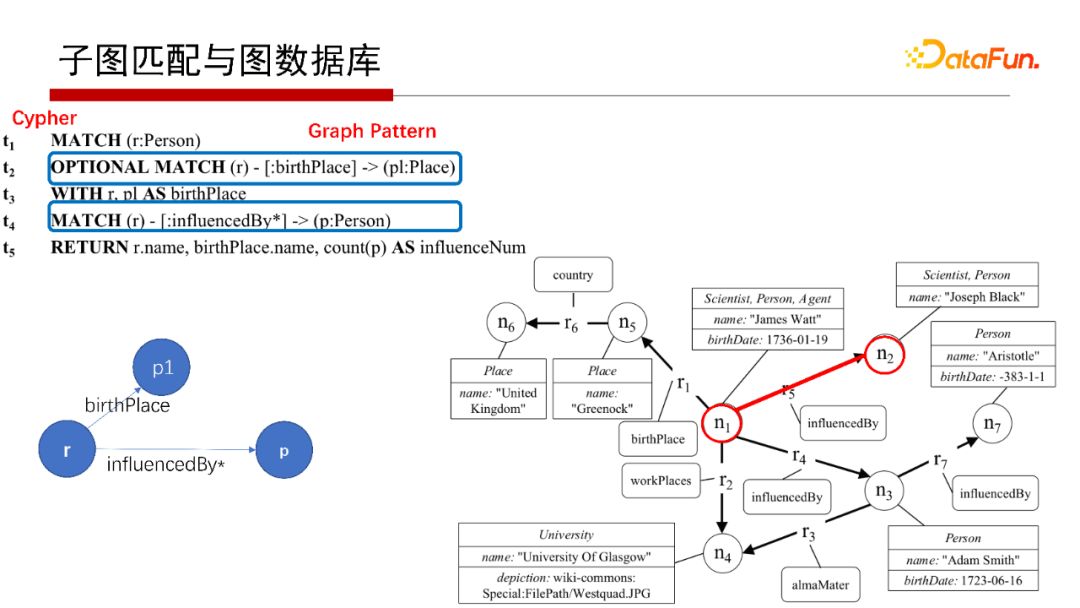
對于Cypher查詢語言也是一個子圖匹配。如上圖中 MATCH和MATCH語句,其可以表現(xiàn)為上圖中左下角的Q,在匹配右側(cè)G時,“”是匹配到節(jié)點的屬性值上去了,僅此而已,其實也是一個子圖匹配的過程。
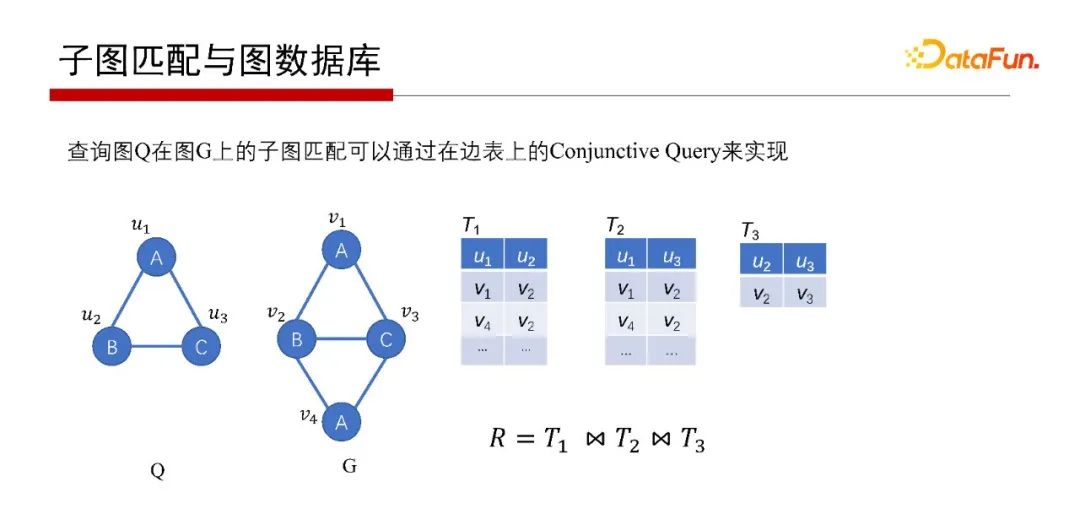
那子圖匹配如何解呢?子圖匹配問題用關(guān)系數(shù)據(jù)庫也可以解。如上圖G存在邊表里,表示邊的起點和終點。回答Q在G中的子圖匹配查詢,則分別先找到匹配查詢圖Q中的AB邊的是T1表、匹配AC邊的是T2表和匹配BC邊的是T3表,然后T1、T2、T3做自然連接(Join)操作,如果結(jié)構(gòu)非空,就找到Q的子圖匹配了。所以,如果用關(guān)系代數(shù)來解決子圖匹配的問題,則等同于關(guān)系數(shù)據(jù)庫的 Query。
4. 子圖匹配的算法
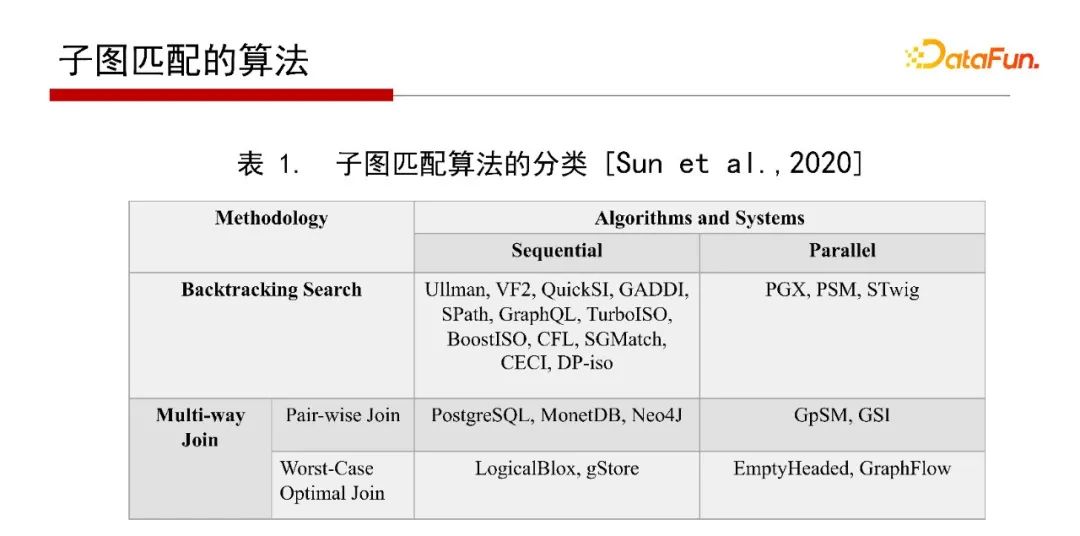
在一篇SIGMOD 2020實驗論文中指出,做子圖匹配可以有兩類算法,一類為基于深度搜索加回溯的方式( Search),一類為基于廣度優(yōu)先的Multi-way Join方法。
5. 子圖匹配的搜索空間
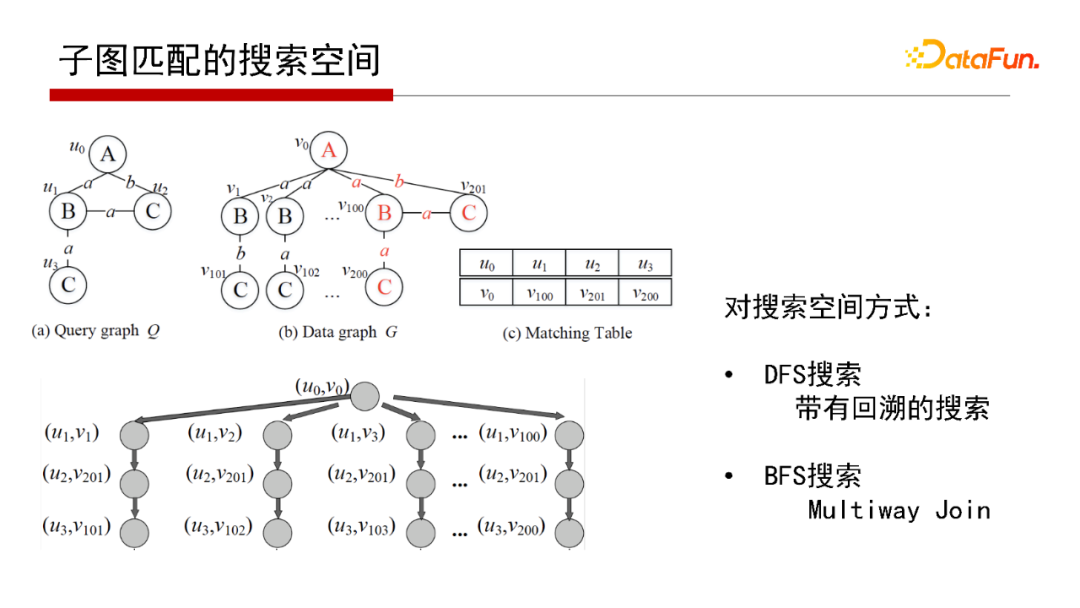
這里對子圖匹配的兩類算法形象化解釋一下。假設(shè)有個Q和一個G,找到Q在G的子圖匹配,實際就是在搜索空間查找。這里把搜索空間定義成一個搜索樹(如上圖左下角的屬性圖), Search搜索的策略是深度優(yōu)先(DFS搜索),再回溯回來;Multi-way Join搜索的策略則是寬度優(yōu)先(BFS搜索),即在搜索樹上一層一層去找。
6. 帶有回溯的搜索算法( Search)
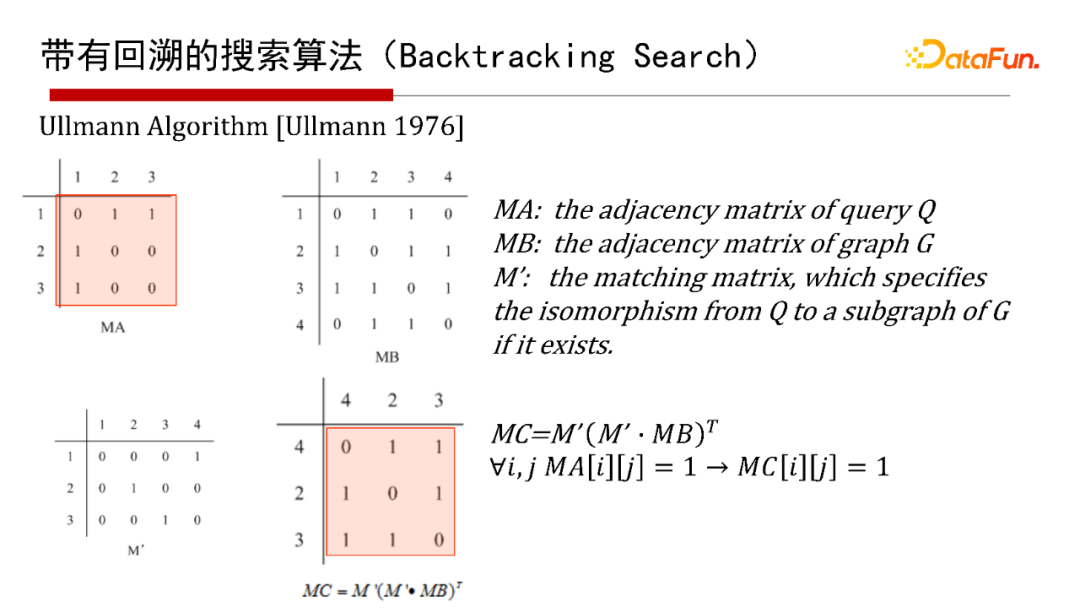

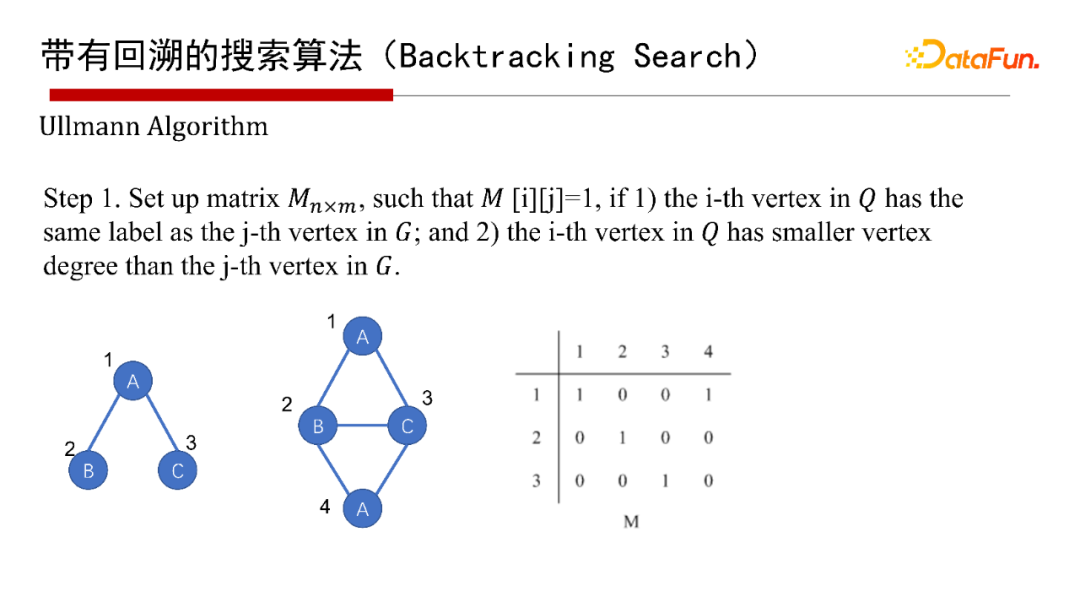

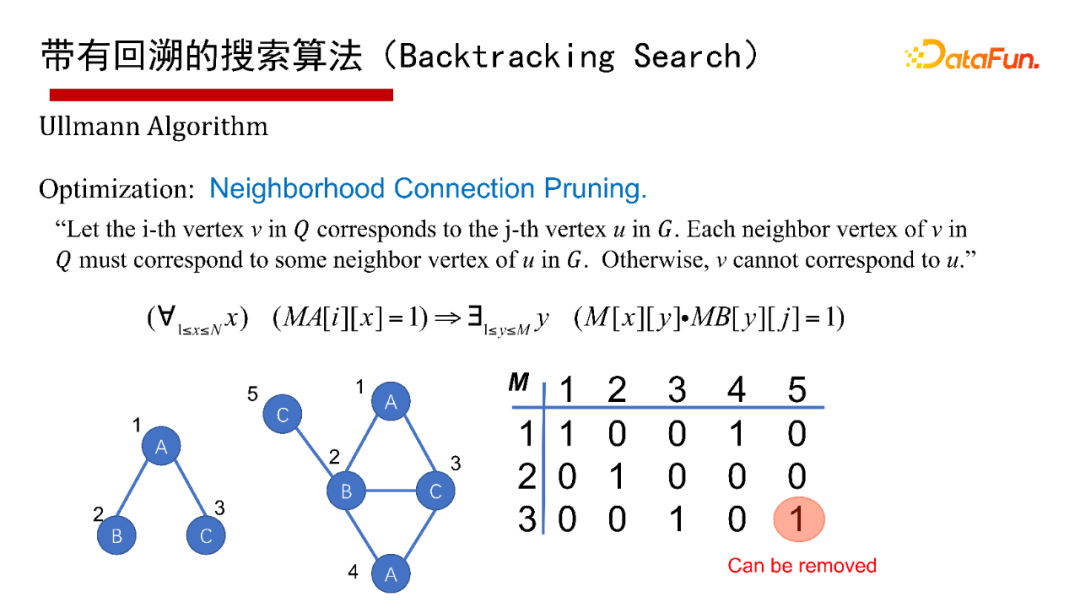
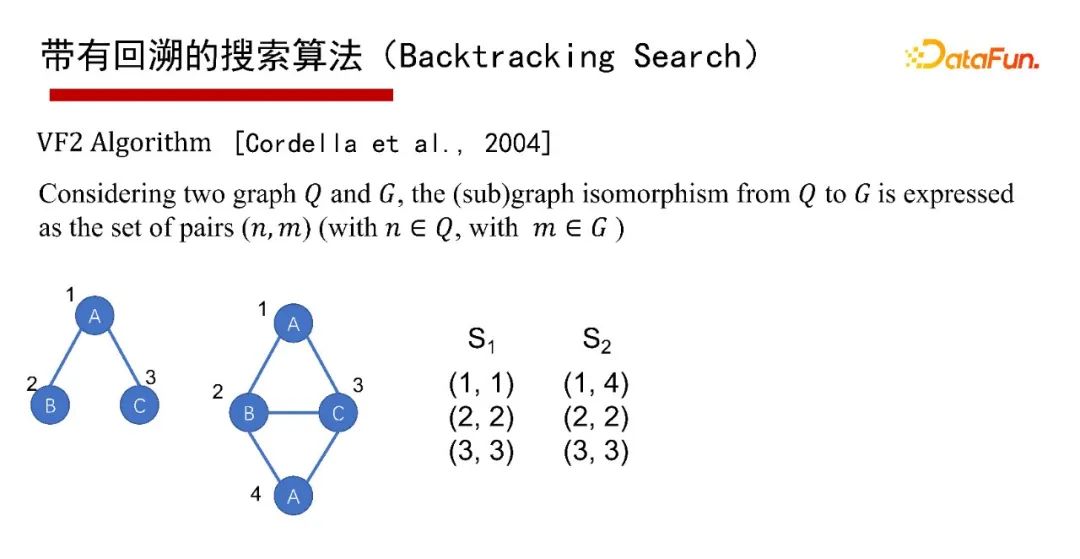
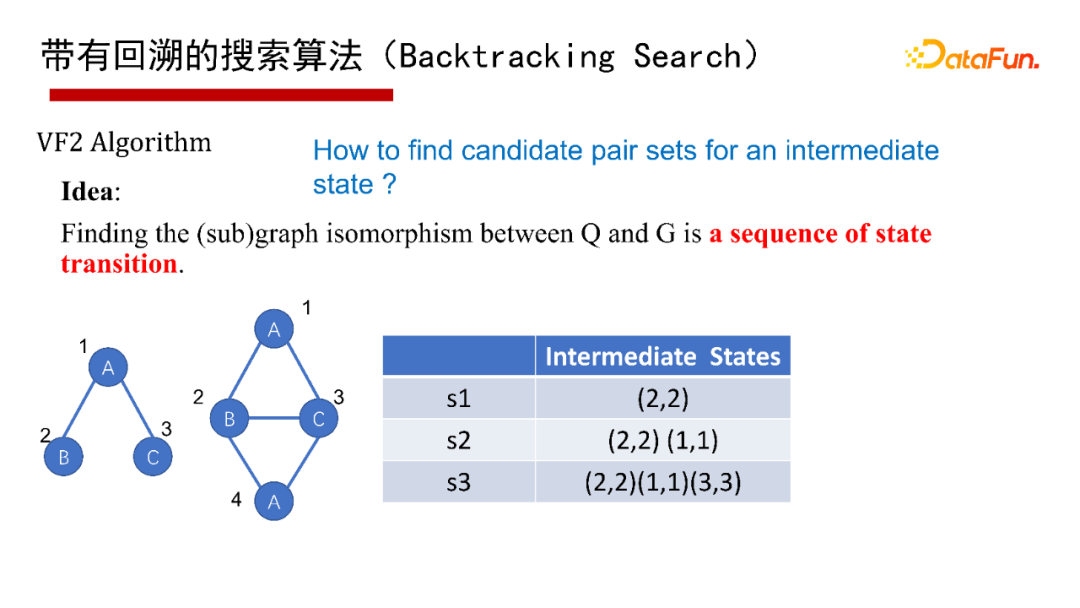
帶有回溯的搜索算法( Search),有1976年最早開始的Ullmann算法,2000年的Ullmann 算法,2004年的VF2 算法等,這里就不再具體介紹算法本身了,有興趣的同學(xué)們可以參考給出的參考文獻(xiàn)。

這里采用通用的算法框架(Common )來講講帶有回溯的搜索算法。給一個查詢圖Q,首先定義一個節(jié)點被匹配的順序,即最先匹配哪個點,然后是哪個點( a order),然后每次試圖按節(jié)點匹配順序進(jìn)行一個點一個點的匹配;如果當(dāng)前狀態(tài)匹配不了,則回溯;如果要找全部的解集,也得做回溯。其優(yōu)點是可避免產(chǎn)生大量的中間結(jié)果,因采用深度優(yōu)先,僅有遞歸調(diào)用棧的空間,沒有什么中間結(jié)果。其缺點是難以并行執(zhí)行,會有大量的遞歸開銷,因此適合做LIMIT K和TOP-K的子圖匹配查詢,即只返回K個或TOP K個結(jié)果(K很小的情況下)。
7. 基于多路連接的算法( Join)
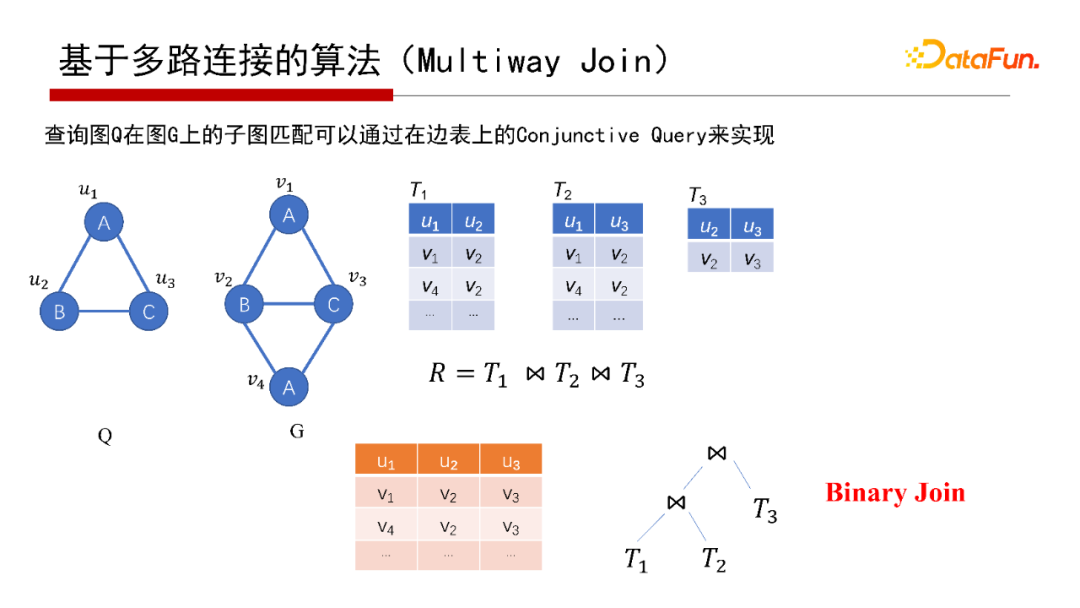
對于寬度優(yōu)先的算法,實際關(guān)系數(shù)據(jù)庫每次的Join就是寬度優(yōu)先。子圖匹配從邏輯來說是T1、T2、T3的Join操作。Join怎么執(zhí)行呢?從Join執(zhí)行角度來說,有兩種不同的執(zhí)行方案,一種是Binary Join,即第一張表T1和第二張表T2作Join,結(jié)果再與第三張表T3作一次Join,是以邊為中心。
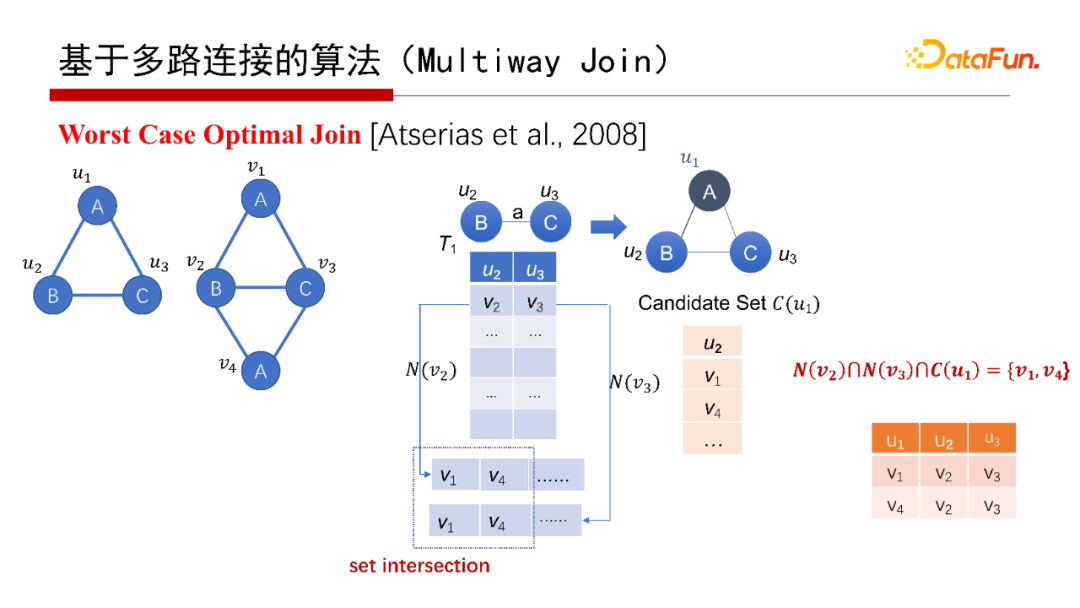
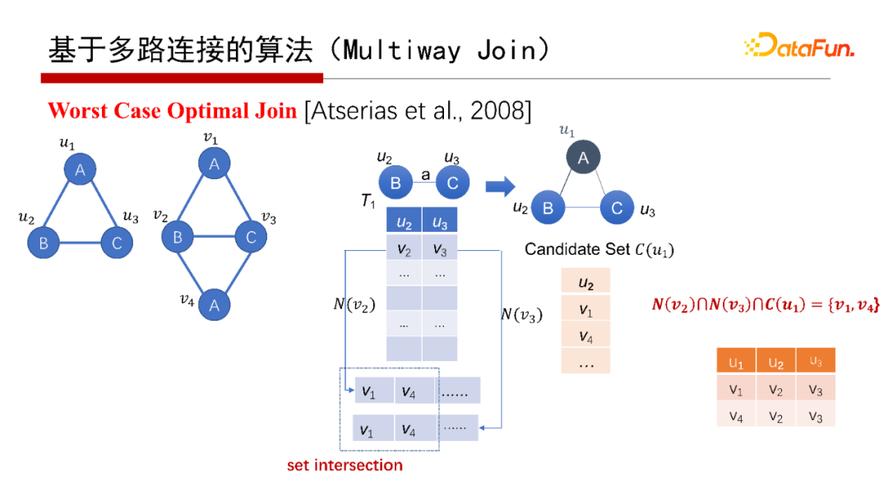
還有一種是Worst Case Optimal Join(具體可以查看給出的參考文獻(xiàn))。例如,假設(shè)已經(jīng)匹配了BC這條邊,即G中的v2和v3匹配了Q中的u2和u3,那么要找查詢圖Q的ABC的匹配,則查找G中是否有一個三角形恰好能夠匹配Q的ABC,并且三角形包含v2和v3。例如考慮中間結(jié)果表的第一行,把v2和v3的鄰居N(v2)和N(v3)找出來,然后兩個集合做一個交集set ,再和A點的候選集合C(u1)做個交集,N(v2)、N(v3)、C(u1)三個集合的交集不為空,在這個例子中交集為{ v1, v4};將其分別串聯(lián)到v2和v3后面,得到v1、v2、v3和v4、v2、v3這兩個匹配。在上面的例子中,可以對每一行都執(zhí)行該操作,因此該算法很容易做并行。

請注意上面給出的WOJ算法中,有一個很重要的操作,就是集合求交。

之所以稱之為Worst Case Optimal Join,是針對Binary Join而言,其復(fù)雜性是和它在worst case情況下的輸出結(jié)果數(shù)量相匹配的。以ABC三角形查詢圖為例,其最多有N1.5個三角形,N是邊的數(shù)目。如果用Binary Join,有可能會產(chǎn)生N2的中間結(jié)果。如果采用Worst Case Optimal Join算法,則永遠(yuǎn)不可能產(chǎn)生超過N1.5的中間結(jié)果,其運行時間的復(fù)雜性也是N1.5。對于其他的查詢圖,Worst Case Optimal Join也表現(xiàn)出該種特點。
8.Binary Join + Worst Case Optimal Join

但并不意味著Worst Case Optimal Join算法一定比Binary Join算法好。Worst Case Optimal Join算法只是保證在最差情況下比Binary Join算法好。
滑鐵盧大學(xué)做的圖數(shù)據(jù)庫系統(tǒng),就提出把Worst Case Optimal Join和Binary Join相結(jié)合,在子圖匹配的執(zhí)行選擇中既考慮Binary Join,又考慮Worst Case Optimal Join。

啟發(fā)式地講,Worst Case Optimal Join和Binary Join各有好處。Binary Join比較適合沒有環(huán)或者是樹形或者環(huán)比較稀少的查詢圖。Worst Case Optimal Join比較適合密集環(huán)形的查詢圖。因此,比較好的Join方法是依賴于查詢圖的圖結(jié)構(gòu)。
03
我們的工作
簡單介紹一下我們北京大學(xué)數(shù)據(jù)庫管理實驗室(PKUMOD)做的一些工作。
1. RDF圖數(shù)據(jù)庫
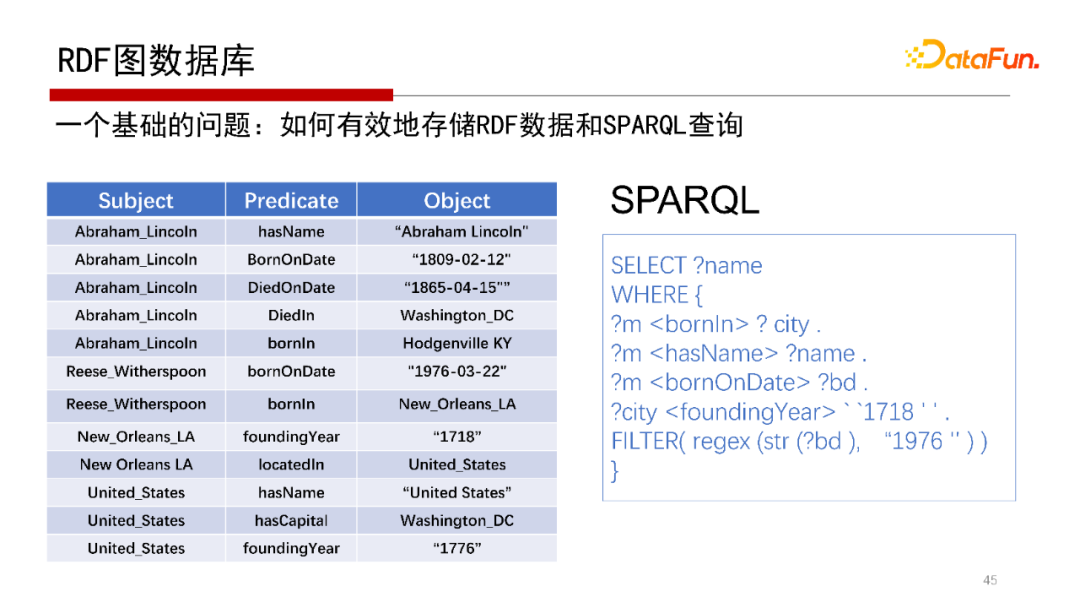
RDF圖數(shù)據(jù)庫,查詢語言是SPARQL。
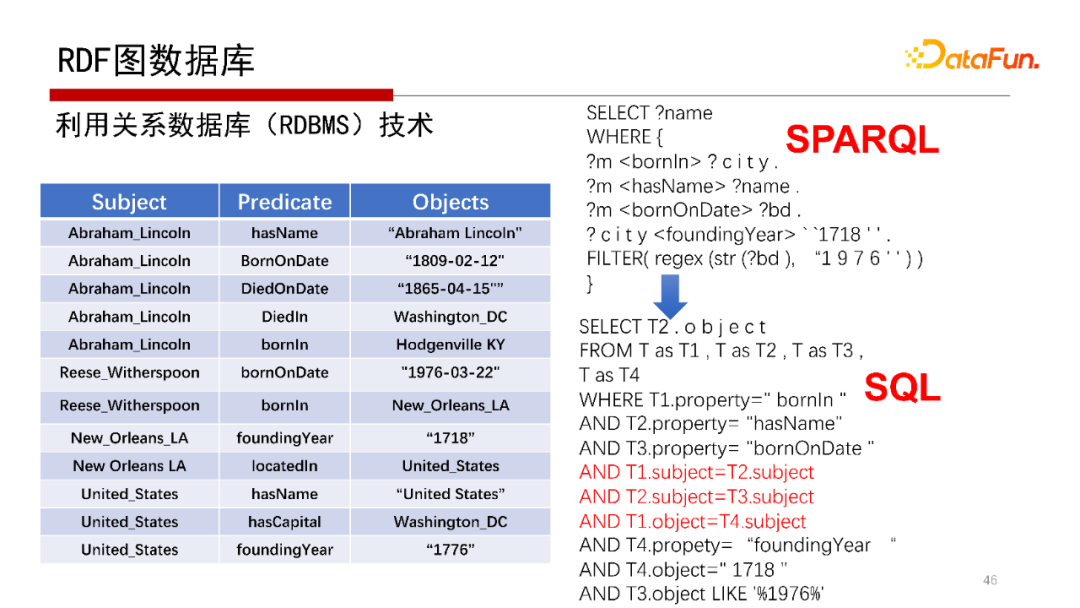
SPARQL語句也可以用關(guān)系數(shù)據(jù)庫來解。可以將SPARQL轉(zhuǎn)化為SQL語句。

然后用SQL語句去執(zhí)行,或者可以把一張大表的表結(jié)構(gòu)劃分成不同的表,仍然采用轉(zhuǎn)化成SQL語句,類似關(guān)系數(shù)據(jù)庫一樣去查詢,如Oracle、DB2最新的版本支持RDF,就是用這種方法去做的。但該方法的Join會很多,性能會非常低。
2. gStore[Zou et al.,2011]
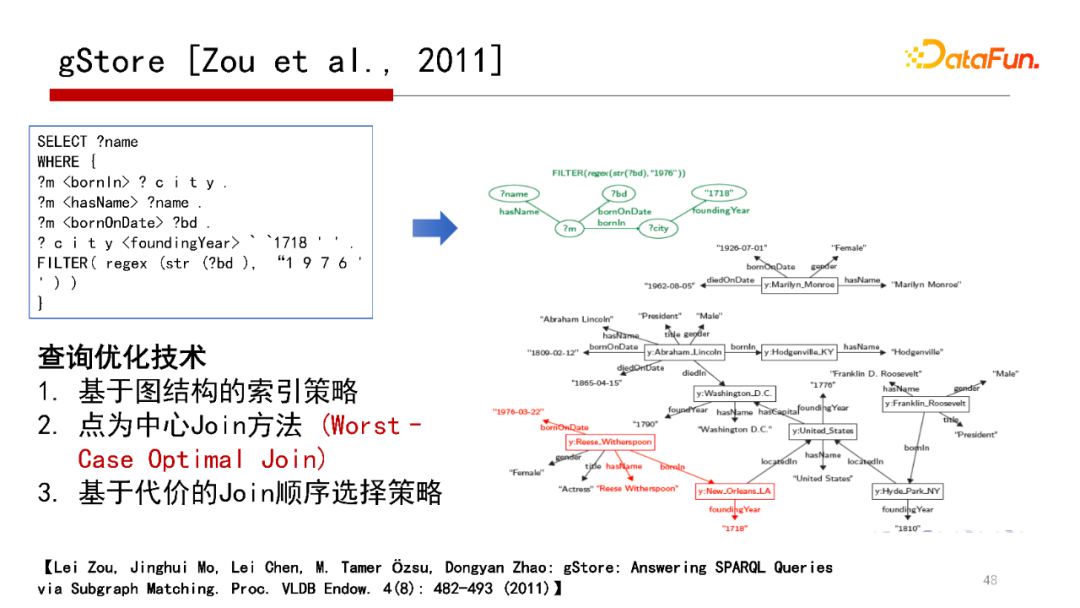
我們在2011年有一篇發(fā)在VLDB的工作“gStore: SPARQL Queries via .”,給一個SPARQL,把它Match到一個查詢圖Q,那么回答SPARQL就是在Data Graph中找到查詢圖Q的匹配,如果能找到,那么就能很快回答SPARQL,這是gStore系統(tǒng)最核心的思路。
gStore系統(tǒng)思路從技術(shù)層面,在索引的方式、Join的策略和Join順序的選擇提出了三種查詢優(yōu)化方式。在原來的系統(tǒng)版本中,采用的是以點為中心的策略,類似Worst Case Optimal Join,沒有用Worst Case Optimal Join和Binary Join合在一起的。但在即將發(fā)布的1.0版本,則考慮了Worst Case Optimal Join 加 Binary Join合在一起的策略。
gStore的開源項目官網(wǎng)在,里面有詳細(xì)的使用文檔,在gitHub和gitee(碼云在線)上面都有g(shù)Store的源碼;同時我們也有個在線 gStore 云平臺(),大家可以免安裝直接使用。
3. 分布式gStore[Pengu et al.,2016]
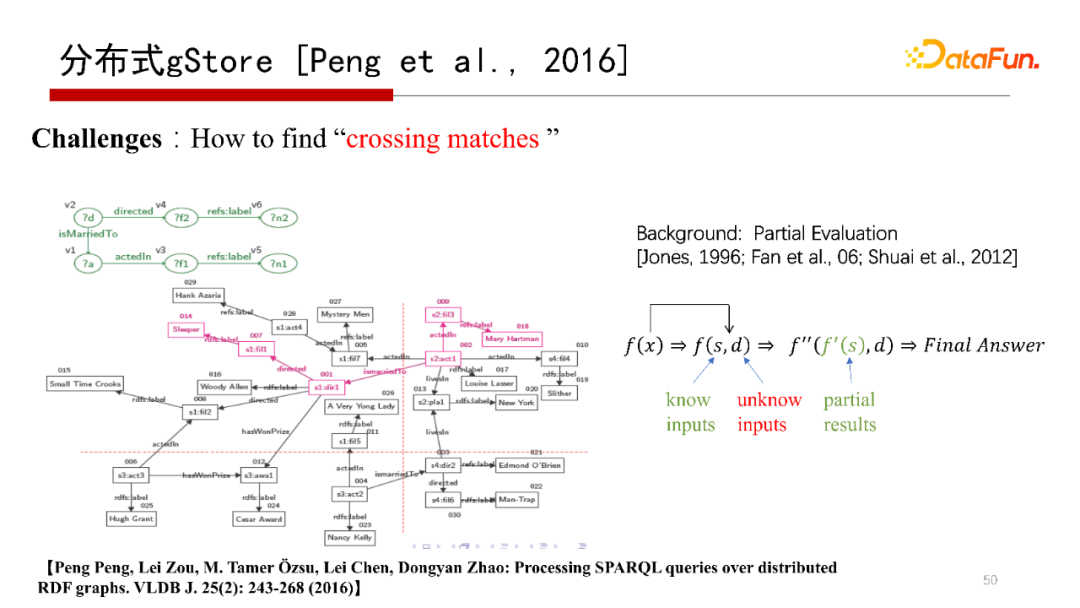
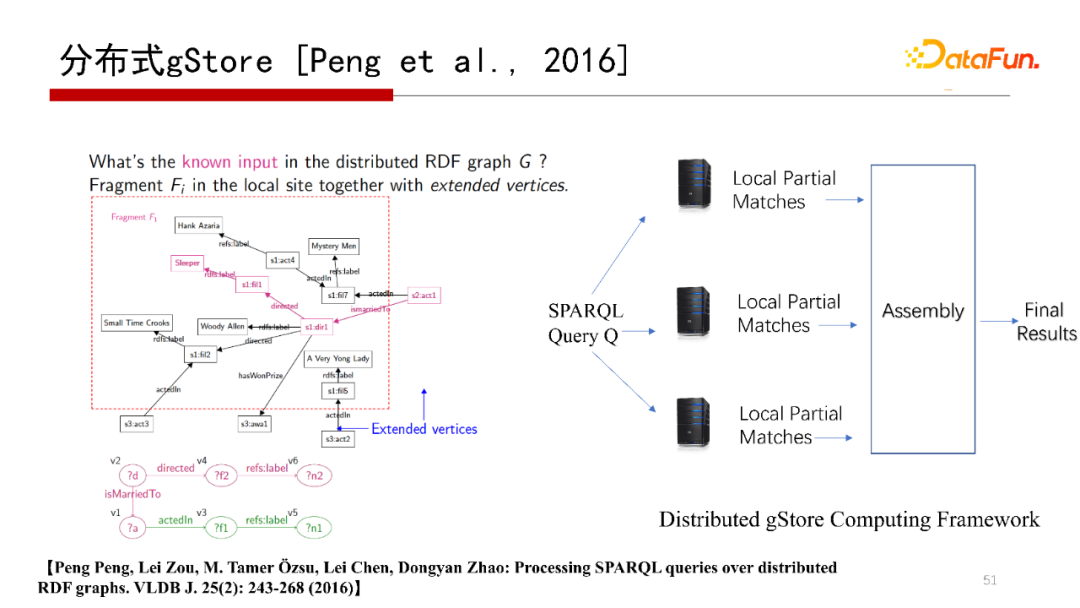
下面提到的是分布式gStore系統(tǒng),解決的是單機(jī)存儲不下一個大的RDF圖,需要分布式存儲在多個機(jī)器上,而查詢結(jié)果跨在多臺機(jī)器上的問題。我們在VLDB Journal 2016的一篇文章“ SPARQL queries over RDF graphs”有介紹分布式gStore。
4.優(yōu)化原子操作-Set

前面提到在做 Worst Case Optimal Join 時最重要的是集合求交操作。集合求交是子圖匹配中很重要的算子操作,那么集合求交怎么加速呢?
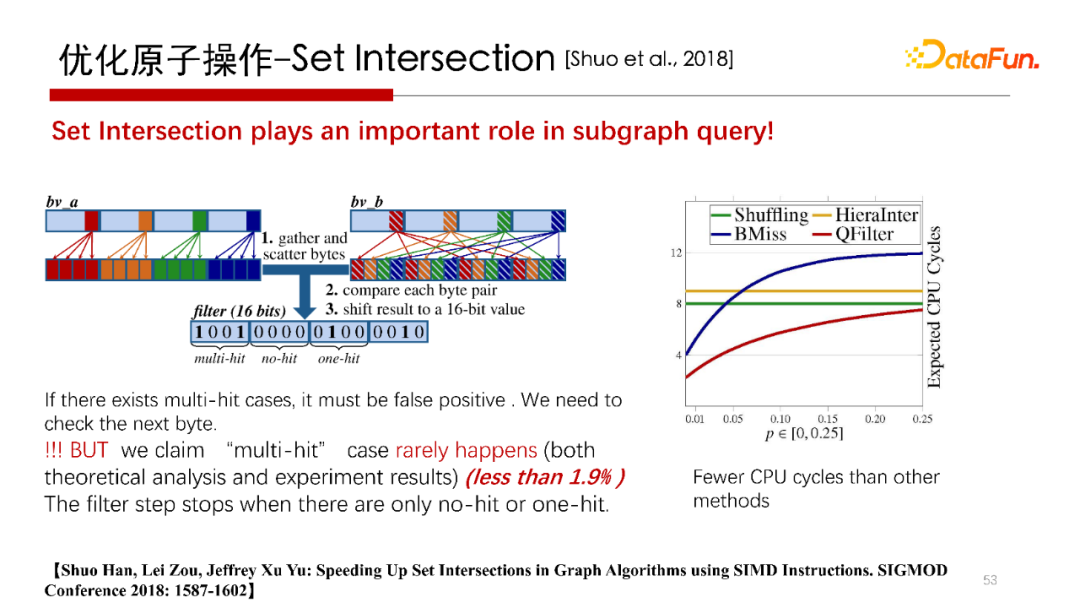
我們在2018年SIGMOD上面發(fā)表的“ Up Set in Graph using SIMD ”文中,提出了一種利用 CPU 的 SIMD(單指令多數(shù)據(jù)流)向量計算方法,通過設(shè)計一種精巧的數(shù)據(jù)布局(Data Layout)策略,可以降低對集合求交中CPU運行的Cycles的數(shù)目。
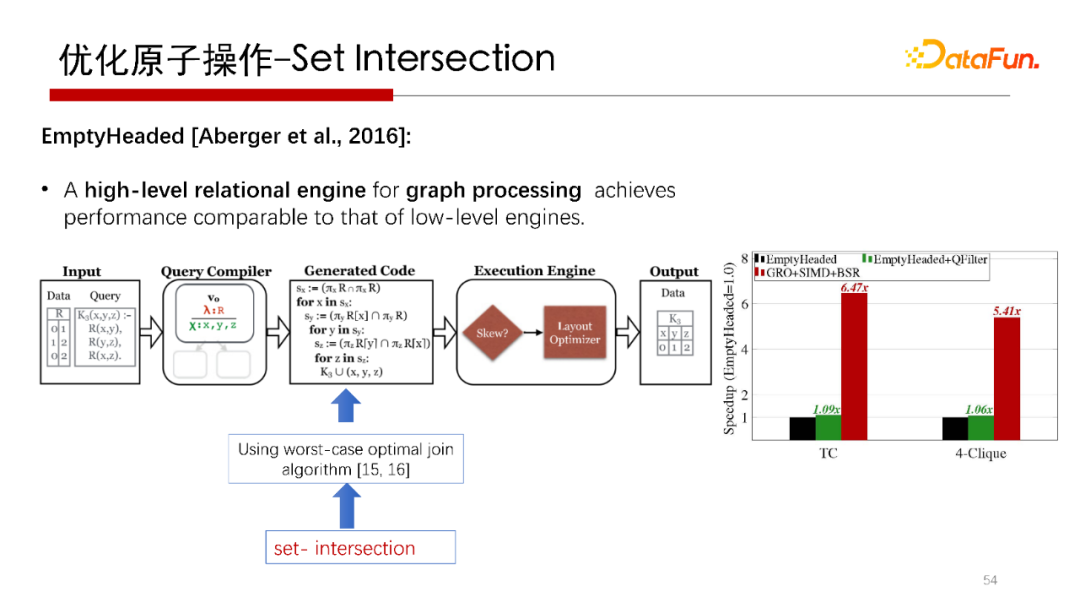
做的開源的圖處理引擎(graph )系統(tǒng),也是用Worst Case Optimal Join做的,在其系統(tǒng)中,將我們研究的集合求交優(yōu)化算法替換之后,發(fā)現(xiàn)性能有比較明顯的提升。
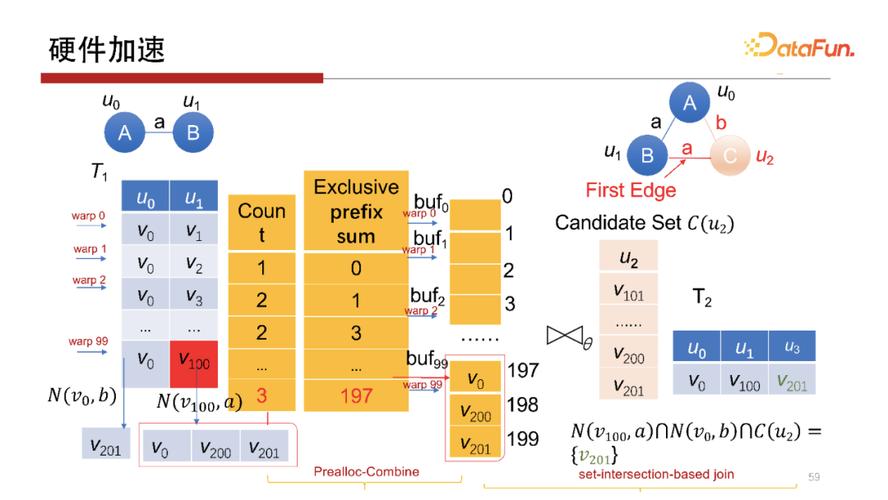
5. 硬件加速
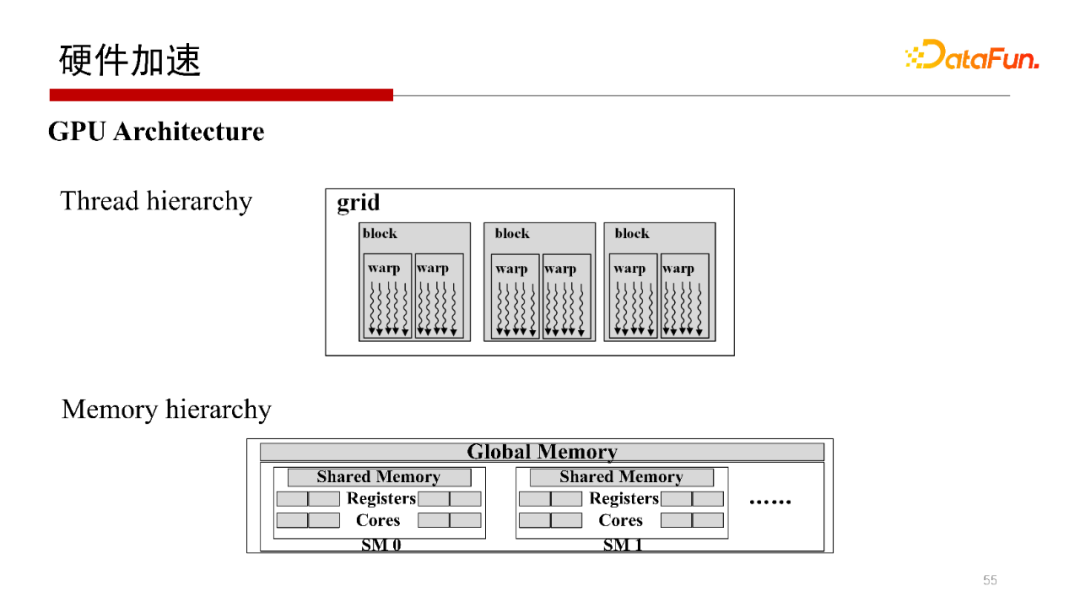

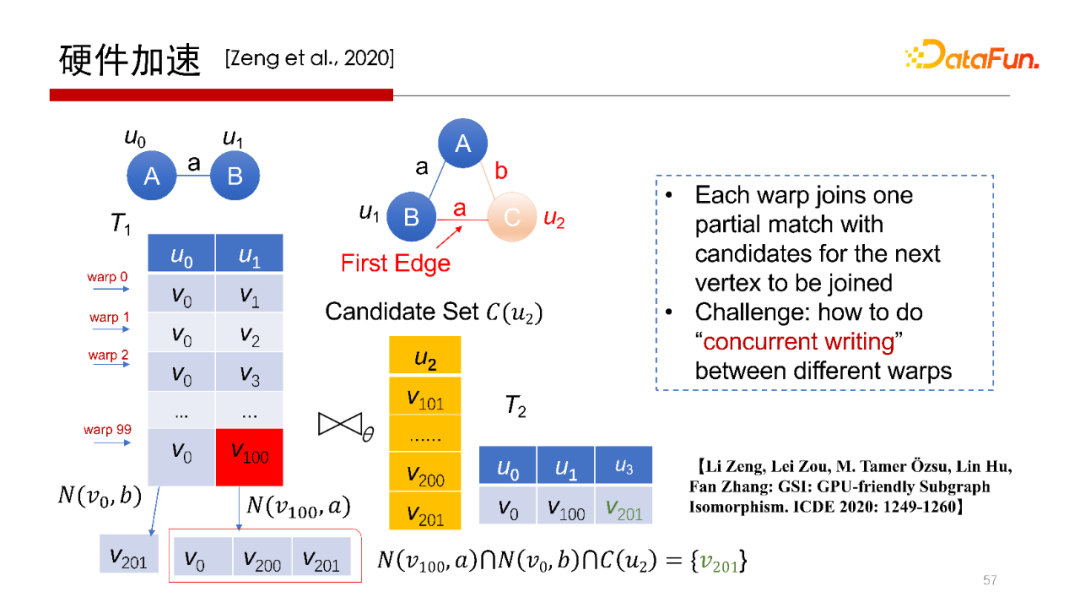
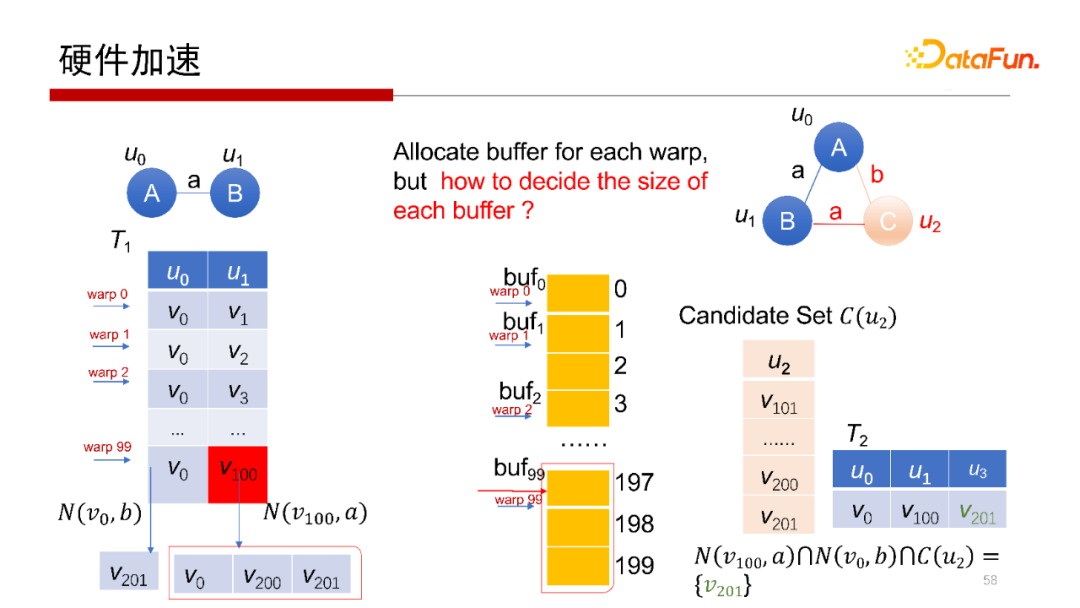
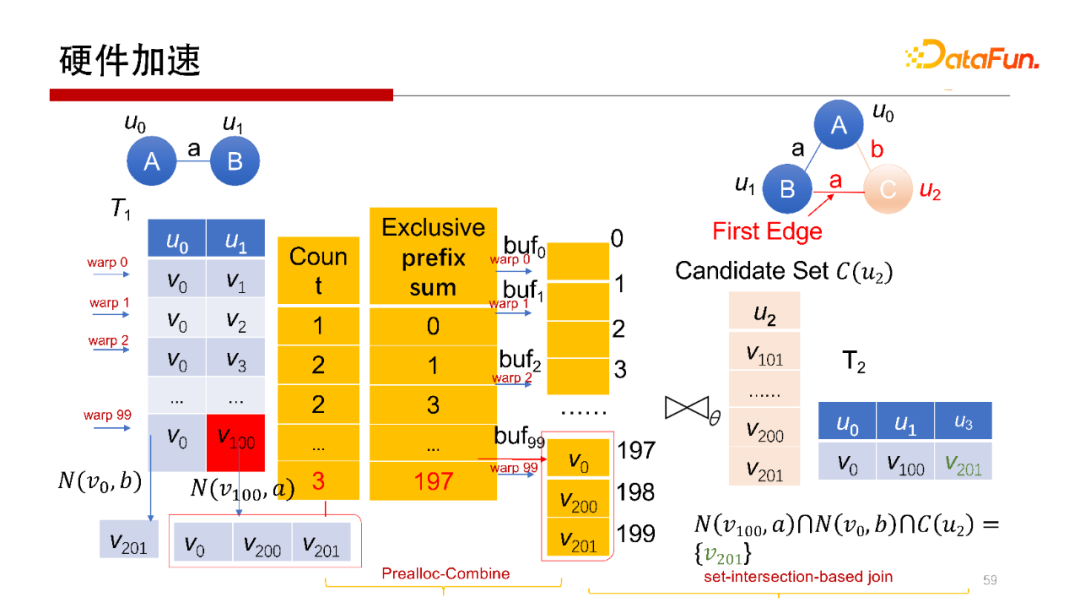
剛才提到,Worst Case Optimal Join算法,每一行是完全獨立的查詢操作,非常容易做并行。所以會想到使用在GPU上運行操作。但在GPU上執(zhí)行操作,其每個線程或每個wrap做計算沒有問題,但中間結(jié)果如何寫回去,如何避免寫沖突是需要考慮的。我們提出一種方案使得每一個wrap獨立地去執(zhí)行,并且可以獨立地去寫,在不需要加鎖的方式下不會產(chǎn)生寫沖突。
6. 總結(jié)

最后,總結(jié)一下:首先介紹了什么是圖數(shù)據(jù)庫以及我們對圖數(shù)據(jù)庫的一些思考;第二個重點關(guān)注查詢引擎組件的工作,子圖匹配和查詢引擎之間的關(guān)系;第三個是對我們北京大學(xué)數(shù)據(jù)管理實驗室(PKUMOD)的相關(guān)研究工作的介紹。


以上是一些參考文獻(xiàn)。

這是我們組的一個公眾號“圖譜學(xué)苑”和gStore圖數(shù)據(jù)庫官網(wǎng)信息,大家有興趣可以關(guān)注一下。謝謝大家。
優(yōu)設(shè)專訪張曉翔!騰訊電腦管家視覺負(fù)責(zé)人的UI自學(xué)之路

編者按:今天的訪談人物@張曉翔同學(xué)們都耳熟能詳了,自學(xué)成才的UI設(shè)計大神,追波收贊人氣高手,做過策劃、平面設(shè)計、甚至是建筑燈光設(shè)計,現(xiàn)在是騰訊電腦管家視覺設(shè)計的Leader,關(guān)于他那些不為人知的自學(xué)經(jīng)歷和設(shè)計經(jīng)驗,全在這篇專訪里邊咯。
先給大家介紹下張曉翔老師:
畢業(yè)于同濟(jì)大學(xué),08年12月至2010年7月在創(chuàng)業(yè)公司做過策劃,平面設(shè)計師,建筑燈光設(shè)計(建筑外立面燈光,景觀燈光等);
2010年8月至2011年8月在威鋒網(wǎng)()任設(shè)計師,處理所有視覺,平面,視頻相關(guān)的設(shè)計和創(chuàng)意;
2011年9月至2013年6月在E人E本做手寫平板電腦界面設(shè)計;
2013年7月入職騰訊,目前在騰訊MIG桌面安全產(chǎn)品部,任高級視覺設(shè)計師一職,為騰訊電腦管家產(chǎn)品線的視覺設(shè)計負(fù)責(zé)人。
———————————————職業(yè)篇 ———————————————
1,作為一個無證大神,您的自學(xué)經(jīng)歷是怎樣的?自學(xué)的過程中,有想特別感謝的人木有?
答:自學(xué)的動力主要來自于興趣,我從小就愛折騰電子產(chǎn)品,剛上大專那會兒市面上慢慢出現(xiàn)了可以更換主題的功能機(jī)。以前手機(jī)不像現(xiàn)在的智能機(jī),換個主題非常方便,而是需要一些特殊工具通過刷機(jī)的方式把主題刷進(jìn)去……有點扯遠(yuǎn)了,簡單說,我是通過給手機(jī)換主題,慢慢接觸UI這行的。
最初,先是自己學(xué)著換別人做的主題,后來慢慢發(fā)展成自己試著用PS改一改自己喜歡的主題,在網(wǎng)上搜靈感和素材的過程中發(fā)現(xiàn)了一個叫的網(wǎng)站,才知道原來還有另外一片天空。上面聚集了很多給Windows做過主題的牛人,這個網(wǎng)站還組織過多期 世界性質(zhì)的主題比賽,記得當(dāng)時國內(nèi)不少前輩還拿過獎,令人印象深刻的有JJ.Ying的Edisso,Azenis,Andraw(大師現(xiàn)在在騰訊已經(jīng)是專家級別的總監(jiān)了)的Rounder,還有的The Mayan 。前年身在騰訊乃哥的組在招人,我認(rèn)出之后果斷去了,成了我的Leader,現(xiàn)在這位大神升總監(jiān)了,在廣州帶手機(jī)管家團(tuán)隊,又扯遠(yuǎn)了……他們當(dāng)年的作品讓我對GUI產(chǎn)生了極大的好奇心和興趣,現(xiàn)在回想起來依然覺得他們很牛,望塵莫及。這里我特別感謝一下JJ.Ying,除了他的作品有對我產(chǎn)生積極的影響以外,我的也是他邀請我的,一路上沒有他的幫助和影響,恐怕我還在從事其他方面的設(shè)計工作。
關(guān)于JJ YING大神的訪談:《優(yōu)設(shè)訪談!百度設(shè)計大咖JJ YING的自學(xué)成才之路》

△ 曉翔老師過往作品
2,在08年那段從策劃轉(zhuǎn)平面設(shè)計再到建筑燈光設(shè)計的經(jīng)歷中,是什么讓您下決心做UI的?
答:剛畢業(yè)那會兒還是想多嘗試一些不同的工作方式,那時候并不知道自己到底想要什么,于是就不斷的嘗(跳)試(槽),差不多做到自己上班像上墳一樣時候就換地兒。去E人E本之前基本是一年一跳,來了騰訊之后才算安穩(wěn)下來。上個問題我有提到過,主要是興趣驅(qū)動,畫圖標(biāo)畫界面做Demo時我可以不吃飯不睡覺,像打了雞血一樣,如果沒有興趣和激情,一個正常人類肯定不會這樣。所以,并不能說我下了決心,而是嘗試了多個方向之后,還是打算重拾上學(xué)時的愛好,當(dāng)然,也不是說之前的經(jīng)歷都沒用,起碼我知道這些做過的方向都不適合我。
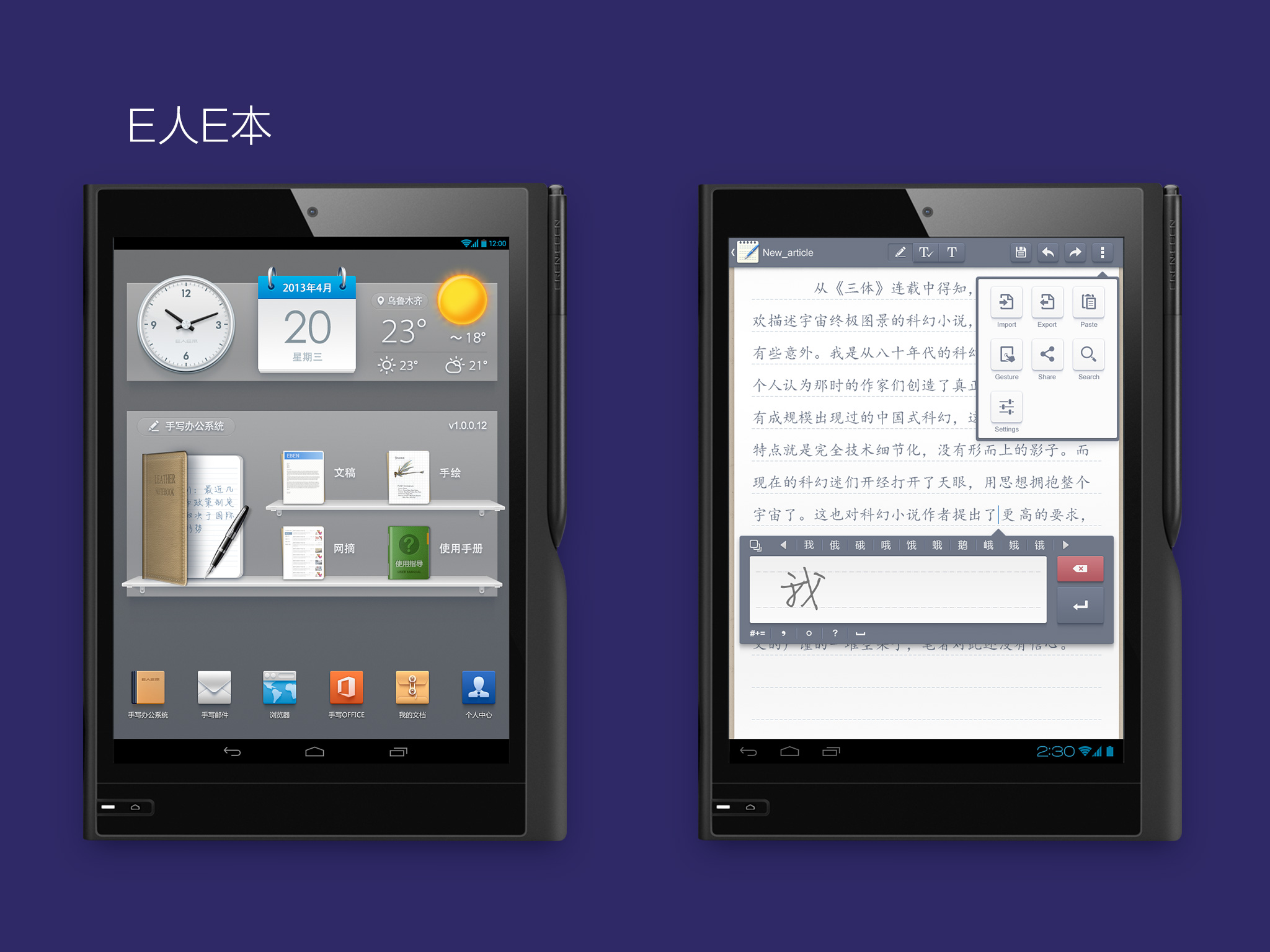
△ 在E人E本的作品

3,您目前在騰訊MIG桌面安全產(chǎn)品部承擔(dān)的職責(zé)是?
答:主要負(fù)責(zé)騰訊電腦管家這個產(chǎn)品線的設(shè)計,加速小火箭,電腦管家Mac版,游戲加速,一些內(nèi)部的創(chuàng)新線項目,例如之前的全民Wi-Fi也屬于我負(fù)責(zé)的范疇。
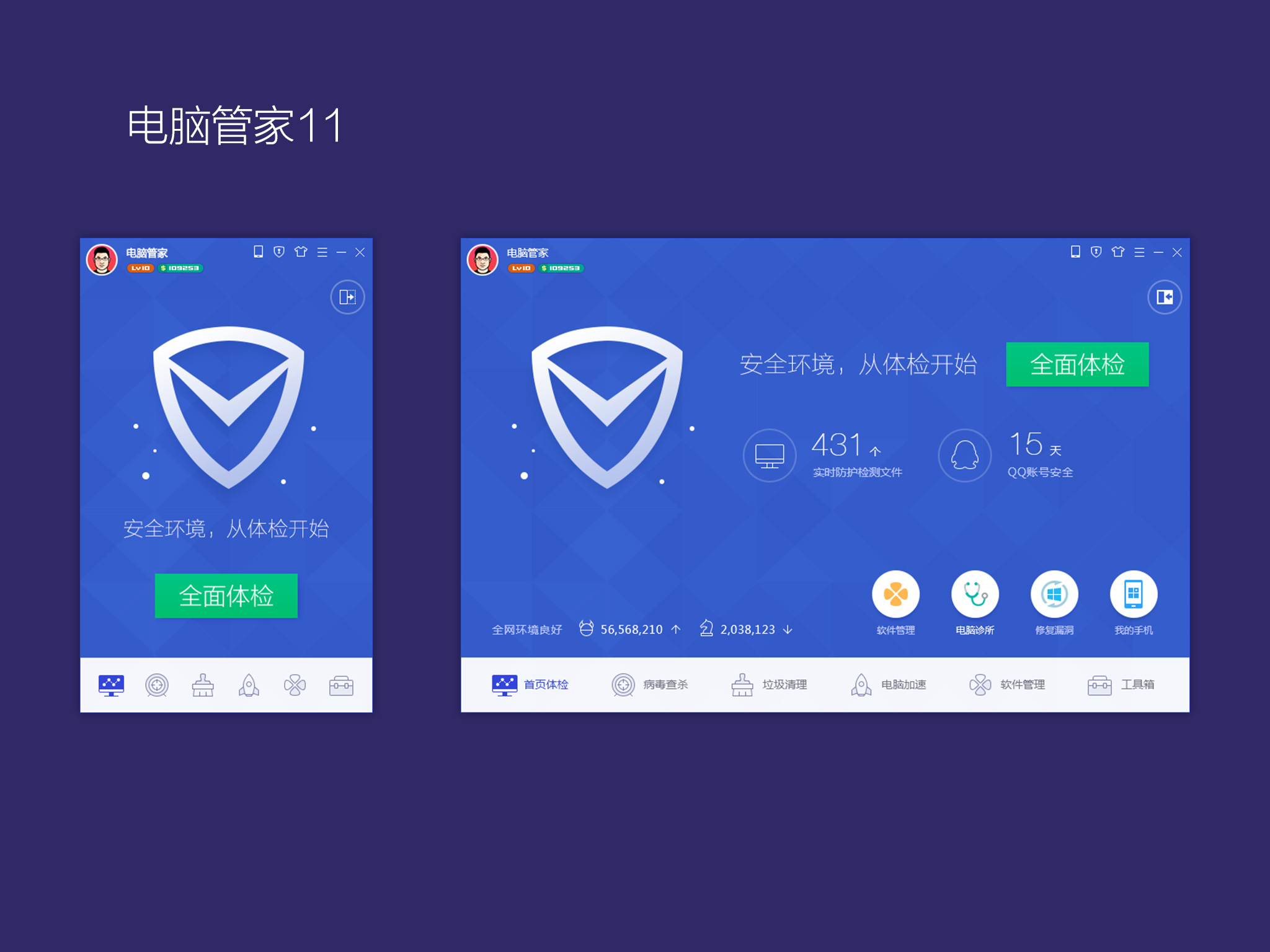
△ 騰訊管家11版界面

△ 全民Wi-Fi
4,騰訊電腦管家從8.0版本到8.8版本變化巨大,與大多數(shù)殺毒軟件的界面設(shè)計截然相反,能否聊聊您當(dāng)時的設(shè)計思路?是如何突破以往經(jīng)驗的?
答:先說背景,電腦管家8.0當(dāng)時存在幾個問題:
與市面上的競品差異度不足,大家都長得差不多。大量的信息呈現(xiàn),使用戶無法搜尋和聚焦自己想要使用的功能。普遍用戶認(rèn)為,界面大內(nèi)容多,軟件本身運行速度就很慢。
所以我們要解決的問題就是,減輕體驗的沉重感,聚焦核心功能,與競品拉開差異度。先鋒版(8.8)的設(shè)計方向基本是按照這句話做的延伸。從零開始,重新梳理框架層,放大感知設(shè)計,情感化設(shè)計,從先鋒版開始我們就加入了大量的交互動畫,目的就是為了進(jìn)一步與競品拉開差距。
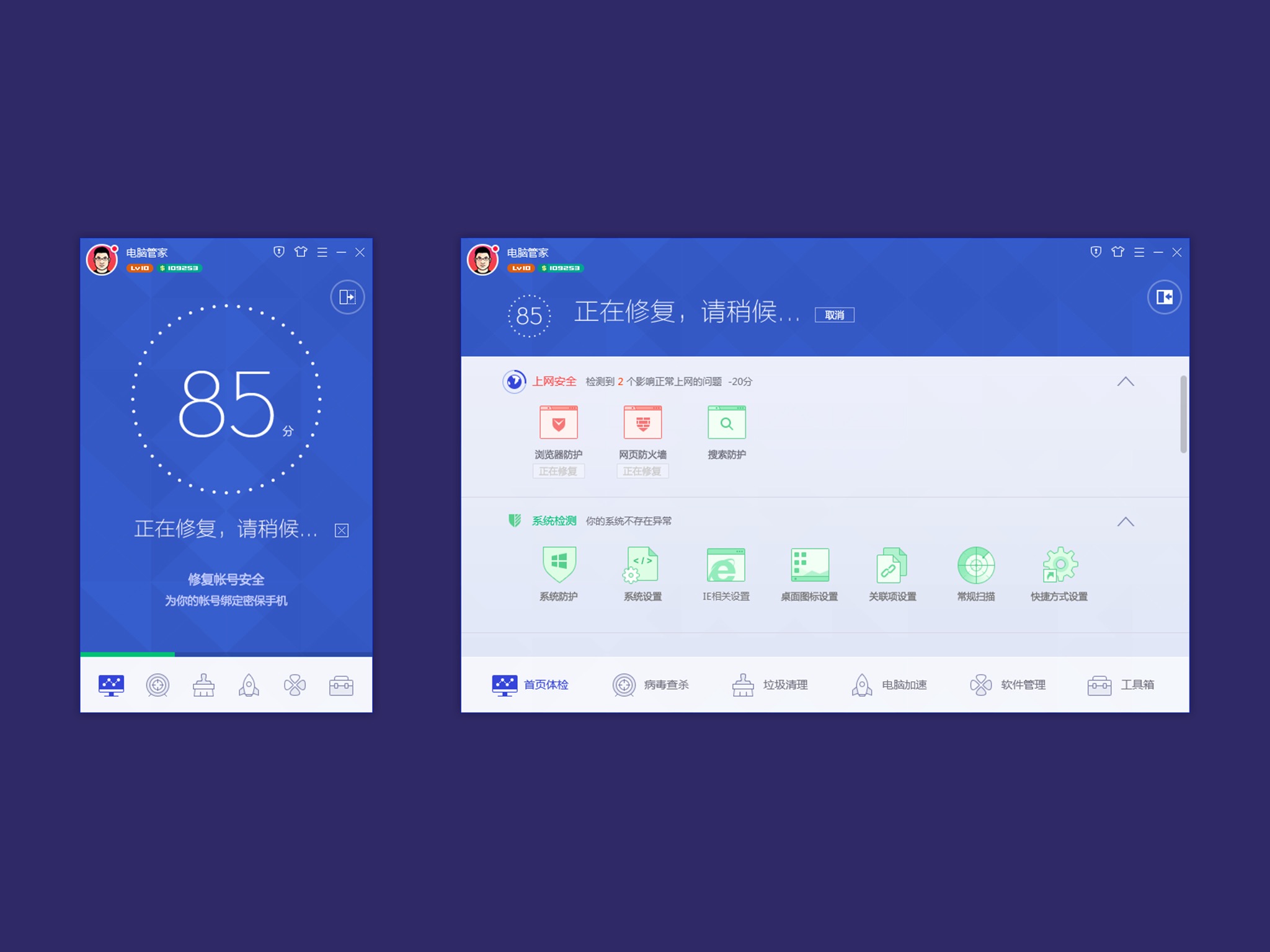
△ 騰訊電腦管家11版界面
5,新界面的動效設(shè)計讓人眼前一亮,微博上好評如潮,給大家科普下里邊運用的動效三原則吧
答:這三個原則是我們在做管家10版本時,結(jié)合做管家先鋒版(8.8)的經(jīng)驗總結(jié)出來的。
1.之前我們通過一組用研數(shù)據(jù)了解到,用戶對于打開網(wǎng)頁和軟件的延遲,超過一秒才會感知到。管家8.0的時候因為沒有交互動畫,用戶在tab與tab之間切換的時候會有一定的加載延遲,所以從感知上會有一種“卡”的感覺,一秒動畫的主要作用就是為了填補(bǔ)用戶在與軟件的交互過程中所產(chǎn)生加載時間的空白。另外,我們所有的動畫也都是一秒收尾,給用戶提供合理的操作反饋和成就感的同時,不騷擾到用戶,盡量做到干凈,利索,不拖泥帶水。

2.點線圈主要指的是在管家10所有的動畫中,我們均使用的是基于點、線、圈演變而來的視覺風(fēng)格。除了這些元素本身就可以體現(xiàn)出輕量化的感知以外,這些元素的圖形占比非常小,所以即使做出大幅度的變化也不會對用戶視覺上產(chǎn)生干擾。
3.緩動,除了掃描,加載動畫以外,我們基本上通通使用緩動曲線去模擬真實的物理表現(xiàn),盡量避免出現(xiàn)線性動畫中常有的過渡不自然的情況。
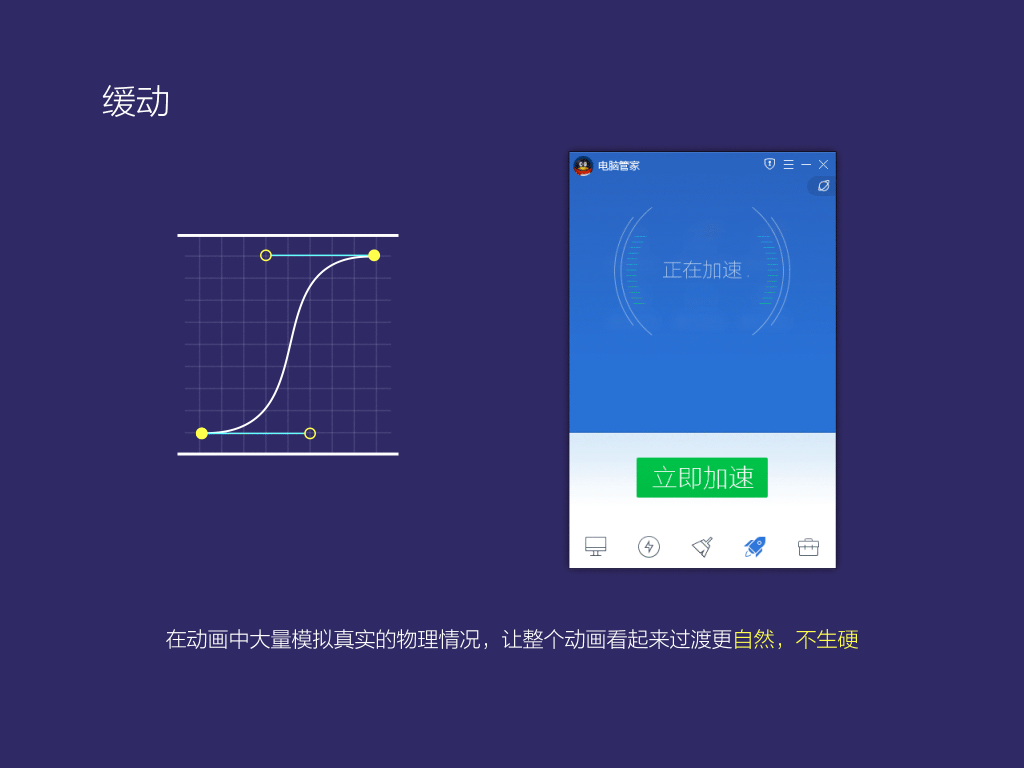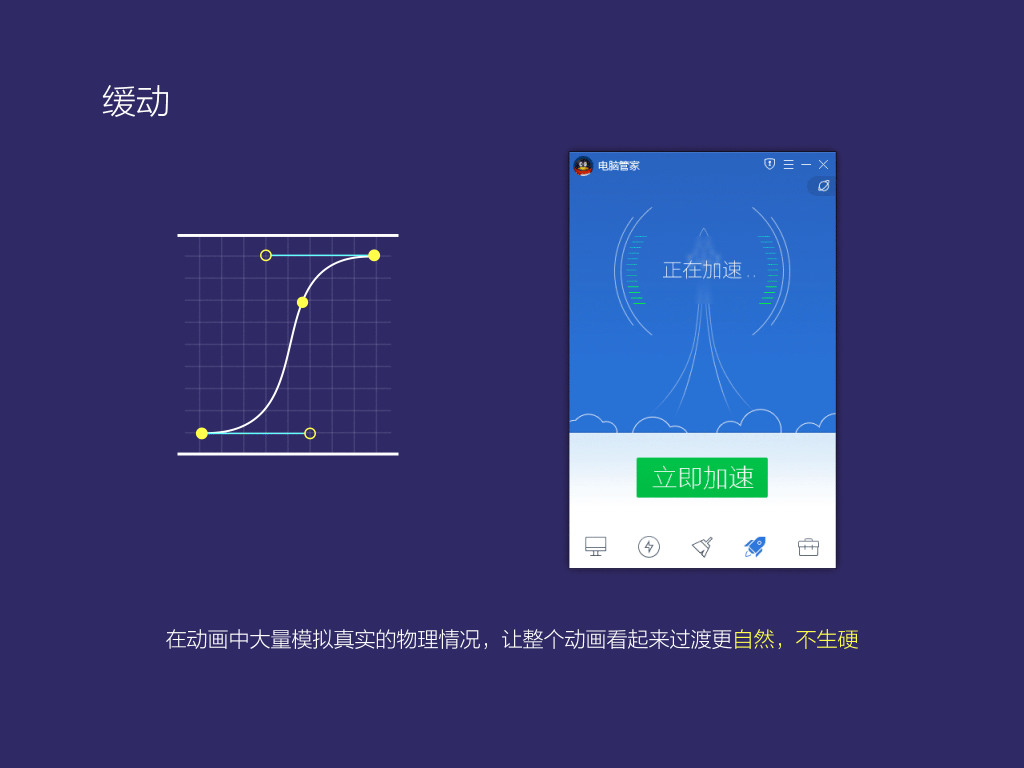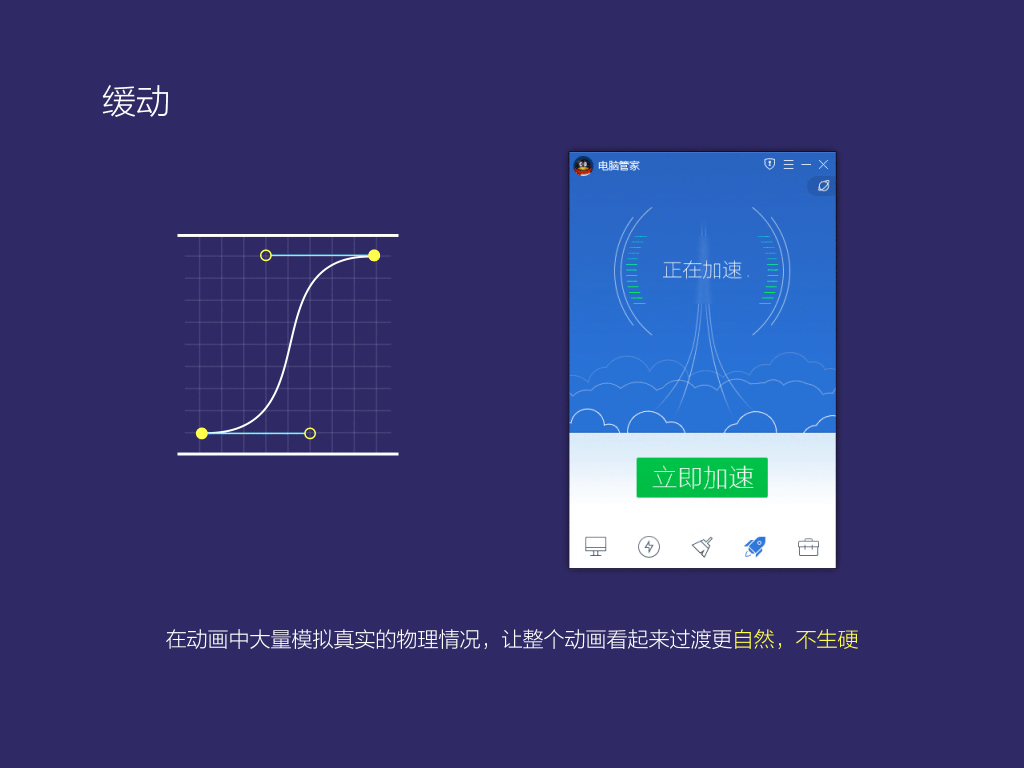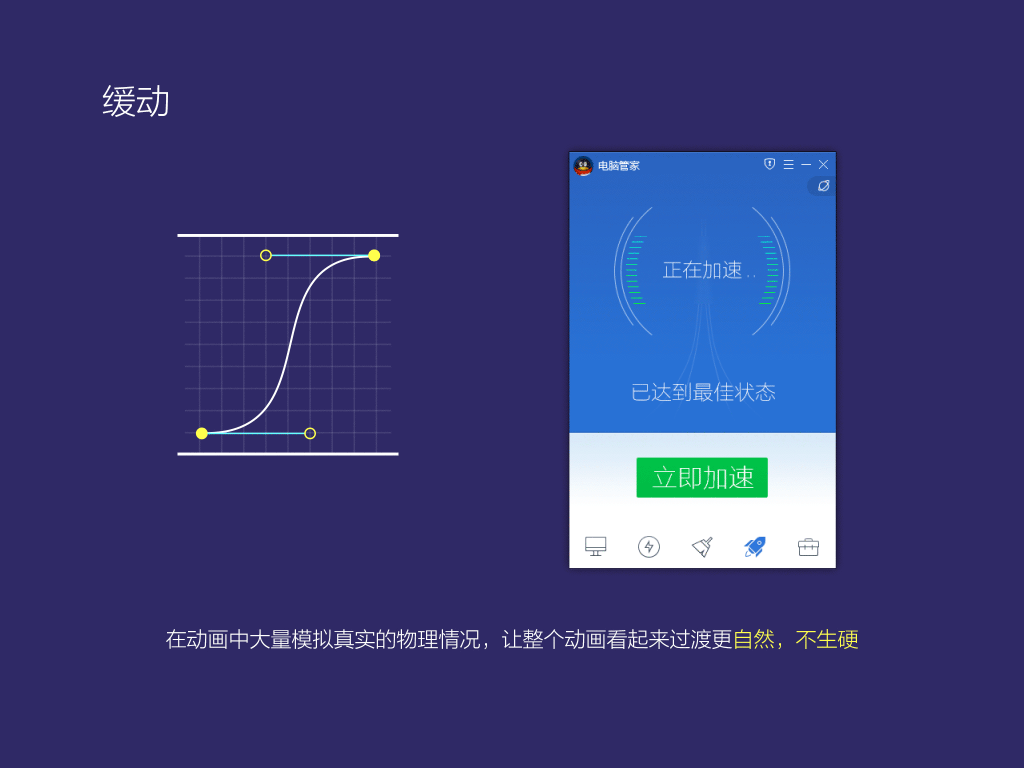
6,主導(dǎo)了騰訊電腦管家版本從8.8到11這個過程,您有什么新的設(shè)計感悟呢?
答:如果說8.8是一種突破,10是某種風(fēng)格的極致探索,那11則講究的是一種平衡,現(xiàn)有風(fēng)格和流行趨勢之間的平衡,用戶群體與產(chǎn)品定位之間的平衡,商業(yè)價值與用戶價值之間的平衡等等。我們希望從中找到一個相對完美的平衡點,我們不希望在同行眼中被定義成“藝術(shù)家”,我們也不希望用戶告訴我們,你們的產(chǎn)品一點也不接地氣。設(shè)計該是什么樣就是什么樣,以人為本,以用戶價值為依歸,我們不希望像之前做10版本時對特定風(fēng)格的糾結(jié),從某個角度來說可能沒法完全滿足用戶的訴求,例如換膚。我們深知我們離這個目標(biāo)還有很長的一段路要走,但我堅信,我們一定會努力進(jìn)一步縮短這個距離,找到一個大家都認(rèn)可的平衡點。
7,在臨摹成風(fēng)的情況下,您覺得新人設(shè)計師該如何把握好臨摹和原創(chuàng)之間的度?
答:臨摹有時候會造成一種錯覺,讓人認(rèn)為,我通過我的方式“畫”出跟原圖一樣的效果,那么我的制圖能力也就跟原圖的設(shè)計師非常接近了,但實際上是,你完全忽略了原圖的設(shè)計師在創(chuàng)作作品時的推演過程,思考過程,忽略了為什么要這樣去表現(xiàn),而不那樣去表現(xiàn)的種種理由。這是個先有雞還是先有蛋的哲學(xué)問題,如果沒有別人種的因,就沒有你現(xiàn)在得出的“果”。不是說臨摹這個行為本身是錯誤的,而是要正確認(rèn)識臨摹這個行為能夠給你帶來什么價值。我曾經(jīng)在微博上反復(fù)強(qiáng)調(diào)過,你通過臨摹對某些表現(xiàn)形式產(chǎn)生了一定的理解,那么你就可以用你的這種理解和視角去畫一些你自己想畫的東西,而這些東西是屬于你自己的。畫得再像,那也是別人的。

△ 曉翔老師過往作品
8,您強(qiáng)調(diào)設(shè)計師是解決問題的人,那么新人該如何提高解決問題的能力?
答:首先學(xué)會拆析問題,咱們生活本身就是由無數(shù)個問題組成的。你肚子餓了,困了,你的身體給你提出了問題,你去吃飯,睡覺,這是解決了問題。每次接到新的需求,逐個拆解,逐個解決就好。我個人的建議是,在你沒有能夠找到合適的解決方法的時候,不要只顧著提出問題,你要向別人展現(xiàn)的,并不是你有多聰明,多會挑刺,而是,你是一個實實在在可以解決問題的人。另外,有一部分人覺得,我把一個問題定性了,例如直接拒絕需求方,拒絕處理解決問題,或者說這個問題無解,也算是一種解決方法,其實這個理解是有誤的。所謂的真正的解決問題的方式應(yīng)該是,以對方的訴求為基點,提出有效的改善方法,由一方滿足,變成滿足雙方訴求的結(jié)果,才能算是解決問題,你單方面拒絕,不合作,主觀武斷的給問題定性,這并不能算是解決問題。
9,在無法快速迭代/老板一言堂的公司,設(shè)計師該如何確定目前的產(chǎn)品方向是否正確?
答:有先例看先例,有競品,看競品,在產(chǎn)品方向上有任何疑問都要先看數(shù)據(jù),用戶評價,分析趨勢。如果這些都沒有,你們在做一款市面上完全沒有的全新產(chǎn)品,那非常簡單,就由老板決定就好。自己YY沒有任何證據(jù)的認(rèn)為產(chǎn)品方向是錯誤的,對于你的老板來說你就是一個執(zhí)行效率很差,拒絕工作的一個庸人,他只要把你換掉就好。在騰訊,產(chǎn)品方向和設(shè)計質(zhì)量往往是分開的,因為產(chǎn)品方向的錯誤,導(dǎo)致產(chǎn)品失敗,沒人會讓設(shè)計去背這口黑鍋,至少我所在的這個部門沒有。我仍然記得,年會時跟老板喝酒,老板對我說,“XX產(chǎn)品設(shè)計挺好的,只是產(chǎn)品方向錯了而已。”老板們其實心里都有數(shù),哪還需要你去操那份閑心。老板也好,用戶也好,多關(guān)注利益點,誰能夠把你的價值最大化,你就傾向于誰。
10,作為騰訊電腦管家這個產(chǎn)品的視覺負(fù)責(zé)人,您在團(tuán)隊建設(shè)方面有什么親歷經(jīng)驗?
答:
1.先交朋友再做事,我們經(jīng)常一起吃飯,基本不在吃飯的時候聊工作的事情。只要出去團(tuán)建一定是以開心,舒服為主。活動主要是吃飯,吃各種好吃的餐館,為了避免團(tuán)建占用大家的時間,我們基本上都在工作日中午進(jìn)行,嗯,愛周末組織團(tuán)建的人都是流氓。

2.我們組大部分人是通過我這個渠道進(jìn)入騰訊的,我招人的心態(tài)就是,合作伙伴為主,最好身上有一些我身上沒有的東西,大家可以互相學(xué)習(xí),共同進(jìn)步。比我差,或者跟我類似的人,我會推薦到其他團(tuán)隊里去,保證團(tuán)隊里每個人都有一定的特點和特長,大家都有各自擅長和負(fù)責(zé)的領(lǐng)域。
3.帶團(tuán)隊的人,本身一定要做到技術(shù)碾壓,自身沒有過人的能力和技術(shù)在身,是難以服眾的。
4.好的leader應(yīng)該是帶領(lǐng)大家一起做目標(biāo)相同的事情,主要以做事,解決問題為導(dǎo)向,而不是管理人為導(dǎo)向。同時,能夠把自身的經(jīng)驗,能力和做事的激情很好的傳承給一起合作過的,更有潛力的設(shè)計師。
11,在招人無數(shù)閱遍簡歷后,有哪些建議給投簡歷找工作的同學(xué)?
答:可以看一下我之前發(fā)在微博上的“關(guān)于投簡歷的那點事兒”,文章地址:
——————————————— 生活篇 ———————————————
1,和我們聊聊您包里都裝了什么吧
答:我不吸煙,也不攝影。平時就裝這些,我的雙肩包里其實常年帶著4瓶飲料,實在沒什么好拍的就不拍了。

2,大家也想看看您家里/公司的工作臺
答:

3,作為一枚模型愛好者,你最喜歡的模型是哪個?背后有什么故事么?
答:變形金剛,小時候我父親就愛買變形金剛玩具給我,一直喜歡到現(xiàn)在。背后沒有什么特別的故事,就是覺得變形金剛的設(shè)計者心思很巧妙,以前只是覺得好玩,現(xiàn)在都是抱著敬畏之心去搜藏(其實還是會把玩的,變來變?nèi)テ錁窡o窮)。
——————————————— 彩蛋篇 ———————————————
1,您是怎么了解到優(yōu)設(shè)的,來吧,鞭撻我們吧!