

隨著信息技術的飛速發展,企業越來越依賴于信息化管理。盡管當前各種新的技術層出不窮,但大多數企業的業務數據依然主要存儲在數據庫中,比如Oracle、SQL server、MySQL等。企業對數據庫的安全性要求越來越高,為最大化的保護企業的核心數據資產,數據庫的數據安全顯得尤為重要。本文將從備份恢復的角度來談談數據庫的數據安全。
本文取材于交流活動“Oracle、MySQL等常用數據庫備份恢復難點與運維故障在線答疑”,內容由、ostrich、、lbam001等會員貢獻,歸納整理者:王巧雷。
規劃設計篇
要想在數據庫發生故障時,使用備份恢復到想要的時間點,需要根據實際需求做提前規劃。數據庫系統的規模越大,設計時需要考量的點就越多,可以說后期大部分暴露出來的問題,大部分都和前期規劃有關,下面幾個是比較典型的規劃相關問題。
Q1. 我們單位有個十幾套數據庫,想集中規劃一下備份,還有恢復計劃這方面,想了解一下?
我們單位有個十幾套數據庫,主要有oracle和MySQL,目前都是DBA自己在維護備份,重要的庫做了dg,想集中規劃一下備份,還有恢復計劃這方面,想了解一下?
A:
當數據規模上來了,完全人工管理,工作量會比較大,還容易出問題。有條件的話,最好還是上一套備份系統,可以把企業所有的重要數據集中統一管理起來,如果確實沒條件,也可以自己規劃一下,主要有以下幾點:
1、首先是調研和需求梳理,要對需要備份的數據庫系統做一個統計,明確下各個庫的rpo和rto,然后根據這些信息可以推算出備份的頻率和保存的周期,以及需要的存儲空間、大概的性能要求。
2、所有的不能接受丟數據的庫都需要備份,高可用、復制等技術替代不了備份。
3、建議和系統管理員溝通,為備份數據分配獨立的存儲空間。各個庫的備份可以集中存放,也可以單獨存放。但是不管怎樣都建議存放在獨立的磁盤空間內。和數據庫的存儲分開,避免數據庫存儲故障了,備份也拿不出來了。
4、明確責任人,定期檢查。比如備份成功率,備份空間使用率等。
5、按照前面的調研,定期對數據庫做恢復測試,實在做不了的 備份集的校驗也得做一下。費這么大精力做數據庫備份,就是為了出問題時可以恢復,如果平時不做測試和演練,出了問題手忙腳亂或者發現備份數據不可用,那麻煩可就大了。
Q2.數據庫全備一次的時間較長,如果真出了問題,感覺恢復的時間根本接受不了,請問這種情況有什么好的解決辦法嗎?
我們核心數據庫目前使用oracle 12c,日常的備份策略是周全備,加上按天的歸檔備份,數據量比較大,全備一次將近一天,如果真出了問題,感覺恢復的時間根本接受不了,請問這種情況有什么好的解決辦法嗎?
A:
這是個很常見的問題,這個問題的誤區在于把備份當成了數據安全的唯一手段,這其實是不現實的。其實不光是數據庫,所有業務系統的保護都是需要綜合考量的,需要多種技術和架構綜合來實現,備份只是其中的一個手段,具體以下幾點:
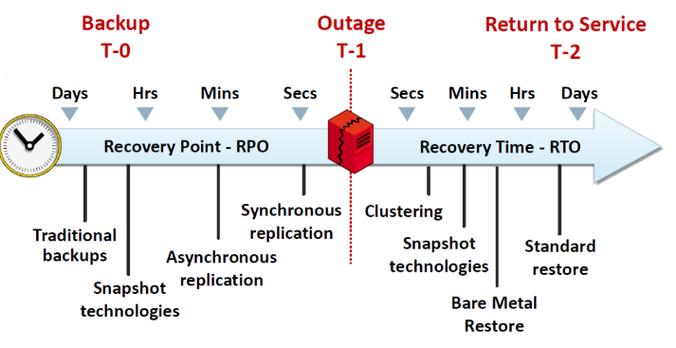
1、我們需要確認自己數據庫系統的rpo和rto,不同的要求需要不同的技術去匹配,可以參考下面的圖:
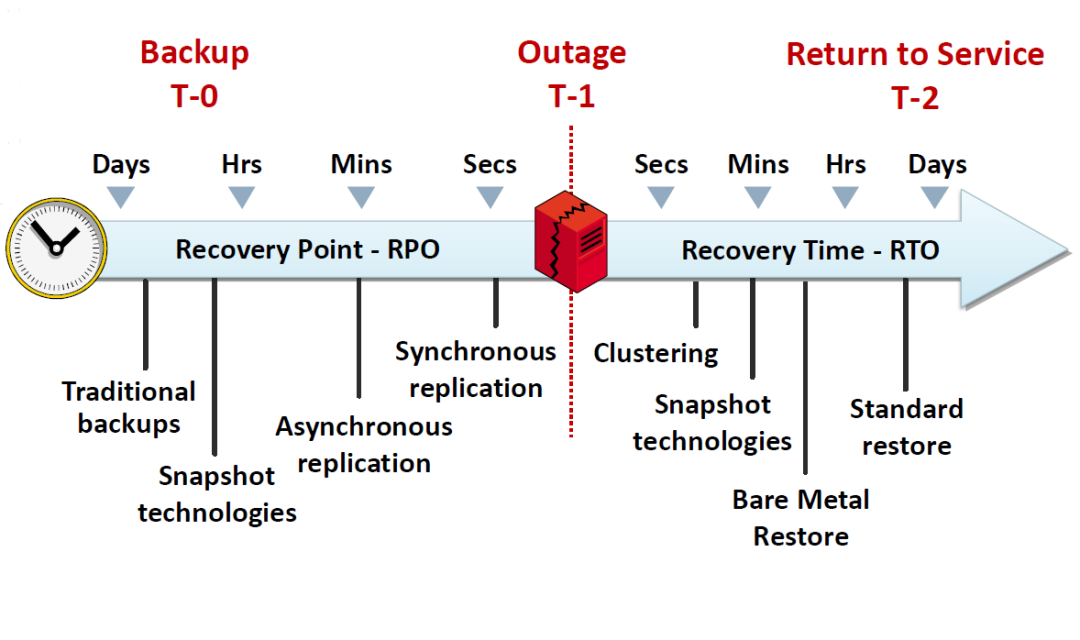
可以看到傳統備份可以達到的RPO和RTO實際上是介于小時和天之間的,在現實中可能會幾分鐘,也可能幾天, 具體時間是和要恢復的數據量有密切關系的。
2、從數據庫的故障類型來看,也分很多種,比如:
1)高可用的問題,可以通過集群來解決,如oracle rac,基于 cluster的sql集群,可以解決節點故障的的問題
2)數據存儲的問題可以通過存儲raid或鏡像技術來解決,如獨立的磁盤陣列,asm鏡像等
3)存儲單點可以通過復制技術來解決,比如基于存儲復制,或者Oracle DG,db2 hadr,MySQL主從復制等都是這種典型;
4)誤操作的問題,就連這種問題也不一定非要用到恢復,比如Oracle 提供的閃回技術,db2Time Travel Query,MySQL的system table等都可以合理利用起來,甚至有復制集群也提供類似的技術,比如db2 hadr Delayed Replay重演延遲
所以,從某種意義上來說, 實際上 大部分情況下是用不到停機停庫做介質恢復的,那么備份還有存在的必要嗎?當然有了,備份是企業的最后一道防線,可以在極端的情況下發揮巨大的作用。比如嚴重的存儲故障,超出數據庫閃回限制的誤操作等,還是會用到備份恢復的。
另外,也可以通過設計,合理利用現有的備份系統,比如企業自己測試開發環境的創建、數據的二次利用分析等,都可以利用已有的備份環境來實現,可以將備份系統更好的利用起來,發揮更大的作用。
日常運維篇
Q1.對于一些誤操作或者是壞塊,不想恢復整個庫或者整個表空間,這些相關的方面能否介紹下?
現在的數據庫普遍都比較大,做了備份后恢復的粒度也比較粗,耗時長,有時候僅僅是一些誤操作或者是壞塊,不想恢復整個庫或者整個表空間,這些相關的方面能否介紹下?
A:
這個問題其實和選用的數據庫產品有關,大部分都是軟件自身實現的,通用的規則少一些,這也是各家數據庫廠商容易做出差異化的地方,簡單羅列幾點:
1、首先日常的制度上,做好權限管理,這個反而是最重要的。如果權限混亂 誰都可以sys上去,技術再好也沒用。
2、做好日常備份,如果有備份的話,Oracle的壞塊實際上可以直接通過塊恢復的方式在線把數據塊恢復出來。
3、如果沒備份,或者備份沒覆蓋到,Oracle本身提供了一些手段(包或者10231事件)可以跳過壞塊,但相應的可能會損失一點數據,如果可以接受,跳過再補錄就行。如果不能接受可能得需要找專業的數據恢復來做。
4、日常的誤操作可以考慮使用閃回技術,Oracle的閃回工具比較多,有下面幾個:
閃回數據庫:基于數據塊對庫做閃回
drop:基于recycle bin恢復誤刪除的表
version query和 query: 基于undo技術恢復誤操作的數據,記錄級別
table:基于undo技術恢復誤操作的表
其他數據庫也有類似的技術,但可能不太全,具體根據對應的手冊查詢一下即可。
5、如果是查詢類的庫,平時數據量變化不大,可以對數據庫對象進行導出備份,出現問題的時候,導入受損對象即可,比如db2 數據庫可以有導出表的作業進行另一種形式的備份,有問題時只恢復單獨某個表。
Q2.Db2數據庫異構系統遷移?Db2數據庫從aix小機遷移至redhat的X86服務器系統
A:
異構的話:
1、用導入導出的方式做,db2look導出表結果,export導出數據,再用import或者load做導入,簡單但比較慢,導的過程中數據有增量后面需要處理;
優化建議:通過定義游標的方式+分批處理 這樣會快很多,不用擔心服務器硬件資源不夠用。建議采用 load 游標方式進行遷移。Load 語句中需要帶 ; 參數,不然遷移完畢數據庫后 導致表所在的表空間出現了 pending 狀態。
需要特別注意的地方:當數據庫表有自增序列時,定義表結構時需要把 ALWAYS AS 改成 BY DEFAULT AS ;不然無法導入!
2、用數據庫同步軟件,比如ogg cdc
Q3.Db2數據庫歸檔日志模式,日志清理?
已將DB2日志模式設置成歸檔日志;每天定時執行online 備份。
命令:db2 backup db DBNAME online to /data// include logs
發現備份文件每2天 就要增大100M左右(數據量不會有這么大),懷疑是日志的原因于是執行了清理日志命令:
//查看備份歷史,找出最近備份數據庫的日志,
db2 list history backup all for DBNAME

db2 prune history 213 and delete
db2 prune logfile prior to .LOG
執行成功后,發現日志確實被清理了,但是重新備份數據庫,數據庫備份文件還是沒有變小。
A:
db2 backup語句中的include logs選項是把備份期間產生的幾個歸檔備份上,本身就沒多大。而用prune修建的是歸檔目錄中的日志,和產生的備份文件沒有關系,這是兩碼事,所以備份文件沒啥變化是正常的。
Q4.MySQL數據庫故障Can't open file: '.MYI'. (errno: 145)?
A:
.myi是MySQL myisam引擎的索引文件,一般情況下,文件屬組丟了或者數據庫意外關機可以導致出這個問題,可以嘗試使用命令修復一下。
命令參考:
Q5. 在利用ftp下載備份文件進行恢復測試時,突然出現文件損壞的現象無法恢復數據庫?
備份文件ftp傳輸后無法恢復?在利用ftp下載備份文件進行恢復測試時,突然出現文件損壞的現象無法恢復數據庫?
A:
1、備份文件壞了就不能用了
2、找到壞的原因更重要。FTP傳輸時,有ASCII和BINARY兩種模式,在ASCII 方式下傳輸 二進制文件 ,即使不需要也仍會轉譯,這會損壞數據,建議采用 BINARY模式傳輸。
3、每個備份上傳后,源、目標端兩個文件對比一下MD5 SUM值,放心。
4、備份任務重的話,買Dell EMC ,省時、省力、省心,還安全可靠!
總結
從數據庫的數據安全的角度來看,備份恢復只是這個體系中的一部分,和集群、復制等技術共同保護數據庫數據安全,但備份卻是不能忽略的一部分。一個良好的備份系統,前期的規劃設計是非常重要的,在日常運維中也要注意定期的測試和演練,確保出現問題時可以及時頂上。
數據庫系統基礎教程
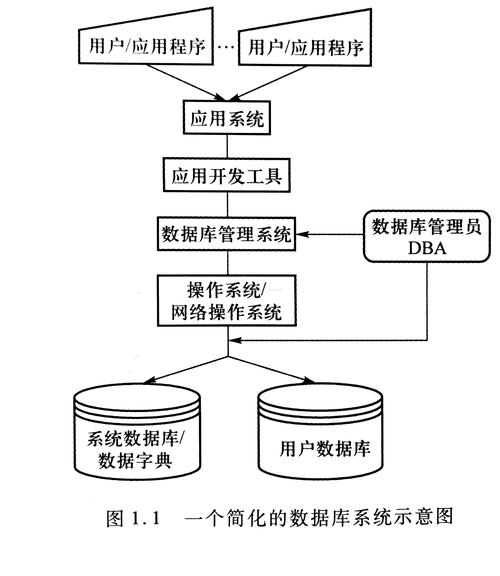
數據庫技術自20世紀60年代后期產生以來,在三十多年的發展進程中,不僅形成了相對完整的理論體系,成為現代計算機信息處理系統的重要基礎與技術核心,同時也開發出了一大批應用十分廣泛的高效實用系統,形成了“哪里有計算機,哪里就有數據庫”的嶄新局面。進入新世紀,數據庫技術與網絡技術、智能技術等計算機新技術、新領域相互滲透、彼此融合,更加展現出旺盛的生命力和強勁的發展勢頭。由于數據庫技術的學科重要性和實際應用性日益突出,數據庫系統及應用技術越來越得到人們的重視。正如人們所說,“不久以前,還只有專業人員才能直接與數據庫管理系統打交道。然而,隨著微型計算機數據管理系統的到來,情形發生了驚人變化。實際上,現在所有人(包括家用計算機的主人、小型商業人口以及大公司中的終端用戶)都可能是微型計算機數據庫管理系統的潛在用戶,如同最近大量的微型計算機所有者認為電子制表軟件是一個基本工具一樣,現在許多人員都認為數據庫管理系統是基本工具[13]”。有鑒于此,編寫能夠較好滿足上述需求并且適應于數據庫理論與應用新技術發展的數據庫系統理論與技術的教科書十分必要,本書正是在這樣的背景下組織編寫的。從知識組織框架考慮,本書可以分為3個部分共14章。
第一部分是數據庫的經典內容,這可能也是任何一本數據庫基礎教材都需要講述的主體和重點。這一部分包括8章:第1章“數據庫系統緒論”,主要介紹數據庫系統中各種基本概念、數據模型和數據庫模式結構,使學習者對將要學習的課程有一個大概的認識與整體把握;第2章“關系數據模型與關系運算”,主要介紹關系數據模型構建,討論兩種基本關系運算——關系代數與關系演算;第3章“關系數據庫語言SQL”,主要介紹關系數據庫標準語言SQL的基本內容和使用;第4章“關系數據庫的查詢優化處理”,主要介紹關系數據庫的查詢優化原理與實現技術,這是關系數據庫的基本優勢之一;第5章“關系模式設計基礎”,主要介紹關系數據模式規范化理論;第6章“數據庫的設計與管理”,主要介紹數據庫設計、實現與管理技術;第7章“數據庫的安全性和完整性”,主要介紹數據庫安全性與完整性基本概念和相應技術;第8章“數據庫事務管理”,主要介紹數據庫事務概念與性質,以及事務在并發執行和故障處理中的基本應用。第二部分是數據庫技術中比較深入的內容。作者選擇了對象數據庫和與網絡相關的數據庫技術等內容。這一部分共有4章:第9章“C/S系統與分布式數據庫”,主要介紹分布環境下數據庫的管理和應用技術;第10章“對象關系數據庫”,主要介紹基于面向對象方法的關系數據庫擴充;第11章“面向對象數據庫”,主要介紹不同于關系數據模型的面向對象數據模型及其相應數據庫技術;第12章“XML數據庫”,主要介紹兩種基于XML的數據庫技術——使能XML(XML-enabled)數據庫和原生(native)XML數據庫技術。
第三部分為現代數據庫技術概述與Oracle簡介及數據庫實驗。這一部分共有2章:第13章“現代數據庫技術概述”,主要對有別于經典數據庫情形的有關技術進行概要介紹,為以后的深入學習與應用提供必要線索;第14章“Oracle與數據庫實驗”,主要介紹關系數據庫主流平臺Oracle的基本概念與主要技術,并基于Oracle數據庫設計了基本實驗,為學習者打下一定的系統使用基礎。參與本書編寫的人員大多是長期從事數據庫技術及應用研究和教學的老師,在編寫過程中注重突出下述特點:基本原理與具體應用的平衡。一般來說,有意義的、可以廣泛應用的技術通常都有必要的理論原理支持;同時,相應的理論原理也是理解、掌握、改進和推廣具體技術的必不可少的前提。數據庫系統課程作為理論原理和具體應用密切交融的學科,如何掌握好理論與應用的平衡顯得比較突出。“具體技術很容易過時,而基本原理、概念和技術可以起到相對持久的作用。在掌握了基本原理、概念和技術之后,讀者不難通過閱讀手冊或培訓材料較快熟悉產品,并以寬闊的視野分析和評價產品[16]”。現代數據庫技術敘述進行了必要的調整。從當前研究和應用情況考慮,特別是從數據庫系統的底層來看,對象數據庫系統代表未來數據庫發展的趨勢和方向,是“經典”與“未來”的橋梁,從“對象關系數據庫”相關技術就可比較清楚地看到這一點,因此本書選取了對象數據庫作為現代數據庫技術的基本代表。

面向網絡是新世紀計算機技術與應用的重要特征,為了跟進數據庫與網絡技術日益結合的發展勢頭,我們選取了分布式數據庫和XML數據庫這兩個與網絡密切相關的數據庫新技術予以介紹。其他非經典的數據庫技術也非常重要,由于學時限制,我們將其濃縮為一章(第13章),這基本上是考慮到對其原理的理解和技術的掌握畢竟需要進行較為專門的學習與訓練,而這主要是相關后續課程的基本任務。對數據庫的應用訓練做了必要劃分。數據庫系統與應用技術的實際訓練無疑非常基本和必要,正因為如此,如果將其與數據庫理論放在一起,有可能“理論”和“應用”都達不到預期要求。我們在教改過程中對此做了必要處理,就是在基礎課程中以原理和技術為主,著重講好典型數據庫平臺的使用與實驗,較為詳細的設計、應用實驗都劃分到另外一個部分——數據庫實驗教程,這樣,可以使這兩個方面都得到必要的強化,有助于解決理論與應用的平衡問題。本書選取了數據庫主流平臺之一的Oracle數據庫作為介紹重點,并圍繞Oracle設計了若干基本實驗。作為數據庫系統基礎教材,本書既注重介紹數據庫系統基本原理,又兼顧數據庫技術的實際應用;既注重基礎理論原理的完整性和科學性,又加強了有關基本概念的實際背景介紹;既講授知識,又努力探討問題提出與解決的思路。
按照作者的教學經驗,如果側重于數據庫基礎和原理,可以重點講授前8章,選講第10章和第11章,這些大約需要45~50學時,其他章節可以作為學生的自學內容,若是需要開設有關數據庫實驗,可以參考第14章。如果側重于數據庫技術和應用,可以重點講授前8章(帶*內容可以不講,只供有興趣的學生自學),數據庫實驗也可以參考本書的姊妹篇:《數據庫系統實驗指導教程》(清華大學出版社,2006),在此種情況下,前8章大約需要35學時左右,基本實驗大約需要15學時左右。如果是使用者自學,前8章和第14章是基本內容。本書可作為大學本科計算機及信息科學與技術專業的基礎教材,也可供有關人員自學參考。本書配有相應課件供教師教學時參考,另外還編寫了學習指導書,提供全書的要點復習和全部習題參考解答以及其他有助于讀者自學的內容。編寫一本合適的基礎教材并非易事,限于作者水平和能力,本書不足與疏漏之處在所難免,有關編寫初衷也未必能夠充分體現,這些都要請有關專家學者和廣大使用者不吝指教。在本書編寫過程中,參考了較多的國內外相關專著、教材與文獻資料,其主要部分在書末參考文獻中都已列出,在此我們對相關作者一并表示衷心感謝。在本書的編寫過程中,研究生胡蘇、李順古、陳鎧原、劉博和陳達君等參與了部分文字工作,在此也表示感謝。作 者2007年1月于中山大學
more >