

2022 年 12 月 14 日~16 日,由 IT168 聯(lián)合旗下 ITPUB、 兩大技術(shù)社區(qū)主辦的第 13 屆中國(guó)數(shù)據(jù)庫技術(shù)大會(huì)(DTCC 2022)在線上隆重召開。大會(huì)以“數(shù)據(jù)智能 價(jià)值創(chuàng)新”為主題,上百位技術(shù)領(lǐng)袖齊聚云端,進(jìn)行多維度、多視角、多層級(jí)的交流碰撞,為廣大數(shù)據(jù)領(lǐng)域從業(yè)人士提供一場(chǎng)年度技術(shù)盛宴。
首席架構(gòu)師楊志豐(花名:竹翁),在主論壇帶來題為《 4.0:?jiǎn)螜C(jī)分布式一體化的技術(shù)演進(jìn)》的演講,和業(yè)內(nèi)分享 從 0.5 版本到 4.0 版本的技術(shù)架構(gòu)發(fā)展與演變。
以下為 首席架構(gòu)師楊志豐在 DTCC 2022 上的發(fā)言實(shí)錄。
大家好,我是 的楊志豐,今天和大家分享的題目是《 4.0:?jiǎn)螜C(jī)分布式一體化的技術(shù)演進(jìn)》,主要內(nèi)容更加偏向技術(shù)解讀,探討架構(gòu)演進(jìn)的同時(shí),會(huì)與大家分享 對(duì)于單機(jī)分布式一體化架構(gòu)的理解和思考。
在今年 8 月 10 日 年度發(fā)布會(huì)上,我們正式發(fā)布了 4.0 小魚,這個(gè)版本有一個(gè)形象的比喻叫做“小就是大”, 我們希望通過這個(gè)版本架構(gòu)的變化,使得 可以從原來支持大型企業(yè)為主,真正走向中小型企業(yè)。 用戶可以使用一個(gè) 數(shù)據(jù)庫,在企業(yè)或業(yè)務(wù)發(fā)展的不同階段都能使用單個(gè)數(shù)據(jù)庫,不用做遷移。我今天將從技術(shù)的視角去分享一下這背后技術(shù)的原理是如何思考的。
12年,從.5到4.0
▋ 0.5~3.0
從 2010 年開始研發(fā),下面是 0.5 版本的整體架構(gòu)圖,彼時(shí) 分成存儲(chǔ)和計(jì)算兩層。上一層是無狀態(tài)提供 SQL 服務(wù)的服務(wù)層,下一層是由兩種 共同組成的存儲(chǔ)集群。
這樣的架構(gòu)能夠使 比較好的支撐類似于淘寶收藏夾的業(yè)務(wù),具有一定的擴(kuò)展性,特別是讀的擴(kuò)展性比較強(qiáng),并且 SQL 層是無狀態(tài)的,可以自由的伸縮。
但同時(shí),這個(gè)架構(gòu)面臨最主要的問題是由于寫入的節(jié)點(diǎn)為 節(jié)點(diǎn),其是單點(diǎn)寫入、多點(diǎn)讀的架構(gòu),會(huì)導(dǎo)致在更大規(guī)模并發(fā)要求下,沒有辦法進(jìn)行擴(kuò)展。
僅從這幅圖上還有一個(gè)不容易被意識(shí)到的問題:我們發(fā)現(xiàn)以這樣一個(gè)方式去割裂存儲(chǔ)層和 SQL 層之后會(huì)有一個(gè)很大的問題,查詢時(shí)延不好控制。實(shí)際上網(wǎng)絡(luò)服務(wù)很難控制時(shí)延,會(huì)有一些抖動(dòng),如果對(duì)時(shí)延要求極高情況下,很難控制時(shí)延抖動(dòng)。
為了解決上述問題, 摒棄之前的架構(gòu),發(fā)展出了 .0 - 3.0 的架構(gòu),整體上來說是一個(gè)完全對(duì)等的節(jié)點(diǎn),所有的節(jié)點(diǎn)都可以在處理 SQL 的同時(shí),處理事務(wù)并保存數(shù)據(jù)。在這幅示意圖中,縱向方向是分布式可擴(kuò)展層,橫向方向是復(fù)制層。橫向方向提供服務(wù)高可用能力,縱向是通過不斷加機(jī)器去提升整個(gè)服務(wù)的擴(kuò)展性。
演進(jìn)到 4.0 版本之前,原有的架構(gòu)已經(jīng)有了非常好的擴(kuò)展性。在這一擴(kuò)展性下,我們用 3.0 版本參加了 TPC-C 測(cè)試, 是當(dāng)時(shí)唯一一個(gè)通過了 TPC-C 測(cè)試的分布式數(shù)據(jù)庫,也是唯一一個(gè)通過 TPC-C 測(cè)試的國(guó)產(chǎn)數(shù)據(jù)庫,而且到目前為止保持世界第一。

這也反映出 3.0 架構(gòu)在水平擴(kuò)展性上有非常好的適應(yīng)性,如圖可以看到,從三個(gè)節(jié)點(diǎn)到 打榜拿到了 7.07 億 tpmC 指標(biāo)的情況下,隨著節(jié)點(diǎn)數(shù)增加,整個(gè)tpmC指標(biāo)有非常好的線性擴(kuò)展性。參加 TPC-C 評(píng)測(cè)時(shí), 通過 1557 臺(tái)機(jī)器組成的大集群,在壓測(cè) 8 個(gè)小時(shí)之內(nèi),每秒鐘有 2000 萬次事務(wù)處理能力。這個(gè)結(jié)果說明,前面的架構(gòu)是能支撐非常好的擴(kuò)展性,幾乎這一擴(kuò)展性和并發(fā)處理能力是可以滿足絕大多數(shù)當(dāng)前世界上在線服務(wù)系統(tǒng)需求的。
▋ 引入動(dòng)態(tài)日志流的 4.0
但隨著業(yè)務(wù)需求的迭代,我們還是發(fā)展出了 4.0 架構(gòu), 4.0 架構(gòu)核心的變化,是引入動(dòng)態(tài)日志流的概念。原來把事務(wù)擴(kuò)展和存儲(chǔ)擴(kuò)展的粒度等同起來一起去看,但如果存儲(chǔ)分成了若干個(gè)分片,導(dǎo)致事務(wù)處理和高可用能力也是以這樣的分片為粒度的。我們?cè)?4.0 版本里把這兩個(gè)概念進(jìn)行了解耦,所以若干個(gè)存儲(chǔ)的分片會(huì)共享一個(gè)事務(wù)日志流以及這個(gè)日志流所對(duì)應(yīng)后面的高可用服務(wù)。
這一變化背后最核心的思路,是我們希望能夠支撐更小的規(guī)模下的一些應(yīng)用。比如螞蟻這樣大規(guī)模應(yīng)用里,3.0 架構(gòu)不會(huì)遇到瓶頸問題,但隨著 走向通用,特別是各種各樣的中小企業(yè)時(shí),如果日志流的數(shù)目和分區(qū)數(shù)綁定到一起的話,在很多場(chǎng)景下是不能適應(yīng)對(duì)中小規(guī)模企業(yè)支撐的。也就是說,如果日志流特別多,在越小規(guī)模下開銷顯得就會(huì)越大。
基于此,我們有必要從以下幾個(gè)方面對(duì)單機(jī)分布式一體化的概念進(jìn)行解釋:
單機(jī)分布式一體化數(shù)據(jù)庫體系結(jié)構(gòu)
4.0 架構(gòu)既可以通過分布式方式使用 數(shù)據(jù)庫,也可以用大家原來熟悉的類似 MySQL 單機(jī)方式使用 。
第一,如果以單機(jī)方式部署 ,或者在 集群內(nèi)部署單容器租戶,都能提供原來使用單機(jī)數(shù)據(jù)庫一樣的效率和性能。
第二,如果使用分布式模式,在租戶層面上、事務(wù)層面上以及單條 SQL 執(zhí)行層面上,都不需要因?yàn)橐肓朔植际蕉冻鲱~外代價(jià)。在這種情況下,需要我們?cè)?SQL 層、存儲(chǔ)層、事務(wù)層各層設(shè)計(jì)上,以一種單機(jī)分布式一體化設(shè)計(jì)的方式去滿足各種情況,在各個(gè)層面上做到兼顧。
▋ - or -?
在數(shù)據(jù)庫發(fā)展的階段有一個(gè)爭(zhēng)論:數(shù)據(jù)庫應(yīng)該是基于無共享的集群去設(shè)計(jì),還是使用 - 架構(gòu)去設(shè)計(jì)數(shù)據(jù)庫,才能夠提供最好的效率?
現(xiàn)在實(shí)際的集群,從物理集群角度來看,既不是完全 -,也不是完全 -。在每個(gè)機(jī)器節(jié)點(diǎn)上去看單個(gè)節(jié)點(diǎn),也是多處理器的結(jié)構(gòu),很多 CPU,現(xiàn)在有 96 核機(jī)器,甚至更大規(guī)格的機(jī)器,內(nèi)存也是越來越大,使用非常高速系統(tǒng)內(nèi)的總線去和磁盤、和所有外部設(shè)備去做交互,并且有很好的網(wǎng)絡(luò)。所以現(xiàn)實(shí)使用的集群不能簡(jiǎn)單看作是 -,就是單機(jī)內(nèi)有非常強(qiáng)的計(jì)算和存儲(chǔ)的處理能力,為什么不利用這樣的能力呢?這也是單機(jī)數(shù)據(jù)庫或集中數(shù)據(jù)庫所有的 scale-up 的方向。分布式數(shù)據(jù)庫不應(yīng)該只考慮水平的擴(kuò)展,而不去考慮垂直擴(kuò)展的問題。
如果想利用硬件垂直擴(kuò)展能力的話,數(shù)據(jù)庫應(yīng)該怎么做?可以設(shè)想一下有這樣一種分布式數(shù)據(jù)庫,以下方左圖為例,這是現(xiàn)在很多分布式數(shù)據(jù)庫的實(shí)際架構(gòu)圖,有點(diǎn)像 0.5 的結(jié)構(gòu),有專門的計(jì)算節(jié)點(diǎn)和存儲(chǔ)節(jié)點(diǎn)。計(jì)算節(jié)點(diǎn)是一層,存儲(chǔ)節(jié)點(diǎn)是另外一層,這兩層做了單獨(dú)抽象,它們中間會(huì)通過 GTM/TSO 處理全局事務(wù)的模塊,做多機(jī)交互時(shí)也需要和這個(gè)模塊做交互。
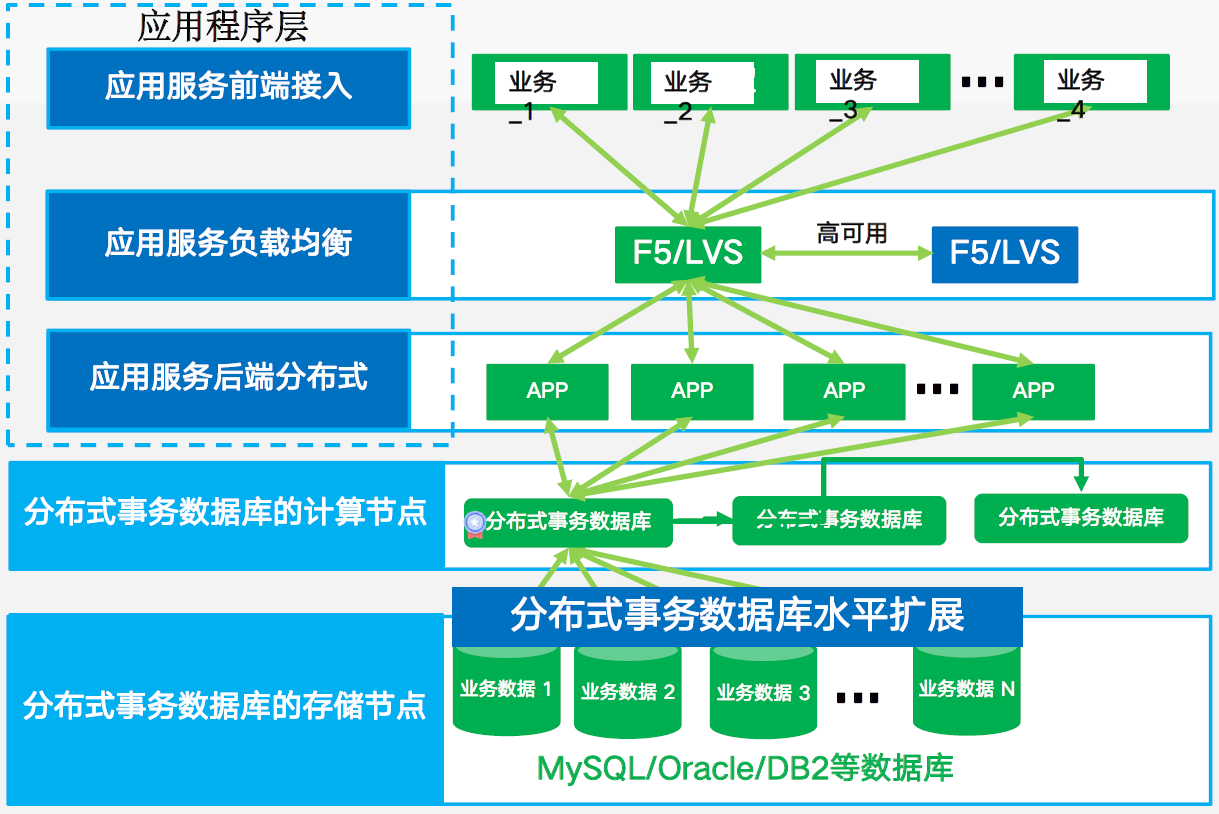
如果把這一分布式數(shù)據(jù)庫以非常簡(jiǎn)單的方式塞到了一個(gè)節(jié)點(diǎn)上,讓它以單機(jī)的方式去運(yùn)行,這里最大的問題是什么?就是這些組件之間的交互在單機(jī)內(nèi)工作時(shí)開銷非常大,這種開銷本質(zhì)上對(duì)于 MySQL 這樣的單機(jī)數(shù)據(jù)庫是額外的非必要開銷,所以顯然這樣一種簡(jiǎn)單的方式是很難以和單機(jī)數(shù)據(jù)庫相比的。
▋ 單機(jī)分布式一體化:兼顧單機(jī)和分布式場(chǎng)景
如果在單機(jī)內(nèi)來看,單機(jī)內(nèi)要有完全獨(dú)立的單機(jī) SQL、事務(wù)和存儲(chǔ)三層,相對(duì)另外一種方式是所謂的分布式數(shù)據(jù)庫會(huì)把分布式 SQL 引擎、分布式事務(wù)引擎和分布式存儲(chǔ)引擎也看作是獨(dú)立的三層。我們希望同時(shí)去糅合單機(jī)這三種引擎和分布式這三種引擎,使用同一套代碼,甚至可以動(dòng)態(tài)地去做變換和交互。
所認(rèn)為單機(jī)分布式一體化DB架構(gòu)
除此之外,所謂單機(jī)數(shù)據(jù)庫,要在單機(jī)內(nèi)充分發(fā)揮擴(kuò)展性能力,需要在 SQL 層提供并行執(zhí)行的能力,需要在事務(wù)層去提供類似 MVCC 的擴(kuò)展性核心技術(shù),并且使用類似組提交的技術(shù),使得單機(jī)內(nèi)多個(gè)事務(wù)也可以并發(fā)去執(zhí)行。在存儲(chǔ)層,需要能夠支撐單機(jī)并行的 IO,當(dāng)單機(jī)內(nèi)增加更多磁盤和存儲(chǔ)帶寬時(shí),可以能夠充分利用。
分布式內(nèi)的單機(jī)數(shù)據(jù)庫,不能簡(jiǎn)單把分布式的擴(kuò)展性做好就行了,即使是以分布式方式去部署時(shí),單機(jī)效率也必須是非常高的,需要能夠高效去支持串行的執(zhí)行,高效的執(zhí)行在分布式事務(wù)的情況下,使得單機(jī)事務(wù)能夠有自適應(yīng)的優(yōu)化。
對(duì) 來說,還獨(dú)創(chuàng)引入了一個(gè)創(chuàng)新技術(shù)——單機(jī) LSM-Tree 存儲(chǔ)引擎。如果以單機(jī)設(shè)計(jì)的視角去看的話,確實(shí)只能做前后臺(tái)可能會(huì)互相影響的合并操作,但我們不是一個(gè)單機(jī)數(shù)據(jù)庫,如果真正是分布式部署的話,又可以引入一種分布式策略,使得多個(gè)副本之間可以做錯(cuò)峰輪轉(zhuǎn)的合并。所以在整體設(shè)計(jì)上,在 SQL 層、事務(wù)層和存儲(chǔ)層里,我們每一層的設(shè)計(jì)都是兼顧了單機(jī)和分布式的場(chǎng)景,使得它在單機(jī)和分布式場(chǎng)景下都沒有多余額外的開銷,這是我們的設(shè)計(jì)目標(biāo)。
這樣我們就要求有 2 個(gè)基本特性:
相應(yīng)于前面所講的 - 和 - 結(jié)合的架構(gòu),實(shí)際上在每個(gè) 節(jié)點(diǎn)內(nèi)部,SQL 和事務(wù)存儲(chǔ)之間都使用函數(shù)調(diào)用直接去交互的,這和單機(jī)數(shù)據(jù)庫是一樣的,當(dāng)我們要在多節(jié)點(diǎn)之間交互時(shí),也會(huì)打破所謂嚴(yán)格的去做分層的,選擇最優(yōu)的、最合適的、效率最高的方案。
例如,一個(gè)節(jié)點(diǎn)的 SQL 向另外一個(gè)節(jié)點(diǎn)上的 SQL 層發(fā)一個(gè)消息,讓這個(gè) SQL 層再去訪問它的存儲(chǔ)節(jié)點(diǎn),這里最優(yōu)的取決于你要做什么,不同的負(fù)載下面可能有不同的選擇, 可以直接訪問一個(gè)遠(yuǎn)程存儲(chǔ)。在事務(wù)處理層也是如此,如果單機(jī)事務(wù)下不需要和別人去做交互,就不需要和其他的事務(wù)組件進(jìn)行交互。
執(zhí)行引擎,要處理很多情況,為什么要做這么多細(xì)分呢?是因?yàn)橄M诿糠N情況下都能自適應(yīng)做到最優(yōu)。大的層面上來說,每一條 SQL 的執(zhí)行都有兩種模式:串行執(zhí)行或并行執(zhí)行。

▋ 串行執(zhí)行-單機(jī)內(nèi)并行-分布式并行
在串行執(zhí)行時(shí),如果這個(gè)表或者這個(gè)分區(qū)是位于本機(jī)的,這條路線和本機(jī) SQL 的處理、單機(jī) SQL 的處理是沒有任何區(qū)別的。如果所訪問的是另外一臺(tái)節(jié)點(diǎn)上的數(shù)據(jù),有兩種做法:把數(shù)據(jù)遠(yuǎn)程拉取到本機(jī)來,叫做遠(yuǎn)程數(shù)據(jù)獲取服務(wù)。遠(yuǎn)程執(zhí)行,如果單個(gè)事務(wù)內(nèi)所訪問的數(shù)據(jù)都位于另外一個(gè)節(jié)點(diǎn)上,會(huì)把整個(gè)事務(wù)處理和存儲(chǔ)訪問過程全部發(fā)送到另外一個(gè)節(jié)點(diǎn)上,將整個(gè)事務(wù)提交全部代理給它,然后再返回來;如果單條 SQL 訪問的數(shù)據(jù)位于很多個(gè)節(jié)點(diǎn)上,可以把計(jì)算壓到每個(gè)節(jié)點(diǎn)上,并且為了能夠達(dá)到串行執(zhí)行(在單機(jī)情況下開銷最小)的效果,還會(huì)提供分布式執(zhí)行能力,即把計(jì)算壓給每個(gè)節(jié)點(diǎn),讓它在本機(jī)做處理,最后做匯總,并行度只有1,不會(huì)因?yàn)檫@個(gè)而增加資源額外的消耗。如果是并行執(zhí)行,支持并行查詢,對(duì)并行查詢分本機(jī)的并行和分布式并行,同時(shí)支持 DML 寫入操作的并行。
對(duì)于串行的執(zhí)行,一般開銷最小。這種執(zhí)行計(jì)劃,在單機(jī)做串行的掃描,既沒有上下文切換,也沒有遠(yuǎn)程數(shù)據(jù)的訪問,是非常高效的。對(duì)于當(dāng)前很多小規(guī)模業(yè)務(wù)來說,串行執(zhí)行的處理方式足夠。但如果需要訪問大量數(shù)據(jù)時(shí),可以在 單機(jī)內(nèi)引入并行能力,目前,這個(gè)能力很多開源的單機(jī)數(shù)據(jù)庫還不支持大規(guī)模圖數(shù)據(jù)的分布式處理,但只要有足夠多的 CPU,是可以通過并行的方式使得單條 SQL 處理能力線性地縮短時(shí)間。只要有一個(gè)高性能多核服務(wù)器增加并行就可以了。
針對(duì)同樣形式的分布式執(zhí)行計(jì)劃,可以讓它在多機(jī)上分布式去做并行,這樣可以支撐更大的規(guī)模,突破單機(jī) CPU 的數(shù)目,去做更大規(guī)模的并行,比如從幾百核到幾千核的能力。
▋ 串行執(zhí)行:DAS 執(zhí)行和分布式執(zhí)行
針對(duì)串行執(zhí)行有兩種執(zhí)行方式:DAS 執(zhí)行和分布式執(zhí)行。
DAS 執(zhí)行,方式之一是拉數(shù)據(jù),如果數(shù)據(jù)位于遠(yuǎn)程,并且是簡(jiǎn)單的點(diǎn)查詢或索引訪問回表查詢,這種方式資源消耗是最小的,我們會(huì)把這個(gè)數(shù)據(jù)拉取到本地,它的執(zhí)行計(jì)劃和本地的執(zhí)行計(jì)劃從形式上、形狀上是沒有區(qū)別的,在執(zhí)行器里會(huì)自動(dòng)去做這個(gè)動(dòng)作。但有時(shí)候把數(shù)據(jù)拉過來,不如把計(jì)算壓下去,所以我們同時(shí)支持了分布式執(zhí)行,需要強(qiáng)調(diào)的是這種分布式執(zhí)行并沒有額外增加資源的消耗,我們會(huì)保證它的并行度和前面 DAS 執(zhí)行是一樣的。
對(duì)于某些特定的查詢或大規(guī)模掃描,我們會(huì)動(dòng)態(tài)自適應(yīng)選擇這兩者,基于代價(jià)去評(píng)估哪種執(zhí)行效果最好。
并行執(zhí)行框架可以自適應(yīng)處理單機(jī)內(nèi)并行和分布式并行,它們是同一套框架。這里所有并行處理的 既可以是本機(jī)上多個(gè)線程,也可以是位于很多個(gè)節(jié)點(diǎn)上的線程,我們?cè)诜植际綀?zhí)行框架里有一層自適應(yīng)數(shù)據(jù)的傳輸層,對(duì)于單機(jī)內(nèi)的并行,傳輸層會(huì)自動(dòng)把線程之間的數(shù)據(jù)交互轉(zhuǎn)換成內(nèi)存拷貝。這樣把不同的兩種場(chǎng)景完全由數(shù)據(jù)傳輸層抽象掉了,實(shí)際上并行執(zhí)行引擎對(duì)于單機(jī)內(nèi)的并行和分布式并行,在調(diào)度層的實(shí)現(xiàn)上是沒有區(qū)別的。
事務(wù)處理的單機(jī)分布式一體化
既然做擴(kuò)展性更難的是事務(wù)處理,那么事務(wù)處理過程中為什么要兼顧單機(jī)和分布式?我們從下圖開始解釋:
左圖是傳統(tǒng)的分布式事務(wù)處理過程,分成事務(wù)的開啟階段和事務(wù)的提交階段,右圖是 的事務(wù)處理過程。

事務(wù)提交協(xié)議提出一個(gè)新思路,叫做參與者既協(xié)調(diào)者的兩階段提交協(xié)議。 兩階段提交比起左圖,從提交事務(wù)到提交成功這個(gè)時(shí)間之內(nèi),我們所處理的消息量和寫入的日志量比左邊這幅圖少很多,這使得整個(gè)兩階段提交的時(shí)延有很大的優(yōu)勢(shì),這個(gè)優(yōu)勢(shì)也會(huì)支撐我們后面要講的即使是在 分布式場(chǎng)景下,事務(wù)的處理能力也不會(huì)像很多其他的分布式數(shù)據(jù)庫一樣開銷非常大。
如果單個(gè)事務(wù)只涉及到單個(gè)日志流,一般來說如果業(yè)務(wù)數(shù)據(jù)量在負(fù)載均衡能夠容忍的粒度之內(nèi),日志流不需要特別多,很大概率上,完全以單機(jī)方式去部署時(shí),只有一個(gè)日志流,而一個(gè)日志流內(nèi)任何的事務(wù)是不需要走兩階段提交的。
事務(wù)不能獨(dú)立地去看,在一個(gè)分布式系統(tǒng)里可能既有涉及到多日志流的事務(wù),也有涉及到單日志流的事務(wù)。兩者之間是有關(guān)系的,對(duì)于單日志流事務(wù)來說, 引入了獨(dú)創(chuàng)的優(yōu)化,使得 單日志流事務(wù)的處理過程中,不需要去訪問全局的時(shí)間服務(wù),只需要訪問本地特有的時(shí)間服務(wù),同時(shí)保證全局的一致性。
如果拋開分布式事務(wù)提交的協(xié)議來看,所有的事務(wù)以及整個(gè)工作負(fù)載都沒有分布式事務(wù)的話,整個(gè)事務(wù)處理過程和單機(jī)數(shù)據(jù)庫是相當(dāng)?shù)摹?/p>
單機(jī)的性能擴(kuò)展性實(shí)驗(yàn)
下面的實(shí)驗(yàn)以三個(gè)節(jié)點(diǎn)的方式,也就是說節(jié)點(diǎn)和節(jié)點(diǎn)之間是副本的關(guān)系,實(shí)際上事務(wù)處理是單機(jī)完成的,就把它看作是單機(jī), 隨著硬件性能的增強(qiáng)擴(kuò)展性實(shí)驗(yàn),從 4 核到 64 核,可以做到基本線性擴(kuò)展的。從 90000、、、、。在 64 核規(guī)模范圍之內(nèi), 可以提供線性的擴(kuò)展。
大家對(duì)分布式數(shù)據(jù)庫有一個(gè)誤解,或者很多分布式數(shù)據(jù)庫可能給大家形成一個(gè)固有的印象:原來某單機(jī)數(shù)據(jù)庫或集中式數(shù)據(jù)庫,可以用一臺(tái)機(jī)器支撐一個(gè)業(yè)務(wù),引入分布式數(shù)據(jù)庫以后,擴(kuò)展性好了,但如果想支持同樣的并發(fā)量,可能不得不使用三個(gè)節(jié)點(diǎn)共同來提供服務(wù),才能達(dá)到單機(jī)同樣的性能和效率。
這顯然不是用戶所希望的分布式數(shù)據(jù)庫。關(guān)鍵問題在于看性能時(shí),不光要看吞吐量的增加,還要看單個(gè) SQL 或單個(gè)事務(wù)從應(yīng)用視角來看多快能處理完,因?yàn)槭聞?wù)處理從單個(gè)部分來看,我們希望實(shí)現(xiàn)的是隨著分布式事務(wù)比例的增加,時(shí)延是在增加的,但是關(guān)鍵有兩點(diǎn):即使是由完全的分布式事務(wù)組成,時(shí)延也需要足夠低;以及當(dāng)單機(jī)事務(wù)沒那么多的時(shí)候,請(qǐng)不要買一贈(zèng)一,給我贈(zèng)送額外時(shí)延。
第一,SQL 層、存儲(chǔ)層、事務(wù)層大規(guī)模圖數(shù)據(jù)的分布式處理,即使在分布式場(chǎng)景下,也需要為單機(jī)粒度的事務(wù)和 SQL 做優(yōu)化。
第二,如果三個(gè)組件之間完全做了獨(dú)立的分層,實(shí)際上用戶是缺乏控制手段的,能不能不要發(fā)一個(gè) RPC 去訪問一個(gè)數(shù)據(jù),如何能放到一個(gè)節(jié)點(diǎn)上省掉這些 RPC。所以我們希望能夠讓用戶和 DBA 在非常極致性能要求下有這樣一個(gè)控制的能力。好比 為什么要用 C++ 去實(shí)現(xiàn),就希望能充分控制內(nèi)存,控制所有時(shí)延的消耗。可以把一個(gè)事情能夠做精確的控制,可控性非常重要。同樣我們分區(qū)的能力也需要能夠控制的,比如通過提供 Table-group,能夠使得表之間沒有分布式事務(wù)開銷的。
▋ 4.0 VS MySQL 8.0
如圖,如果沒有分布式事務(wù)場(chǎng)景下,以分布式情況下部署,單機(jī)效果到底怎么樣? 4.0 和 MySQL 8.0 企業(yè)版在同樣硬件情況下做了對(duì)比,在硬件 32 核規(guī)格下,黃色是 ,從數(shù)據(jù)上可以看到, 4.0 在相同硬件環(huán)境下性能優(yōu)于 MySQL,即使是小規(guī)模場(chǎng)景下,也可以放心地使用 分布式數(shù)據(jù)庫。

使用以后有什么好處?
傳統(tǒng)使用 MySQL 主備庫的方式有一個(gè)很明顯的問題,就是容災(zāi)時(shí)會(huì)丟數(shù)據(jù),這個(gè)問題無法解決,而 首先肯定可以做三機(jī)高可用,從 4.0 以后正式會(huì)推薦大家一種部署方式——每個(gè) ZONE 里就有一個(gè) 的節(jié)點(diǎn),叫做單機(jī)三副本,沒有太多額外的開銷。 層提供了業(yè)務(wù)連接不斷的能力,如果不需要這樣的能力,可以像使用 MySQL 一樣不需要部署 ,就可以達(dá)到比 MySQL 更好的高可用的能力。
比如最開始是完全單機(jī)部署,業(yè)務(wù)做一些原型實(shí)驗(yàn)就夠了。隨著業(yè)務(wù)規(guī)模擴(kuò)大,對(duì)于計(jì)算和存儲(chǔ)的要求越來越高過程中,可以把這一節(jié)點(diǎn)做垂直的擴(kuò)展,原來是 4 核,現(xiàn)在變成 16 核,如果在云上買,可以在 ECS 上直接申請(qǐng)?zhí)嵘?guī)格, 是可以充分利用所有增加的 CPU,提供一個(gè)更好的性能。
另外一個(gè)維度是,如果現(xiàn)在不需要高可用能力,不想付出三個(gè)節(jié)點(diǎn)的成本,那么主備庫就夠了, 同樣可以提供主備庫能力,這種高可用能力也是和傳統(tǒng)的數(shù)據(jù)庫相當(dāng)?shù)模鱾鋷煲彩俏覀兊囊粋€(gè)選項(xiàng)。
▋ 多形態(tài)、動(dòng)態(tài)可變
如果高可用能力要求越來越高,可以使用三節(jié)點(diǎn)。后面可能隨著業(yè)務(wù)的發(fā)展或企業(yè)規(guī)模的擴(kuò)大,可以進(jìn)化成一個(gè)完整形態(tài)的 分布式數(shù)據(jù)庫。更關(guān)鍵的是,這樣一個(gè)形態(tài)的變換或擴(kuò)展,里面每一個(gè)箭頭都可以反方向去做,每一個(gè)箭頭的變換都是動(dòng)態(tài)生效的,不需要去替換 二進(jìn)制,都可以全功能地在三種形態(tài)下使用,去做動(dòng)態(tài)的變換。
▋ 內(nèi)仍保存原生多租戶
我們?cè)谠O(shè)計(jì) 單機(jī)分布式一體化架構(gòu)時(shí),思考了一個(gè)問題。大家從使用 MySQL 到使用 有一個(gè)不適應(yīng)的地方: 有多租戶的能力,大家進(jìn)來需要?jiǎng)?chuàng)建一個(gè)租戶,后來我們和用戶、客戶做了很多討論,最后確定多租戶的特性即使是在單機(jī)情況下也是要保留的,特別是私有化部署和公有云部署時(shí)。
如果在私有化情況下去部署,很多小企業(yè)可能不想去部署復(fù)雜服務(wù)器的環(huán)節(jié),但現(xiàn)在買不到一核機(jī)器,有最小規(guī)格的硬件也有很多核,這種情況下如果不需要其他額外基礎(chǔ)設(shè)施的話, 的原生多租戶能力,可以把一個(gè)機(jī)器切成很多個(gè)數(shù)據(jù)庫來使用,無須額外的容器管理的系統(tǒng)。
對(duì)于大規(guī)格來說, 部署后可以做非常靈活的垂直伸縮。對(duì)于分布式不言而喻,如果在分布式場(chǎng)景下,更是可以有垂直擴(kuò)展和水平擴(kuò)展兩個(gè)方向的能力,并且這種能力是以租戶為單位的。一個(gè)租戶是 4 核×3 個(gè)容器,另外一個(gè)機(jī)器希望以單機(jī)方式運(yùn)行,可以直接給它 16 核,或者不希望做分布式,都是可以的,此時(shí),多租戶提供了一個(gè)可管理的粒度。
對(duì)于公有云的部署,或者希望在你的企業(yè)里一個(gè) 大集群,就更有價(jià)值了。即使是小規(guī)格,比如一個(gè) 的 通過 16 核方式啟動(dòng)起來,但希望有一個(gè)更小力度的租戶,比如 0.5 核的租戶。在數(shù)據(jù)庫內(nèi)部, 是可以支持 0.5 核租戶的,幫助用戶更加精細(xì)的控制成本,可以在云上做租戶內(nèi)垂直擴(kuò)展,也可以租戶間負(fù)載均衡,這兩個(gè)維度都可以去做彈性、自由伸縮。
在不同的形態(tài)下,我們都保留了 所有的功能以及多租戶的能力。
寫在最后
對(duì)用戶來說, 單機(jī)分布式一體化能力,有兩個(gè)維度的價(jià)值和意義:
第一, 既可以單機(jī)方式部署,提供單機(jī)數(shù)據(jù)庫相當(dāng)?shù)哪芰Γ⑶铱梢栽谌魏螘r(shí)刻,管理員可以去做形態(tài)的變換,由一個(gè)單機(jī)的形態(tài)變成分布式形態(tài),從分布式形態(tài)變回單機(jī)形態(tài),都可以做動(dòng)態(tài)變換的。
第二,即使是在分布式部署場(chǎng)景下,相較于其他分層的分布式數(shù)據(jù)庫, 的性能有很大的優(yōu)勢(shì),如果用戶做精細(xì)控制的話,單機(jī)事務(wù)比例增加以后,效率和單機(jī)數(shù)據(jù)庫也是相當(dāng)?shù)摹?/p>
我的分享就到這里,感謝大家對(duì) 的關(guān)注。謝謝大家!