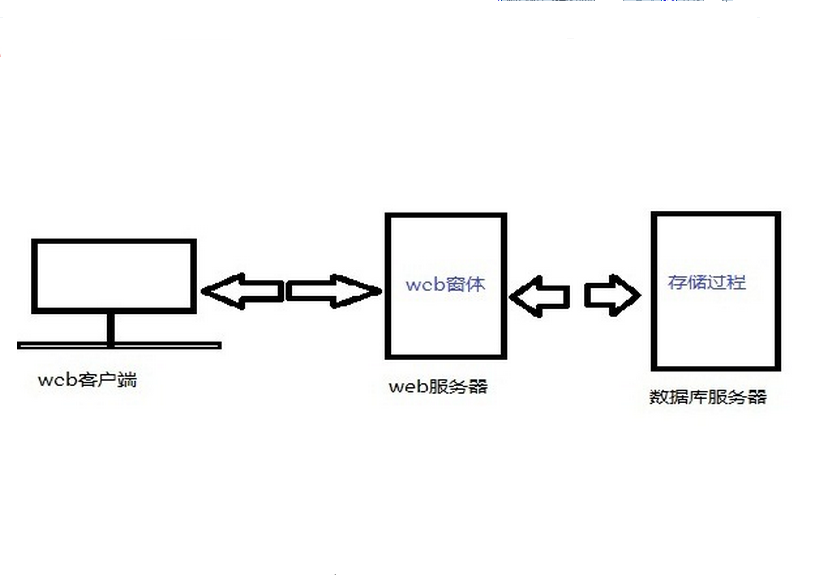
首先,來進行字面理解:
SQL中的存儲過程:當存儲過程執(zhí)行一次后,可以將語句放在緩存中,這樣下次執(zhí)行的時候直接使用緩存中的語句。
目的:實現(xiàn)重復調(diào)用的時候,可以提高存儲過程的性能。(類似于Java語言中的方法,它可以重復調(diào)用)
復雜使用
詳情鏈接:點擊打開鏈接
簡單的存儲過程理解和應用
存儲過程(常用語增刪改):
類似于Java的方法(將特定功能的語句,打包封裝到方法里面去,對外暴露方法名,隱藏實現(xiàn)的細節(jié),需要該功能時,調(diào)用方法名即可實現(xiàn)功能操作)
含義:一組預先編譯好的SQL語句的集合
原理:一組預先編譯好的SQL語句的集合(類似于批處理語句,但比批處理高級),對外暴露一個名字,執(zhí)行時調(diào)用這個名字即可。額外的好處:第一次調(diào)用過后,SQL語句已經(jīng)編譯完,當下一次調(diào)用的時候,不需要再次編譯,編譯次數(shù)減少,執(zhí)行效率提高。
目的:①提高代碼的重用性;②簡化操作;③減少編譯的次數(shù)創(chuàng)建帶參存儲過程,減少連數(shù)據(jù)庫服務器的連接次數(shù),提高執(zhí)行效率。
存儲過程的語法:
1.創(chuàng)建語法
存儲過程名(參數(shù)列表)
BEGIN
存儲過程體(一組合法的SQL語句)
END
注意點
(1)參數(shù)列表包括三部分:
參數(shù)模式 參數(shù)名 參數(shù)類型 例如:IN (20)
參數(shù)模式:
IN :修飾的參數(shù)可以作為輸入(需要調(diào)用方傳入值)
OUT :修飾的參數(shù)可以作為輸出,也就是說該參數(shù)可以作為返回值
INOUT :修飾的參數(shù)可以作為輸入,也可以作為輸出(既需要傳入值,又可以返回值)
(2)如果存儲過程體僅僅只有一句話,BEGIN……END可以省略。
(3)存儲過程體中的每條SQL語句的結(jié)尾要求必須加分號。存儲過程的結(jié)尾可以使用重新設置。
語法: 結(jié)束標記。例如:$ ($不是固定的創(chuàng)建帶參存儲過程,隨便取符號)
2.調(diào)用語法
CALL存儲過程名(實參列表)
示例1:
#創(chuàng)建帶空參數(shù)列表的存儲過程
$
()
BEGIN
INTO emp(ename ,job)
('ceshi','000'),('jsva','001'),('web','003');
END $
#調(diào)用
CALL () $
示例2.
#創(chuàng)建帶有參數(shù)列表的存儲過程
$

(IN (20))
BEGIN
b.*
FROM boys b
JOIN girl g ON b.id = g.
WHERE g.name = ;
END $
#調(diào)用
CALL ('劉亦菲') $
多個參數(shù)(暫時略)
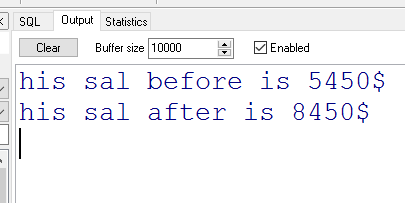
out模式的存儲過程(帶一個返回值)
#創(chuàng)建帶有參數(shù)列表的存儲過程
$
(IN (20),OUT (20))
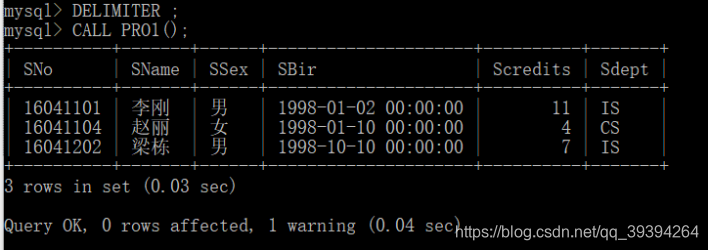
BEGIN
b. INTO
FROM boys b
JOIN girl g ON b.id = g.
WHERE g.name = ;
END $
#調(diào)用
SET @bName$
CALL ('劉亦菲',@bName) $
多個參數(shù)(暫時略)
inout模式的存儲過程
#創(chuàng)建帶inout模式參數(shù)列表的存儲過程
(INOUT a INT,INOUT b INT)
BEGIN

SET a=a*2;
SET b=b*2;
END
#調(diào)用
SET @m=10$
SET @n=20$
CALL (@m,@n)$
@m,@n$
存儲過程的查看和刪除
#查看存儲過程的信息
SHOW ;
#存儲過程的刪除(一次只能刪除一個)
DROP ;
DROP ,;
存儲過程的不能修改存儲過程體