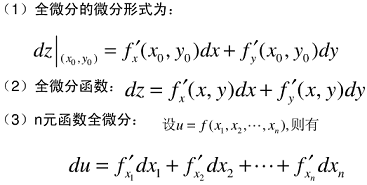王小新 編譯自
量子位 出品 | 公眾號
在調整模型更新權重和偏差參數的方式時,你是否考慮過哪種優化算法能使模型產生更好且更快的效果?應該用梯度下降,隨機梯度下降,還是Adam方法?
這篇文章介紹了不同優化算法之間的主要區別,以及如何選擇最佳的優化方法。
什么是優化算法?
優化算法的功能,是通過改善訓練方式,來最小化(或最大化)損失函數E(x)。
模型內部有些參數,是用來計算測試集中目標值Y的真實值和預測值的偏差程度的,基于這些參數,就形成了損失函數E(x)。
比如說,權重(W)和偏差(b)就是這樣的內部參數,一般用于計算輸出值,在訓練神經網絡模型時起到主要作用。
在有效地訓練模型并產生準確結果時,模型的內部參數起到了非常重要的作用。這也是為什么我們應該用各種優化策略和算法,來更新和計算影響模型訓練和模型輸出的網絡參數,使其逼近或達到最優值。
優化算法分為兩大類:
1. 一階優化算法
這種算法使用各參數的梯度值來最小化或最大化損失函數E(x)。最常用的一階優化算法是梯度下降。
函數梯度:導數dy/dx的多變量表達式,用來表示y相對于x的瞬時變化率。往往為了計算多變量函數的導數時,會用梯度取代導數,并使用偏導數來計算梯度。梯度和導數之間的一個主要區別是函數的梯度形成了一個向量場。
因此,對單變量函數神經網絡 損失函數種類,使用導數來分析;而梯度是基于多變量函數而產生的。更多理論細節在這里不再進行詳細解釋。
2. 二階優化算法
二階優化算法使用了二階導數(也叫做方法)來最小化或最大化損失函數。由于二階導數的計算成本很高,所以這種方法并沒有廣泛使用。
詳解各種神經網絡優化算法梯度下降
在訓練和優化智能系統時,梯度下降是一種最重要的技術和基礎。梯度下降的功能是:
通過尋找最小值,控制方差神經網絡 損失函數種類,更新模型參數,最終使模型收斂。
網絡更新參數的公式為:θ=θ?η×?(θ).J(θ)?,其中η是學習率,?(θ).J(θ)是損失函數J(θ)的梯度。
這是在神經網絡中最常用的優化算法。
如今,梯度下降主要用于在神經網絡模型中進行權重更新,即在一個方向上更新和調整模型的參數,來最小化損失函數。
2006年引入的反向傳播技術,使得訓練深層神經網絡成為可能。反向傳播技術是先在前向傳播中計算輸入信號的乘積及其對應的權重,然后將激活函數作用于這些乘積的總和。這種將輸入信號轉換為輸出信號的方式,是一種對復雜非線性函數進行建模的重要手段,并引入了非線性激活函數,使得模型能夠學習到幾乎任意形式的函數映射。然后,在網絡的反向傳播過程中回傳相關誤差,使用梯度下降更新權重值,通過計算誤差函數E相對于權重參數W的梯度,在損失函數梯度的相反方向上更新權重參數。
圖1:權重更新方向與梯度方向相反
圖1顯示了權重更新過程與梯度矢量誤差的方向相反,其中U形曲線為梯度。要注意到,當權重值W太小或太大時,會存在較大的誤差,需要更新和優化權重,使其轉化為合適值,所以我們試圖在與梯度相反的方向找到一個局部最優值。
梯度下降的變體
傳統的批量梯度下降將計算整個數據集梯度,但只會進行一次更新,因此在處理大型數據集時速度很慢且難以控制,甚至導致內存溢出。
權重更新的快慢是由學習率η決定的,并且可以在凸面誤差曲面中收斂到全局最優值,在非凸曲面中可能趨于局部最優值。
使用標準形式的批量梯度下降還有一個問題,就是在訓練大型數據集時存在冗余的權重更新。
標準梯度下降的上述問題在隨機梯度下降方法中得到了解決。
1. 隨機梯度下降(SDG)
隨機梯度下降( ,SGD)對每個訓練樣本進行參數更新,每次執行都進行一次更新,且執行速度更快。
θ=θ?η??(θ) × J(θ;x(i);y(i)),其中x(i)和y(i)為訓練樣本。
頻繁的更新使得參數間具有高方差,損失函數會以不同的強度波動。這實際上是一件好事,因為它有助于我們發現新的和可能更優的局部最小值,而標準梯度下降將只會收斂到某個局部最優值。
但SGD的問題是,由于頻繁的更新和波動,最終將收斂到最小限度,并會因波動頻繁存在超調量。
雖然已經表明,當緩慢降低學習率η時,標準梯度下降的收斂模式與SGD的模式相同。
圖2:每個訓練樣本中高方差的參數更新會導致損失函數大幅波動,因此我們可能無法獲得給出損失函數的最小值。
另一種稱為“小批量梯度下降”的變體,則可以解決高方差的參數更新和不穩定收斂的問題。
2. 小批量梯度下降
為了避免SGD和標準梯度下降中存在的問題,一個改進方法為小批量梯度下降(Mini Batch ),因為對每個批次中的n個訓練樣本,這種方法只執行一次更新。
使用小批量梯度下降的優點是:
1)可以減少參數更新的波動,最終得到效果更好和更穩定的收斂。

2)還可以使用最新的深層學習庫中通用的矩陣優化方法,使計算小批量數據的梯度更加高效。
3)通常來說,小批量樣本的大小范圍是從50到256,可以根據實際問題而有所不同。
4)在訓練神經網絡時,通常都會選擇小批量梯度下降算法。
這種方法有時候還是被成為SGD。
使用梯度下降及其變體時面臨的挑戰
1.很難選擇出合適的學習率。太小的學習率會導致網絡收斂過于緩慢,而學習率太大可能會影響收斂,并導致損失函數在最小值上波動,甚至出現梯度發散。
2.此外,相同的學習率并不適用于所有的參數更新。如果訓練集數據很稀疏,且特征頻率非常不同,則不應該將其全部更新到相同的程度,但是對于很少出現的特征,應使用更大的更新率。
3.在神經網絡中,最小化非凸誤差函數的另一個關鍵挑戰是避免陷于多個其他局部最小值中。實際上,問題并非源于局部極小值,而是來自鞍點,即一個維度向上傾斜且另一維度向下傾斜的點。這些鞍點通常被相同誤差值的平面所包圍,這使得SGD算法很難脫離出來,因為梯度在所有維度上接近于零。
進一步優化梯度下降
現在我們要討論用于進一步優化梯度下降的各種算法。
1. 動量
SGD方法中的高方差振蕩使得網絡很難穩定收斂,所以有研究者提出了一種稱為動量()的技術,通過優化相關方向的訓練和弱化無關方向的振蕩,來加速SGD訓練。換句話說,這種新方法將上個步驟中更新向量的分量’γ’添加到當前更新向量。
V(t)=γV(t?1)+η?(θ).J(θ)
最后通過θ=θ?V(t)來更新參數。
動量項γ通常設定為0.9,或相近的某個值。
這里的動量與經典物理學中的動量是一致的,就像從山上投出一個球,在下落過程中收集動量,小球的速度不斷增加。
在參數更新過程中,其原理類似:
1)使網絡能更優和更穩定的收斂;
2)減少振蕩過程。
當其梯度指向實際移動方向時,動量項γ增大;當梯度與實際移動方向相反時,γ減小。這種方式意味著動量項只對相關樣本進行參數更新,減少了不必要的參數更新,從而得到更快且穩定的收斂,也減少了振蕩過程。
2. 梯度加速法
一位名叫Yurii 研究員,認為動量方法存在一個問題:

如果一個滾下山坡的球,盲目沿著斜坡下滑,這是非常不合適的。一個更聰明的球應該要注意到它將要去哪,因此在上坡再次向上傾斜時小球應該進行減速。
實際上,當小球達到曲線上的最低點時,動量相當高。由于高動量可能會導致其完全地錯過最小值,因此小球不知道何時進行減速,故繼續向上移動。
Yurii 在1983年發表了一篇關于解決動量問題的論文,因此,我們把這種方法叫做梯度加速法。
在該方法中,他提出先根據之前的動量進行大步跳躍,然后計算梯度進行校正,從而實現參數更新。這種預更新方法能防止大幅振蕩,不會錯過最小值,并對參數更新更加敏感。
梯度加速法(NAG)是一種賦予了動量項預知能力的方法,通過使用動量項γV(t?1)來更改參數θ。通過計算θ?γV(t?1),得到下一位置的參數近似值,這里的參數是一個粗略的概念。因此,我們不是通過計算當前參數θ的梯度值,而是通過相關參數的大致未來位置,來有效地預知未來:
V(t)=γV(t?1)+η?(θ)J( θ?γV(t?1) ),然后使用θ=θ?V(t)來更新參數。
現在,我們通過使網絡更新與誤差函數的斜率相適應,并依次加速SGD,也可根據每個參數的重要性來調整和更新對應參數,以執行更大或更小的更新幅度。
3. 方法
方法是通過參數來調整合適的學習率η,對稀疏參數進行大幅更新和對頻繁參數進行小幅更新。因此,方法非常適合處理稀疏數據。
在時間步長中,方法基于每個參數計算的過往梯度,為不同參數θ設置不同的學習率。
先前,每個參數θ(i)使用相同的學習率,每次會對所有參數θ進行更新。在每個時間步t中,方法為每個參數θ選取不同的學習率,更新對應參數,然后進行向量化。為了簡單起見,我們把在t時刻參數θ(i)的損失函數梯度設為g(t,i)。
圖3:參數更新公式
方法是在每個時間步中,根據過往已計算的參數梯度,來為每個參數θ(i)修改對應的學習率η。
方法的主要好處是,不需要手工來調整學習率。大多數參數使用了默認值0.01,且保持不變。
方法的主要缺點是,學習率η總是在降低和衰減。
因為每個附加項都是正的,在分母中累積了多個平方梯度值,故累積的總和在訓練期間保持增長。這反過來又導致學習率下降,變為很小數量級的數字,該模型完全停止學習,停止獲取新的額外知識。
因為隨著學習速度的越來越小,模型的學習能力迅速降低,而且收斂速度非常慢,需要很長的訓練和學習,即學習速度降低。
另一個叫做的算法改善了這個學習率不斷衰減的問題。
4. 方法
這是一個的延伸方法,它傾向于解決其學習率衰減的問題。不是累積所有之前的平方梯度,而是將累積之前梯度的窗口限制到某個固定大小w。
與之前無效地存儲w先前的平方梯度不同,梯度的和被遞歸地定義為所有先前平方梯度的衰減平均值。作為與動量項相似的分數γ,在t時刻的滑動平均值Eg2僅僅取決于先前的平均值和當前梯度值。
Eg2=γ.Eg2+(1?γ).g2(t),其中γ設置為與動量項相近的值,約為0.9。
Δθ(t)=?η?g(t,i).
θ(t+1)=θ(t)+Δθ(t)
圖4:參數更新的最終公式
方法的另一個優點是,已經不需要設置一個默認的學習率。
目前已完成的改進
1)為每個參數計算出不同學習率;
2)也計算了動量項;
3)防止學習率衰減或梯度消失等問題的出現。
還可以做什么改進?
在之前的方法中計算了每個參數的對應學習率,但是為什么不計算每個參數的對應動量變化并獨立存儲呢?這就是Adam算法提出的改良點。
Adam算法
Adam算法即自適應時刻估計方法( ),能計算每個參數的自適應學習率。這個方法不僅存儲了先前平方梯度的指數衰減平均值,而且保持了先前梯度M(t)的指數衰減平均值,這一點與動量類似:
M(t)為梯度的第一時刻平均值,V(t)為梯度的第二時刻非中心方差值。
圖5:兩個公式分別為梯度的第一個時刻平均值和第二個時刻方差
則參數更新的最終公式為:
圖6:參數更新的最終公式
其中,β1設為0.9,β2設為0.9999,?設為10-8。
在實際應用中,Adam方法效果良好。與其他自適應學習率算法相比,其收斂速度更快,學習效果更為有效,而且可以糾正其他優化技術中存在的問題,如學習率消失、收斂過慢或是高方差的參數更新導致損失函數波動較大等問題。
對優化算法進行可視化
圖8:對鞍點進行SGD優化
從上面的動畫可以看出,自適應算法能很快收斂,并快速找到參數更新中正確的目標方向;而標準的SGD、NAG和動量項等方法收斂緩慢,且很難找到正確的方向。
結論
我們應該使用哪種優化器?
在構建神經網絡模型時,選擇出最佳的優化器,以便快速收斂并正確學習,同時調整內部參數,最大程度地最小化損失函數。
Adam在實際應用中效果良好,超過了其他的自適應技術。
如果輸入數據集比較稀疏,SGD、NAG和動量項等方法可能效果不好。因此對于稀疏數據集,應該使用某種自適應學習率的方法,且另一好處為不需要人為調整學習率,使用默認參數就可能獲得最優值。
如果想使訓練深層網絡模型快速收斂或所構建的神經網絡較為復雜,則應該使用Adam或其他自適應學習速率的方法,因為這些方法的實際效果更優。
希望你能通過這篇文章,很好地理解不同優化算法間的特性差異。
相關鏈接:
二階優化算法:
梯度加速法:
【完】
一則通知
量子位正在組建自動駕駛技術群,面向研究自動駕駛相關領域的在校學生或一線工程師。歡迎大家加量子位微信(),備注“自動駕駛”申請加入哈~
招聘
量子位正在招募編輯記者、運營、產品等崗位,工作地點在北京中關村。相關細節,請在公眾號對話界面,回復:“招聘”。
△掃碼強行關注『量子位』
追蹤人工智能領域最勁內容