

加入極市專業CV交流群,與6000+來自騰訊,華為,百度,北大,清華,中科院等名企名校視覺開發者互動交流!更有機會與李開復老師等大牛群內互動!
同時提供每月大咖直播分享、真實項目需求對接、干貨資訊匯總,行業技術交流。點擊文末“閱讀原文”立刻申請入群~
作者 |
來源|
神經網絡構建好,訓練不出好的效果怎么辦?明明說好的擬合任意函數(一般連續)(為什么?可以參考),說好的足夠多的數據('s_razor),仔細設計的神經網絡都可以得到比其他算法更好的準確率和泛化性呢(當然不是我說的),怎么感覺不出來呢?
很直觀,因為神經網絡可以隨意設計,先驗假設較少,參數多,超參數更多,那模型的自由度就非常高了,精心設計對于新手就變得較難了。這里講一些最簡單的trick,肯定不全面,歡迎大家留言補充。因為我也是新手!
下面介紹一些值得注意的部分,有些簡單解釋原理,具體細節不能面面俱到,請參考專業文章
那我們直接從拿到一個問題決定用神經網絡說起。一般而言,

那如果GC失敗,可能網絡某些部分有問題,也有可能整個網絡都有問題了!你也不知道哪出錯了,那怎么辦呢?構建一個可視化過程監控每一個環節,這可以讓你清楚知道你的網絡的每一地方是否有問題!!這里還有一個trick,先構建一個簡單的任務(比如你做MNIST數字識別,你可以先識別0和1,如果成功可以再加入更多識別數字);然后從簡單到復雜逐步來檢測你的model,看哪里有問題。舉個例子吧,先用固定的data通過單層softmax看效果,然后BP效果,然后增加單層單個看效果;增加一層多個;增加bias。。。。。直到構建出最終的樣子,系統化的檢測每一步!

更放心一點,可視化每一層輸出的取值范圍,梯度范圍,通過修改使其落入激活函數的中間區域范圍(梯度類似線性);如果是ReLU則保證不要輸出大多為負數就好,可以給bias一點正直的噪聲等。當然還有一點就是不能讓神經元輸出一樣,原因很簡單
mini-batch好處主要有:可以用矩陣計算加速并行;引入的隨機性可以避免困在局部最優值;并行化計算多個梯度等。在此基礎上一些改進也是很有效的(因為SGD真的敏感),比如,他的意圖就是在原先的跟新基礎上增加一點摩擦力,有點向加速度對速度的作用,如果多次更新梯度都往一個方向,說明這個方向是對的,這時候增加跟新的步長,突然有一個方向,只會較少影響原來的方向,因為可以較少的數據帶來的誤差。當你使用時可以適當減小global rate

方案一:當驗證誤差不再下降時,lr減小為原來的0.5
方案二:采用理論上可以保證收斂的減小比例,O(1/t),t是迭代次數
方案三:最好用自適應的學習率,比如Adagrad(.2010)等
簡要說明一下,Adagrad非常適合數據出現頻度不一樣的模型,比如,你肯定希望出現非常少的詞語權重更新非常大,讓它們遠離常規詞,學習到向量空間中距離度量的意義,出現非常多的詞(the,very,often)每次更新比較小。
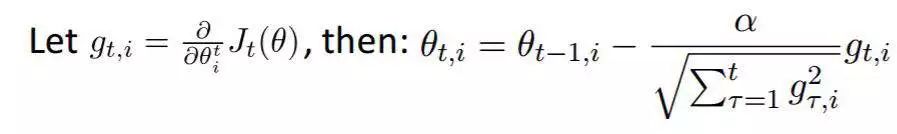
adagrad
按照上面式子,如果進入一個local optimum,參數可能無法更新時,可以考慮每隔一段epoch,reset sum項
如果沒有,想辦法讓它過擬合!(?!哈哈),一般而言,當參數多于數據時,模型是有能力記住數據的,總歸先保證模型的能力么
如果過擬合了,那么就可以進一步優化啦,一般深度學習的方法都是來自于更好的,解決過擬合很多方法在此就不多論述了。比如減小模型(layers,units);L1,L2正則();(按照數據集大小,每隔一段epoch(比如小數據集每隔5epoch,大的每隔(1/3epoch))保存模型,最后選擇最小的模型);;Dropout;data
(CNN 一些變化不變性要注意)等
======================================================
大體流程如上,再引一篇大神之作, for -Based of Deep Y. Bengio(2012),額外提到的有預訓練。其實數據不夠時也可以找類似任務做遷移學習,fine-tuning等。
最后,可以看到一個網絡那么多的超參數,怎么去選這些超參數呢?文章也說了:
search!
以上提的多是 ,對于 可以做fine tuning
接下來按一些模塊具體列舉下,歡迎補充!!
論文鏈接:
標準化()
很多模型都需要,在此不多論述,神經網絡假設inputs/outputs服從近似均值為0方差為1分布。主要為了公平對待每個特征;使優化過程變得平穩;消除量綱影響等
z-score; min-max; decimal scaling等
檢查結果(Results Check)
有點類似于在模型中按一個監控系統(預處理,訓練,預測過程中都要),這個步驟可以幫助你發現你的模型在哪里出了問題,最好可以找到可視化的方法,一目了然,比如圖像方面就很直觀了。
預處理(Pre- Data)
現實中同樣的數據可以有不同的表達方式,比如移動的汽車,你從不同角度位置去觀察,它做的都是同樣的事情。你應該確保從南面觀察和從西面觀察的同樣的數據,應該是相似的!
正則化()
增加Dropout,隨機過程,噪聲,等。就算數據足夠多,你認為不可能over-fitting,那么最好還是有正則,如dropout(0.99)
Batch Size太大
太大的會減的隨機性,對模型的精度產生負面影響。
如果可以容忍訓練時間過長,最好開始使用盡量小的batch size(16,8,1)
學習率lr
去掉 (一般默認有),訓練過程中,找到最大的,使模型error不會爆掉的lr,然后用稍微小一點的lr訓練
最后一層的激活函數
限制輸出的范圍,一般不用任何激活
需要仔細考慮輸入是什么,標準化之后的輸出的取值范圍,如果輸出有正有負,你用ReLU,sigmoid明顯不行;多分類任務一般用softmax(相當于對輸出歸一化為概率分布)
Bad (Dead Neurons)
使用ReLU激活函數,由于其在小于零范圍梯度為0,可能會影響模型性能,甚至模型不會在更新
當發現模型隨著epoch進行,訓練error不變化,可能所以神經元都“死”了。這時嘗試更換激活函數如,ELU,再看訓練error變化
初始化權重
一般說隨機初始化為一些小的數,沒那么簡單,一些網絡結構需要一些特定的初始化方法,初始化不好很可能得不到文章上的效果!可以去嘗試一些流行的找到有用的初始化
網絡太深
都說深度網絡精度更高,但深度不是盲目堆起來的,一定要在淺層網絡有一定效果的基礎上,增加深度。深度增加是為了增加模型的準確率,如果淺層都學不到東西,深了也沒效果。
開始一般用3-8層,當效果不錯時,為了得到更高的準確率,再嘗試加深網絡
Hidden neurons的數量
最好參考在相似的任務上結構,一般256-1024
太多:訓練慢,難去除噪聲(over-fitting)
太少:擬合能力下降
loss
多分類任務一般用cross-entropy不用MSE
AE降維
對中間隱層使用L1正則,通過懲罰系數控制隱含節點稀疏程度
SGD
不穩定算法,設定不同的學習速率,結果差距大,需要仔細調節
一般希望開始大,加速收斂,后期小,穩定落入局部最優解。
也可采用自適應的算法,Adam,Adagrad,等減輕調參負擔(一般使用默認值就可以)
CNN的使用
神經網絡是特征學習方法,其能力取決隱層,更多的連接意味著參數爆炸的增長,模型復雜直接導致很多問題。比如嚴重過擬合,過高的計算復雜度。
CNN其優越的性能十分值得使用,參數數量只和卷積核大小,數量有關,保證隱含節點數量(與卷積步長相關)的同時,大量降低了參數的數量!當然CNN更多用于圖像,其他任務靠你自己抽象啦,多多嘗試!
這里簡單介紹一些CNN的trick
RNN使用
小的細節和其他很像,簡單說兩句個人感覺的其他方面吧,其實RNN也是結構
今天就到這了,歡迎補充。