

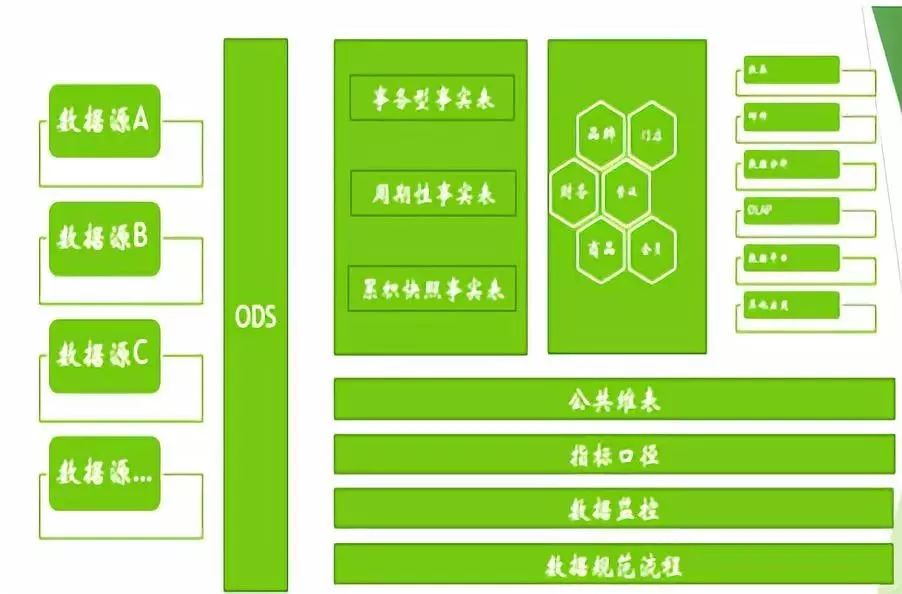
我接下來會對這張圖的各個模塊進行講解
一、首先是數據源和ODS層
數據倉庫需要將盡量多的數據源匯合在一起,數據源越豐富,后續的數據應用也會更實用。所以數據倉庫需要經常考慮要接入哪些數據、接入這些數據的代價是什么,能得到的產出有多少。
常見的數據源有業務系統數據、埋點、日志類數據、網絡輿情、爬蟲數據和文件數據等。
ODS層的數據會完全和數據源一致,起到的作用是將不同源的數據進行整合,同時會保留完整的歷史----相對于業務系統線上數據可能會定期清理歷史數據、不穩定的文件可能會丟失問題,ODS一定會有最全的數據。。。同時,ODS也是一份可靠的數據備份,并非簡單的抽取。
我們的ODS層數據是用的hdfs存儲,在和業務系統同步數據時也踩過主鍵數據更新的坑,這里不詳細說了哈,有興趣的下去交流,如果有疑問的我一定會提供力所能及的幫助
二、公共維表層
我們最開始做數倉的時候其實也沒有考慮的這么長遠。維表就是供給dw的數據使用。
但是隨著業務的發展,BI也越來越龐大,后面所有DW+DM+RPT+各種數據應用,光維表就有接近200張。
里面絕大多數都是重復的,所以后續做出改良,將所有的維表進行整合,做的過程中就會發現,維表不僅僅是業務系統的映射,只要建模合理,維表是可以直接對外開放的,例如直接作為報表中某個查詢維度的枚舉值、給某個數據應用提供接口等等。
除了普通的維表外,我們往往還會制作很多的手工維表----有業務含義,但是往往是某個業務表的某個字段,不是通過etl抽取而來,例如商品類型
歷史維度表----需要關注某些維度在具體時間點的表現情況,例如如果業務形態上商品價格會不定期的調整,那么可能需要制定歷史商品表,來反應每個時間節點上的商品信息。
此外還會制作大維表--大維表主要用于直接和事實表關聯,他會冗余很多維度子集的信息,例如在商品維表中,我們一般會將其類目ID、類目名稱冗余進去,這樣事實表只需要和商品維表1張表關聯,就能取到足夠多的維度信息。
維表的制作一定不要忘記做缺省值,缺省值可以保證后面的事實表與維表關聯時均可以使用join關聯,不需要讓數據倉庫的使用人員記憶過多的業務邏輯,更重要的是讓直接展現給業務方的數據應用展現數據的時候,不會動不動出現null值這種尷尬的事情
三、數倉事實表+集市層
事實表會經常提到數據建模的概念,因為在業務系統中庫表結構的設計是為了滿足業務系統的快速、穩定的運行,所以會犧牲統計查詢上的便利和效率,在做數據倉庫時,需要充分的考慮業務方的統計需求去實現。
除了常見的業務事實表之外,我們還有一些常用的事實表類型
累計快照事實表----確定事實粒度后,將業務方關心的、在同一事實粒度下的數據盡量的融合在一起--------例如業務方關注訂單明細、乃至后續發生了售后、退單等行為,那么我們會將訂單和售后單融合,形成"訂單生命周期"。
累計快照事實表----確定事實粒度后,將業務方關心的、在同一事實粒度下的數據盡量的融合在一起--------例如業務方關注訂單明細、乃至后續發生了售后、退單等行為,那么我們會將訂單和售后單融合,形成"訂單生命周期"。
周期性事實表----業務方關心固定周期的統計數據--------例如商品庫存,一般庫存是由訂銷存費計算得出,如果放任后續數據應用去統計,則會導致各個應用的重復計算,且如果每個應用都是即席查詢,對集群性能也是很大的考驗,所以一般會針對這種需求,做成周期性事實表。
四、指標口徑
指標口徑是公司層面的溝通問題,如果沒有指標口徑的管理,各個業務部門之間的溝通會變的異常困難,同樣每天銷售額,不同業務部門之間可能理解都存在差異。而數據倉庫的研發人員也在頻繁的對外解釋數據應用中繁雜的指標中疲于奔命。
所以指標口徑的管理應在數倉的迭代過程中持續不斷的去完善和優化,在業務少且簡單的情況下也應當有完備的文檔和數據字典以供查閱。在業務量增大或者變得越來越復雜時,維護的指標口徑會急劇增多,數據字段和文檔往往不能滿足口徑管理需求,這時就需要對指標口徑進行分類。
結合業務元數據和技術元數據以及方便后續擴展血緣關系,指標口徑可以分為以下三類:
基礎指標----最基本的指標,往往是在某張事實表中直接統計而來
衍生指標----【基礎指標】加上了修飾詞,同樣是某張事實表統計出來,但是帶上了一些過濾條件
復合指標----多個基礎指標或者衍生指標計算而來
按照上述的分類方法后,我們只需要重點維護好基礎指標即可,衍生指標和復合指標可以根絕業務方的想象力隨意擴展,也不會影響我們指標體系的基本盤面
指標口徑就是我們的【業務元數據】,大家可以發現業務元數據 其實和 SQL有非常緊密的對應關系,所有的指標都是通過sum/count/count 而來。
在此基礎上,可以進一步的對我們集群上所有跑的SQL進行解析
就可以將技術元數據和業務元數據進行打通,,,這些可以幫助我們進行數倉建模,可以了解業務方更了解哪些數據等等。
五、數據監控
這個我簡單介紹下,數據倉庫所有的數據均是通過ETL而來,從源數據到最終的數據應用的鏈路往往會很長,所以我們還需要針對整個ETL流程做監控,一般我們對數據的指標波動范圍、一致性、和數據業務邏輯進行監控。
監控是掛在每個ETL的作業上,根據作業程度的不同,又會分成阻斷和繼續兩種不同的級別。如果作業很重要,數據異常則需要研發人員及時處理,會報錯、阻止作業鏈的執行并打電話通知。
如果作業不是非常重要可以第二天處理的,則設置為繼續,后續作業繼續執行,發郵件報錯但是不會在晚上集群跑批時強行拉研發起來處理
六、數據流程規范
數據倉庫是數據的下游,數據是由業務方、用戶方使用業務系統產生,最后才能被數據倉庫抽取到,整個環節如果有了偏差,則會導致數據處理異常的困難,而業務系統的研發人員往往只會保障功能上的需求,對數據上的需求往往會有所紕漏,所以好的數據倉庫,一定會指定好對應的數據規范,下面列舉幾個實際數倉迭代中我們合業務人員一起推動,給業務研發人員指定的規范。
建表規范:所有的業務表均需要有創建時間和更新時間,且這兩個時間是數據庫自己更新和寫入,不參與任何業務邏輯----應該規范的公司里一定會有這個研發規范,但是在中小型團隊中容易被忽略,導致數倉構建時,遇到不知道怎么抽取數據的問題。
url規范:在前端的url中會帶入埋點相關信息且按照規范的格式存儲,后續數倉消費到的埋點日志會自動寫入數倉,無需數倉人員二次開發----極大的簡化了數倉的研發周期。
七、數據應用
每個公司的數據應用可能都不太一樣,這里我列舉下因為離數據最近,數倉的小伙伴們經常會負責的數據應用。
報表工具----固化需求配置成報表,每日展示。
郵件平臺----未固化需求通過SQL定時執行生成郵件發送給業務方--配郵件也很麻煩,但是總會比制作報表方便快捷。
olap平臺----可以選擇維度、指標進行即席查詢的數據平臺,部署簡單,本身olap需要的數據也是數倉構建的必經之路,一般一個集市層的表直接拖出了就可以放入olap系統中。
數據平臺----供有數據處理能力的人員使用,構建數據倉庫后,數據一定是易用的,可以讓有能力的業務方定制化的查詢數據。
好啦,以上就是我今天要分享的內容,希望對大家有所幫助,有疑問的可以在群里直接提問,我會盡我所能的提供幫助
Q&A 互動問題:
Q : 有很多ETL,如何監控他們的執行情況呢,有沒有可視化的界面?
A : 我們的調度系統是zeus,因為有這個監控的需求,所以讓架構的小伙伴進行了二開,可以直接在界面上配置檢查的SQL,我們的小伙伴二開的工期加上后面還調整了一次,大概是2人時,就是在作業執行完之后,會去查結果數據是否符合預期,就是在作業執行玩之后,會去查結果數據是否符合預期。
Q:數據是事實進ods 么,業務數據更改是如何更新
A:我們的數據規范要求業務系統中全部會寫,然后晚上集群調度的時候統一批處理大于前一天的數據。
Q:如果每次只抽a 和 b表1天的更新數據,然后要組合成c表,處理完成后清除抽取的數據,但可能b表并沒有更新,所以在組合時c表就會有很多空字段,那些字段的數據在源系統中存在,有什么解決方法嗎?
A:應該缺失了ODS層,建議最好增加這個層級,抽取a的數據后存入ods層的a表,抽取b后存入ods層的b表,然后后續再對a和b做處理,就能避免你說的問題。
Q:請問使用數據倉庫的業務對數據倉庫的構建有什么具體的要求么?一般在接手設計一個數據倉庫時,業務部門都會提出什么樣的要求呢?
A: 在構建數倉的時候,其實業務部門肯定已經有數據需求了,第一可以去看看他們在看什么樣的數據,有哪些維度、指標,然后帶著問題去研究業務庫。
Q:你們的數據是t +1,你們有沒有事實數據需求?有沒有想過事實流入方案。olap 是用的什么技術實現?
A:有實時數據,實時數據我們搞過3套方案。第一套是業務數據直接使用關系型數據庫,存少量數據,流量數據用spark計算,然后在前端統一去展現,第二套是在業務接口里設計埋點,比如調訂單接口的時候直接一個http請求將訂單發送到kafka,然后spark消費出實時的訂單數,第三種是mysql特有的,直接將有更新的數據發送到hdfs,然后查詢的時候查最后一個版本的數據。
Q:請問,有沒有一些小經驗可以優雅地設計數據分層
A:數據分層不要太多,你剛剛給我說的阿里的方案我也是剛剛去Google查的,然后發現大家的思路是一致的,ods層負責存儲明細數據、保留歷史,dw負責清洗轉換,做指標邏輯等,dm層做數據建模,按主題建寬表,直接對外。
Q:在數據的抽取過程中會產生的文件,相對來說不是很重要,但是比較占空間,需要保留嗎?
A:可以定期清理下就可以了,保留最近7天這樣,保障近期出了問題可以查,也可以設置大小
感謝 貓友會自愿者 陳龍文的文章整理,!(排版小貓助手~)
添加小貓助手,加入貓友會交流群
