

形象墻 要求有立體效果圖 樓層分布圖 辦公室門牌 室內導示符號 廁所,安全出口,休息室,,入口,更衣室,樓梯,安靜,禁止吸煙,餐廳 選做 廣告系統 廣告系統包括報紙廣告、雜志廣告、企業產品海報、公司宣傳冊、新聞公報、年報、網頁、電視廣告等內容。) 宣傳欄 燈箱 VI[視覺識別]應用系統設計 桌旗:分為橫豎兩種構圖。 橫向規格:一般為210*140mm豎向140*210mm 材料和印制:有紙面,綢面等。一般要求硬挺,精致程度較高。 桌旗多為對式擺放,設計時既可以讓兩面旗完全一樣,也可以考慮在色彩上進行正負調換。 * * VI[視覺識別]應用系統設計 公共關系贈品系統 必做:手提袋 選做:臺歷、打火機、手表、鼠標墊 要求: 至少有兩個面的平面圖。 立體圖 包裝用品系統 選做:做一款產品包裝,有四個面的平面圖,立體效果圖。 餐飲類公司最好做一整套餐具及打包袋的設計 旗幟規劃類 選做: 旗幟規劃類 司旗:一兩面代表自己形象的旗幟。(其稱謂根據具體情況定,如司旗,店旗,校旗等) 大型企業、機構規格為-1440*960mm,中小型企業、機構-960*640mm 材料及印制工藝:大多情況下,使用尼龍防水面料,以膠印工藝印制。
質量要求較高時,可以采用特殊面料,要也可以使用繡制工藝來制作旗幟。 場合:企業大門或主建筑物前的旗桿上 設計要素,包括企業標志、名稱、專用色彩。由于飄動中的旗幟很難看清楚太多的細節,所以設計要求簡潔、明確,大效果強烈;一目了然,尤其突出色彩和標志這兩個核心要素。 旗幟規劃類 吊旗:多半是為了活躍氣氛、增加熱鬧程度而懸掛的。也分為形象旗和廣告旗兩類。有時兩旗一起用。 規格:多為正方形和矩形兩種,也有三角形、異形的吊旗樣式 材料及印制:大多數都采用紙面印刷,也有個別采用布面印制的。 懸掛方式:可以直接釘于頂面懸掛,也可貼掛,拉繩橫向串掛。 旗幟規劃類 豎旗:是為烘托氣氛而使用的旗幟。分形象旗和廣告旗。 廣告旗是根據具體的廣告主題來設計的。 規格一般為750mm,長度具情況而定,一般燈桿堅旗的規格為750*1500mm 使用場合:活動中如周年慶典,也可在城市指定的街道懸掛燈桿豎旗 設計要求:形象豎旗與司旗的設計從要素上講,基本上是一致的。由于固定,整個幅面都能展現,可以考慮加上企業標語。 旗幟規劃類 桌旗:分為橫豎兩種構圖。 橫向規格:一般為210*140mm豎向140*210mm 材料和印制:有紙面,綢面等。
一般要求硬挺,精致程度較高。 桌旗多為對式擺放,設計時既可以讓兩面旗完全一樣,也可以考慮在色彩上進行正負調換。 服裝飾品系統 必做: 領導、員工(男女)服裝各一套,如背面有文字或圖案等設計,要有背面的設計圖。 T恤衫 徽章 選做: 按季節分:春秋裝,夏裝,冬裝 工作服 帽子、領帶、領帶夾。 服裝服飾系統 設計元素: VI基礎設計要素,廣告語等 可設計的位置:胸口、袋邊、背后、褲縫、袖縫及配飾的帽徽、胸卡、徽章、領帶、腰帶、紐扣等處, 設計手法有鑲、嵌、銹、滾、印等。 交通系統設計 必做:轎車、面包車、大客車、貨車四種車的體側和后面等。 可設計元素: VI基礎設計要素,廣告語等 企業或公司產品宣傳海報。 室內外環境及導示識別系統 牌扁 牌扁參考規范 企業方位指示牌參考規范 指路類標識 VI[視覺識別]基礎系統設計 VI 設計作業規范參考 應用系統 VI手冊的裝訂方式 環裝 膠裝 作業---VI手冊封面 作業---VI手冊封面 必有元素: 企業標志、中英文簡稱標準字 視覺識別系統VIS或視覺識別系統管理手冊VIS 可選擇元素 輔助圖形 中英文全稱 廣告語 圖片 作業---VI手冊封面、封底、書脊 作業---VI手冊、封底、書脊 封底簡單明了,可以有廣告語 封底要有專業、班級、姓名、學號信息 書脊 環裝不考慮。

膠裝時要考慮顏色、圖形的適應性,書籍上可以有企業標志、標準字、vis等內容 作業---前言 介紹企業發展歷史 企業簡介 VI手冊使用規范 前言文字參考 企業識別系統(C System),是將企業的經營旨、企業文化與企業精神,通過標準化的行為語言和系統化的視覺符號傳達給社會大眾,具有突出企業個性,塑造企業形象的功能。 在日趨激烈的市場競爭中,要使企業生存并獲得發展,不斷強化自身形象是一個不容忽視的主題。XX集團企業識別系統的制定與導入體現了我們在這方面的努力,是XX集團精神與企業文化建設的重要組成部分,也是XX集團積極走向市場的重要步驟。 XX集團視覺識別系統的適用單位為:1.XX集團總部及所屬企業;2.集團內部從事辦公、生產、銷售及相應的管理部門。此外,在商業場所專賣柜臺、從事經營活動的運輸工具,以及進行各種企業宣傳時均適用XX集團標志。 XX集團企業視覺識別系統手冊自發布之日起,各相關單位及部門在使用過程中均應嚴格執行本手冊所規定的各項規范,不得隨意更改,以保證企業形象的規范性和統一性,避免產生誤導。其他單位及部門未經允許不得隨意使用。 今后,有關XX集團企業標識的使用,均應以本手冊為準,二0一四年十月以前印發的《XX有限公司企業視覺識別手冊》中凡是與本冊不同廢止使用。

本手冊應嚴格管理,不得向無關人員提供。 前言文字參考 VIS (視覺識別系統Visual system),是CIS系統的重要組成部分。是將企業理念,企業文化,運用整體的傳達系統,通過標準化,規范化的形式語言和系統化的視覺符號,傳達給社會大眾,具有突出企業個性,塑造企業形象的功能。視覺識別系統手冊,是以公司的經營理念及精神文化為指導而制定的標準徽標,標準字體,標準色彩的完善組合在企業管理與交往中的應用規范。視覺識別手冊通常分為基礎系統和應用系統。應用系統是個基本要素規范的延伸使用;包括辦公事務用品,公關事務用品,交通工具等。在各項實際應用中,除了考慮到功能性及經濟實用性。識別識別作為企業各部門準確實施的標準,全體員工有維護本企業整體形象的責任與義務,必須嚴格遵守。 請制作人員認真查閱手冊,選出合適內頁,參照手冊規范完成制作設計稿,再進行作業。請注意準確使用。 作業---目錄 應用系統頁眉 作業---辦公事務系統設計 必做:1名片、2信紙 3信封 4 資料袋(文件夾)5紙杯、6筆、7胸卡 選做: 名片(分高級主管、中級主管、員工) 會員卡、工作證、辦公桌標識牌 合同、文件題頭、請假單等、便簽 名片 文字說明:例:商務名片是**公司對外進行傳達形象的一個重要部分,是企業統一形象,增強員工榮譽的一個重要因素,在實物用品的實施過程中都均應以此系統為參照。
要求 正反兩面,標明文字的字體、字號、行距、標志的寬度。留白尺寸(具體數值)等。 注解:名片的尺寸規格,所用材料,制作工藝 名片 后期工藝,上光、打孔、擊凹凸、鏤空、模切、覆膜、燙金銀等。 材料:最常用250克啞粉紙、特種紙、銅版紙、PVC 印刷工藝:四色印刷,激光打印 名片尺寸:90×55MM、90×45MM、 會員卡85×54MM等 2信紙 3信封 4資料袋(文件夾) 6筆、7胸卡 文字說明:企業信紙是公司日常辦公,對外交流中頻繁使用的物品,是信息傳遞的重要載體,為體現**公司正確的視覺形象,避免公文信紙使用中的混亂,對此規范如下,在實際實際制作中不得更改。 要求 標明文字的字體、字號、行距、標志的寬度。留白尺寸等。 尺寸規格,所用材料,制作工藝 信紙:一般的信紙用80~100克的普通紙即可,如果是草稿用紙,可以使用最低廉的文件紙。規格一般為210*285MM、 184*260MM、 216*297MM、 210*197MM 設計要素包括品牌標志中英文名稱、標準色、聯系方式、裝飾紋樣等 小字字號盡量控制在12點 VI[視覺識別]應用系統設計 信封設計:小號220*110mm中號229*162mm 大號324*229mm,不通過郵局寄送的規格較為隨意,信封上的規定的貼郵票處、郵編位置等不可隨意改動,并按照郵寄規則確定信息位置 中國標準信封尺寸(GB/T1416-2003) 國內信封標準(單位MM)代號長寬備注B6號176125與現行3號信封一致DL號220110與現行5號信封一致ZL號230120與現行6號信封一致C5號229162與現行7號信封一致C4號324229與現行9號信封一致國際信封標準代號長寬備注C6號162114新增加國際規格B6號176125與現行3號信封一致DL號220110與現行5號信封一致ZL號230120與現行6號信封一致C5號229162與現行7號信封一致C4號324229與現行9號信封一致 中國標準信封尺寸(GB/T1416-2003) 信封一律采用橫式,信封的封舌應在信封正面的右邊或上邊,國際信封的封舌應在信封正面的上邊。
2、B6、DL、ZL號國內信封應選用不低于80g/m2的B等信封用紙I、Ⅱ型;C5、C4號國內信封應選用不低于100g/m2的B等信封用紙I、Ⅱ型;國際信封應選用不低于100g/m2的A等信封用紙I、Ⅱ型。 3、信封正面左上角的郵政編碼框格顏色為金紅色,色標為。 4、信封正面左上角距左邊90mm,距上邊26mm的范圍為機器閱讀掃描區,除紅框外,不得印任何圖案和文字。 5、信封正面離右邊55mm~160mm,離底邊20mm以下的區域為條碼打印區,應保持空白。 6、信封的任何地方不得印廣告。 7、信封上可印美術圖案,并位置在正面離上邊26mm以下的左邊區域,占用面積不得超過正面面積的18%。超出美術圖案區的區域應保持信封用紙原色。 VI[視覺識別]應用系統設計 尺寸23.5*31.5cm 書籍自己定,一般1.5cm到2cm VI[視覺識別]基礎系統設計 桌旗:分為橫豎兩種構圖。 橫向規格:一般為210*140mm豎向140*210mm 材料和印制:有紙面,綢面等。一般要求硬挺,精致程度較高。 桌旗多為對式擺放,設計時既可以讓兩面旗完全一樣,也可以考慮在色彩上進行正負調換。 * *
如何使用 JIT 技術實現高效的數據庫表達式求值


導讀本文將分享如何使用 JIT 技術高效優化數據庫表達式求值。
主要內容包括:
1.什么是表達式求值問題,如何對表達式求值
2.JIT 即時編譯技術的基本概念,為什么需要 JIT
3.Gandiva 表達式編譯器,如何使用 Gandiva 的 JIT 即時編譯技術加速計算
4.Q&A
分享嘉賓|吳立 上海炎凰數據科技有限公司 研發工程師
編輯整理|阿東同學
內容校對|李瑤
出品社區|DataFun
01
表達式求值
1.場景介紹
首先來介紹一下炎凰數據產品所關注并致力于解決的場景。

當前各大企業都面對著海量的數據,其中包括 MySQL 等關系型數據庫內的結構化數據、JSON 格式存儲的半結構化數據以及各類日志等非結構化數據。需要構建一款數據分析平臺,能接入各種異構數據,并高效地從其中挖掘信息,從而獲得有價值的洞察和啟示。這就是炎凰數據產品希望解決的場景。
在處理日志數據時,通常會創建一張表,定義字段等信息。然而,這種做法并非必須。當日志數據被輸入系統時,它將會直接進入一張數據表,無需經過任何 ETL 流程或數據清洗操作。之后可以通過 SQL 語句對這張數據表進行實時分析及檢索。但在這個分析的過程中,如何才能了解這個數據中包含哪些字段以及這些字段如何影響搜索結果呢?
舉一個簡單的例子,查詢 client 是 iPhone,且 IP 地址為 10.1.2.3。然而,我實際上并不清楚數據庫表中是否存在諸如 IP 這類字段,因為數據在進入到系統的時候我們并沒有為它創建對應的字段信息。
因此,查詢會經過兩層過濾,首先根據查詢中已知的信息,可以迅速利用索引獲取滿足過濾條件 client=‘iPhone’的數據。然而,另一個 IP 信息,并沒有相應的 IP 字段,需要在計算層過濾,才能得到所需要的結果。這就是本文要介紹的場景。
2.表達式求值問題
首先通過一個簡單的例子來解釋什么是表達式求值問題。假設一家航空公司,面臨一個需求,即向滿足特定條件的客戶發放積分。這個特定條件為航班目的地是深圳,且航班時間少于 120 分鐘。積分規則是航班票價乘以 1.8,再加上其距離除以 1000 的結果,追加客戶積分。

這樣一個查詢在數據庫中的執行流程會分為三個階段。首先是 table scan 階段,即系統會從硬盤讀取數據至內存之中。其中會考慮一些特定的優化措施,比如下推計算、過濾器等技術。為了便于理解,此處略過這些細節。其次是執行 where 條件中的篩選操作,其核心在于剔除不符合條件的數據,僅留下滿足過濾條件的部分。最后是 ,即我們常說的投影,上述過濾和投影階段都涉及到表達式的計算。
3.解釋執行的問題
我們重點來看一下中間的過濾階段。
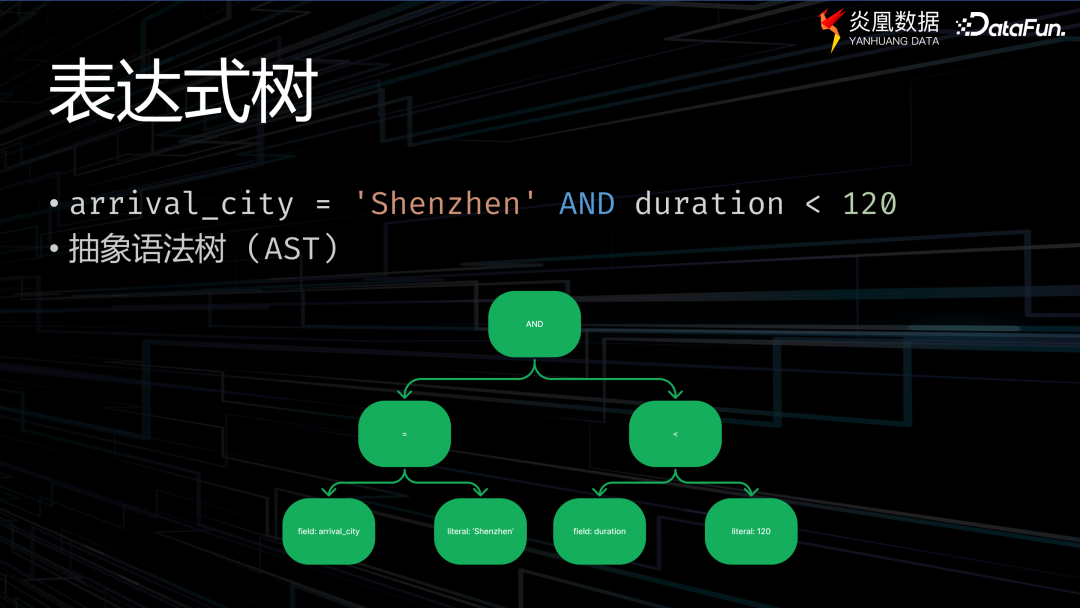
當語法分析器識別到這樣一種表達式時,通常情況下,會將其轉換成常用的抽象語法樹( Syntax Tree,簡稱 AST)。此過程極具簡約性,除葉節點外,其他節點代表的皆為運算符。例如,邏輯運算符或用于判斷的等號和不等號。而葉節點通常是一些字段(field)或者是數值型的值。
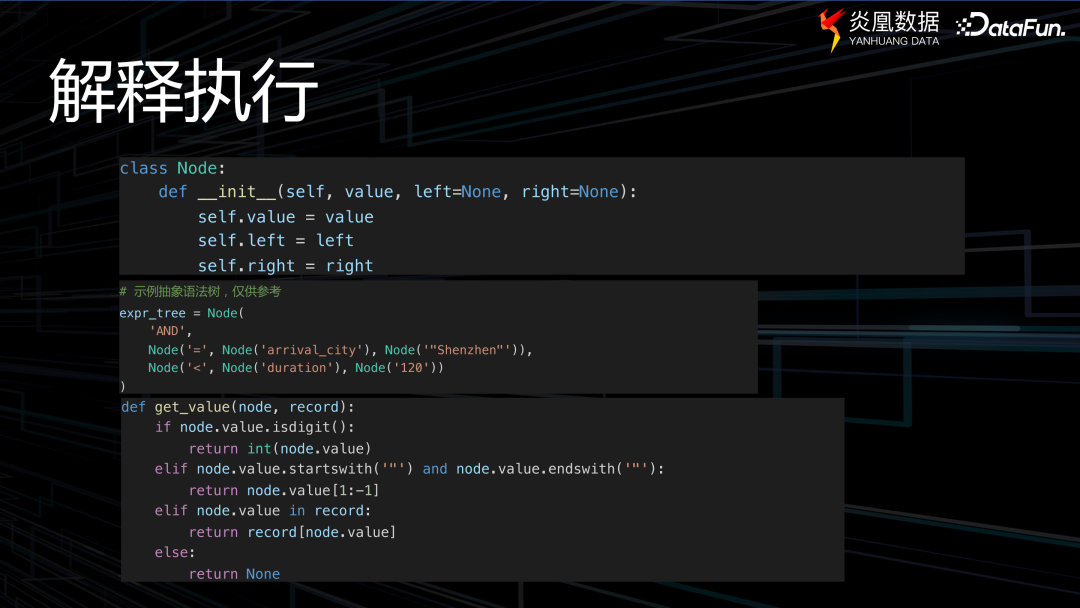
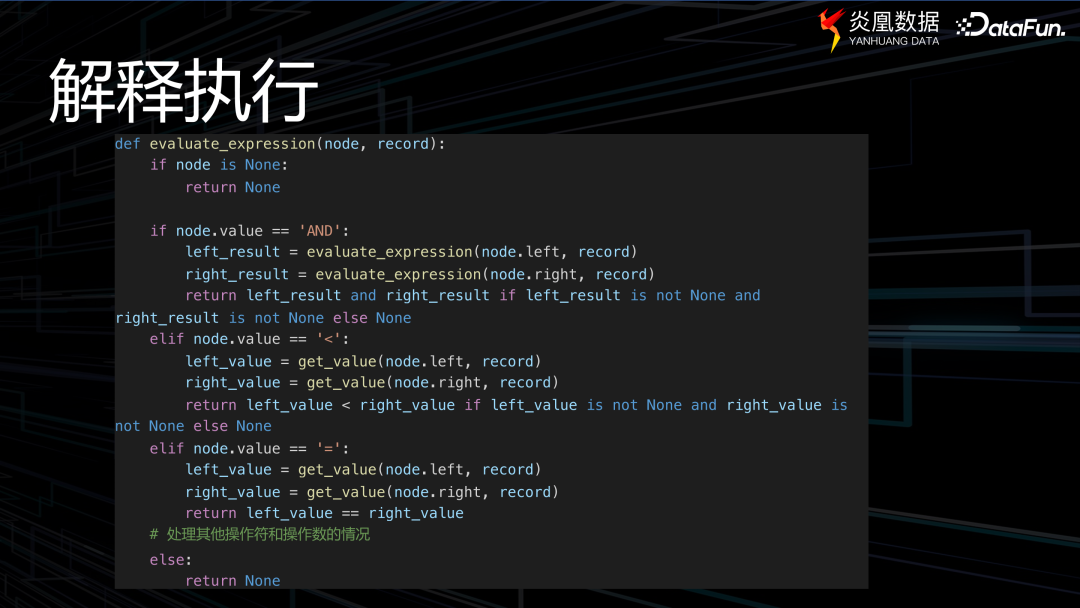
通常的過濾過程為定義一個 node 節點,前文提到的表達式可以通過此表達式樹來表達。還定義了一個函數以獲取該節點的具體值。解釋執行過程是一個深度遍歷的過程,首先判斷節點操作符,再依次遍歷左節點和右節點。
這種方法看起來簡單直觀,并且已成為大多數主流數據庫普遍采用的方式,但卻存在著一些問題。

首先,這種處理方式涉及到大量的虛函數調用,虛函數調用本身對于 CPU 而言屬于非確定性指令。也就是說,CPU 在執行此類指令時需要進行分支預測,若存在大量的虛函數調用,則會導致分支預測失敗,進而導致 CPU 的整個執行流水線頻繁中斷。
第二個問題是,計算過程中無法明確其類型,即在執行過程中,需頻繁地對其類型進行識別,導致計算過程中產生了大量的動態類型識別需求。
第三個問題是,我們所采用的深度優先搜索(DFS)執行方式,涉及到大量的遞歸函數調用,也在不斷地打斷其計算執行的流程。

這類解決方案能被眾多數據庫采用,是因為在早年這并不是主要問題,那時磁盤才是系統執行的瓶頸。
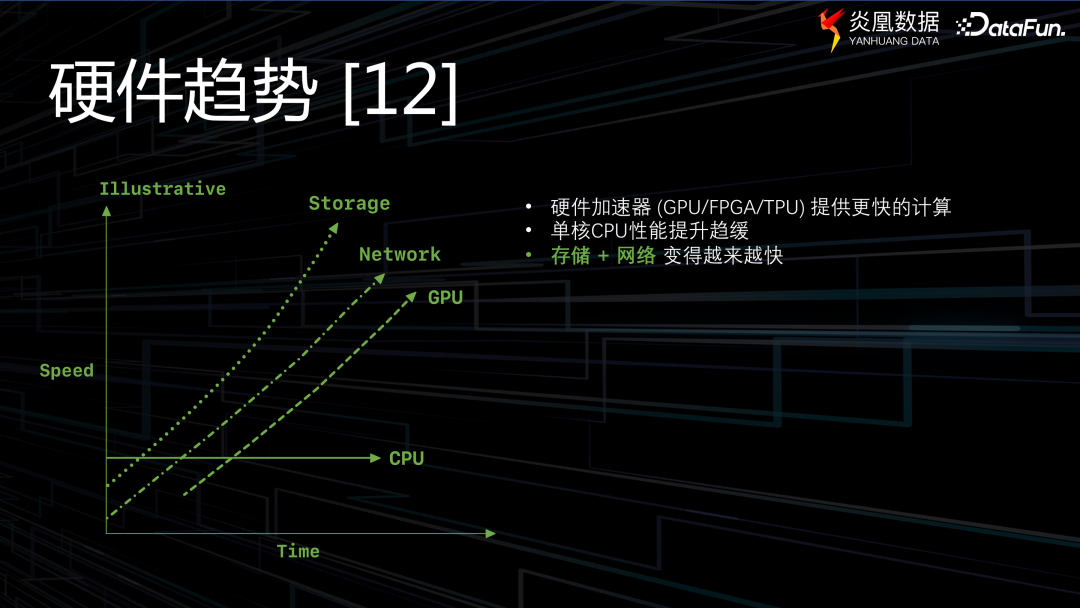
然而,隨著硬件設備的飛速發展,它們已不再是系統運作的瓶頸。相反,單核 CPU 計算單元的發展速度趨緩,與硬件發展并不匹配。當前的硬件系統,有更大的內存、更大的頁緩存。同時,越來越多的應用場景催生出新的處理方式——流處理。因此,現在瓶頸已經不在磁盤上了,而是在 CPU 上。解釋執行方式存在的缺陷也日益顯露。
4.三種數據庫表達式求值方式

前文中展示的一個簡單的表達式里面,僅包含了基本的 int 類型。然而,在實際應用中,還會遇到更加復雜的數據結構,例如嵌套類型、list 類型、union 類型以及混合類型等等。另外,也不僅是簡單的布爾操作和比較操作,還有許多用戶自定義的函數。

在這樣一種場景下,各數據庫開始探索新的解決方案,目前主流的有三種。
第一種仍然采取解釋執行的方式,但會在解釋執行的過程中加入一些優化措施,比如加大向量的優化力度。
第二種方式是,有些復雜的系統依賴虛擬機來對生成的這種字節碼進行優化,不過采用這一技術路線的產品相對較少。
最后一種就是本文要討論的,JIT 即時編譯(Just In Time )。對于一個抽象語法樹,先將其轉化為一個中間字節碼,然后在執行時再轉換為機器碼。

上圖中列出了一些主流產品所采用的方式。
02
JIT 即時編譯技術
JIT 即時編譯技術,又稱為動態翻譯,或運行時編譯。其核心在于將程序在運行過程中轉換為機器代碼,而非在執行前預先編譯為機器代碼。
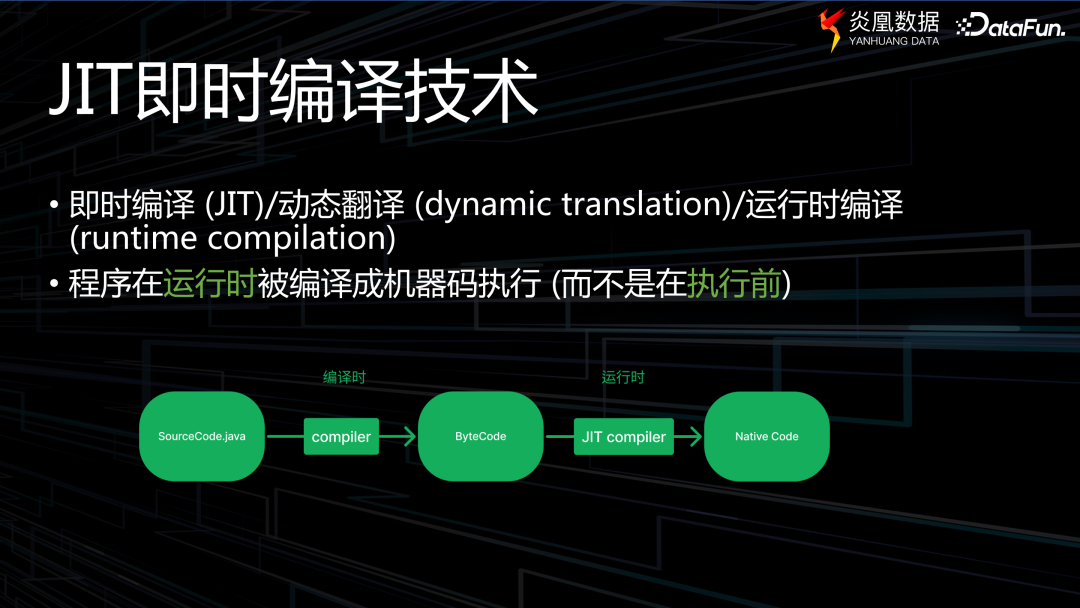
比方說,在編寫 C++ 程序時,使用 GCC 或 C++ 進行編譯,最終執行的實際上是能讓機器運行的字節碼。然而,JIT技術并非如此,它存在一個中間狀態,以 Java 的視角更易于理解。Java 文件會被編譯成()進行的 .class 文件,該文件即是一種中間狀態的編碼,然后由 JIT 的 將其翻譯成機器能夠認識的機器碼。
即時編譯技術亦存在其利弊兩面。其優勢在于,編譯代碼速度可以得到顯著提升,無需一次性將代碼轉換為機器可執行的格式;其次,這種技術提供了解釋的靈活性。然而,其劣勢在于運行時需要將代碼編譯為機器碼,這將會產生額外的開銷。因此,在應用 JIT 技術時,需針對不同情況進行測試和分析,評估該技術所帶來的收益是否大于其帶來的開銷。
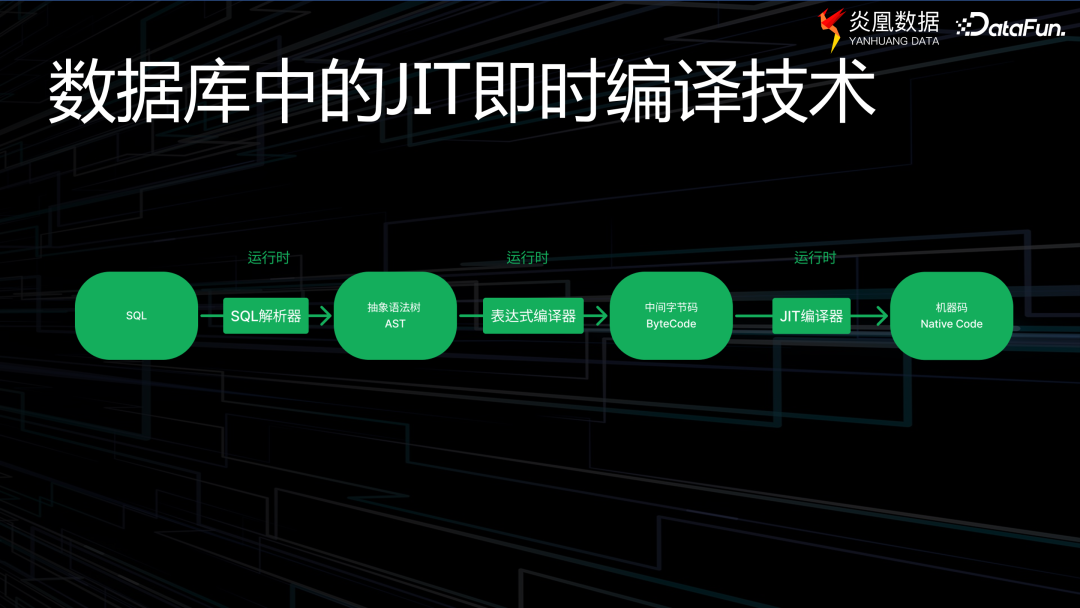
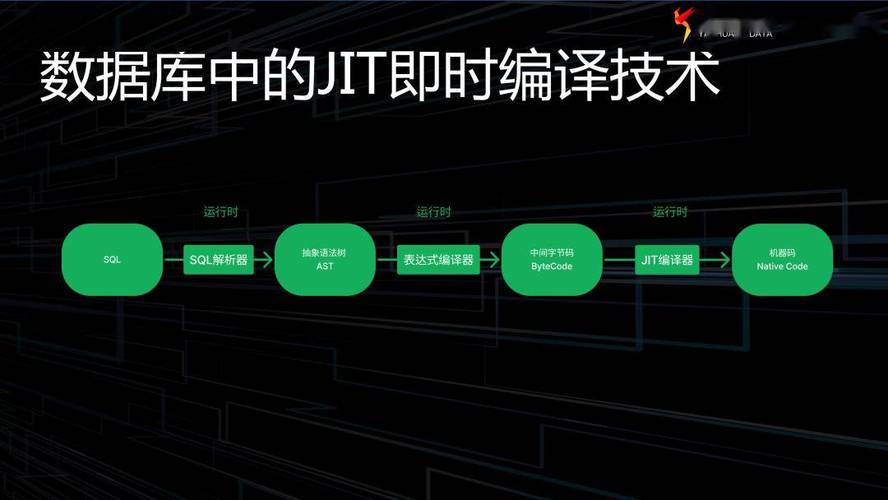
數據庫中的即時編譯(JIT)技術的運行機制,與上述過程大致相似。主要包括以下幾個階段。
首先,SQL 解析器將語句翻譯為抽象語法樹;接著,表達式編譯器將其轉化為中間字節碼;最后,JIT 編譯器將其進一步轉換為最終的機器碼。
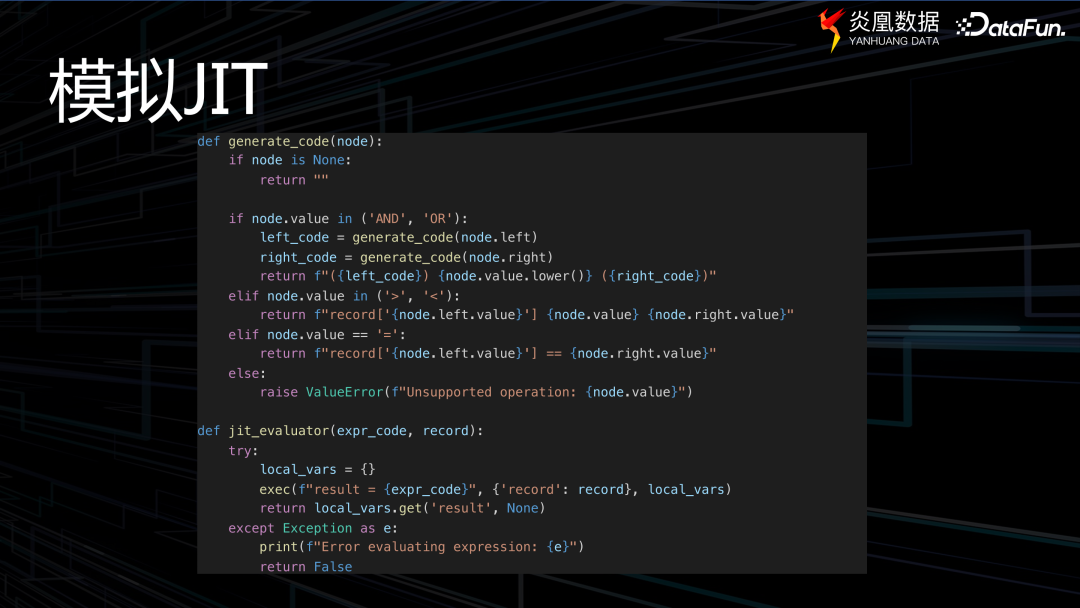
在此借助程序對 JIT 進行模擬,當然這與實際場景會存在一些差異。程序中有兩個函數:首先是名為 的函數,其任務是獲取一個抽象語法樹(AST),之后加載定義,在遍歷 code 時,將其轉化為一個可理解的 code 字符串。 函數直接執行 code 字符串,即生成一個可執行的代碼。
03
使用 Gandiva 的 JIT 即時編譯技術加速計算
接下來介紹如何運用 JIT 技術對數據庫表達式進行求值優化。我們采用了 Apache 的 Gandiva,它是建立在 LLVM 編譯器框架基礎上的一個表達式編譯器,其核心計算適用于 Arrow 列式內存格式,代碼編寫采用 C++,同時也提供了 Python 與 Java 的綁定接口。
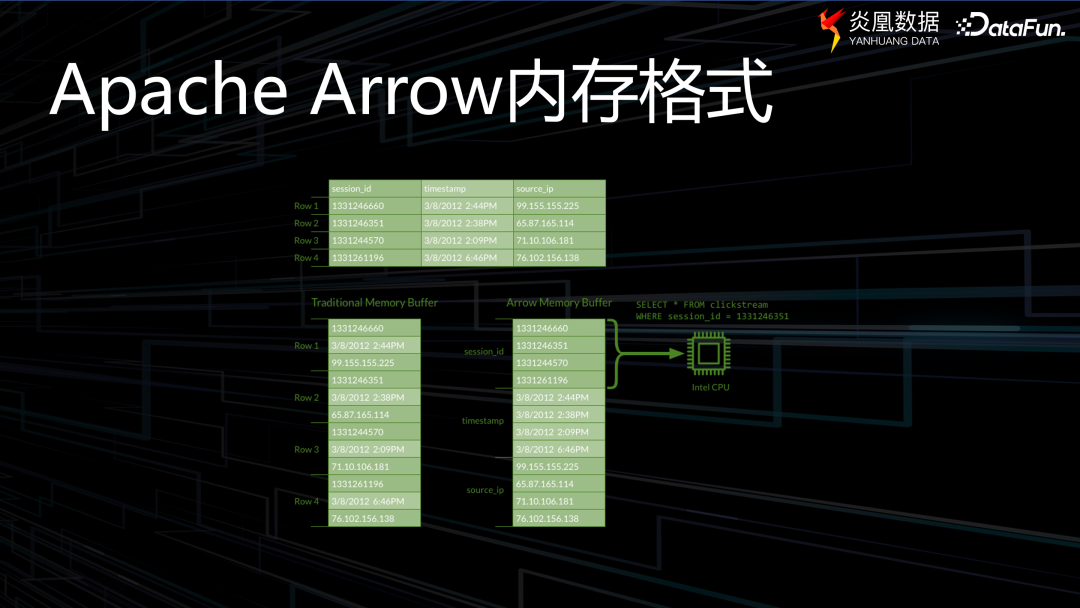
Apache Arrow 內存格式是一種列式存儲格式,對于關系型數據庫而言,行式存儲的形式往往無法在構建計算過程中實現高效的并行處理。而列式存儲,即數據在同一列內,其緩沖區內的數據將被集中存儲,因此在操作數據時,能極大提升操作效率。
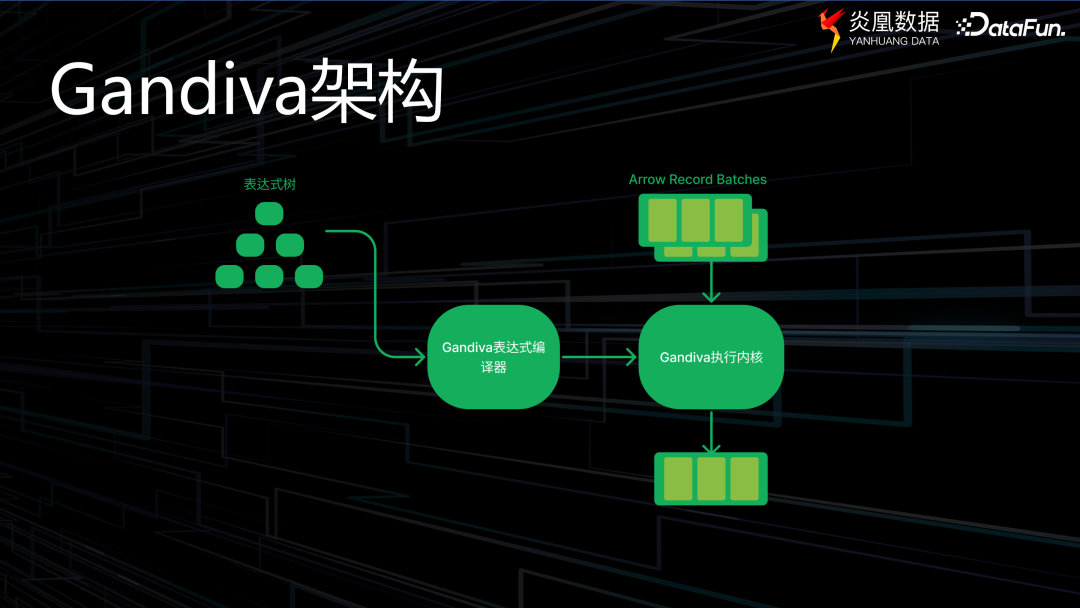
Gandiva 的整體執行流程如上圖所示。首先,有一個表達式樹;接著,Gandiva 的表達式編譯器將生成一種稱為 LLVM IR 的中間代碼,這是一種中間表達形式;該中間代碼將被傳遞給 Gandiva 的執行內核,整個過程處理的數據被稱為 Apache 的 Arrow Record Batches,最終得到預期的輸出結果。

早期的 Gandiva 比較簡陋,功能性略顯不足。近年來已得到了顯著的提升,但仍存在一些待改進之處。目前,在 Gandiva 的表達式庫中,已具備相當豐富的內容,除了基本的算術運算符以外,還擁有超過 100 個內建函數,以及布爾運算符。這些運算主要用于 project 和 filter 操作,即過濾和投影階段,因為只有在這兩個階段會涉及到大規模的表達式求值。
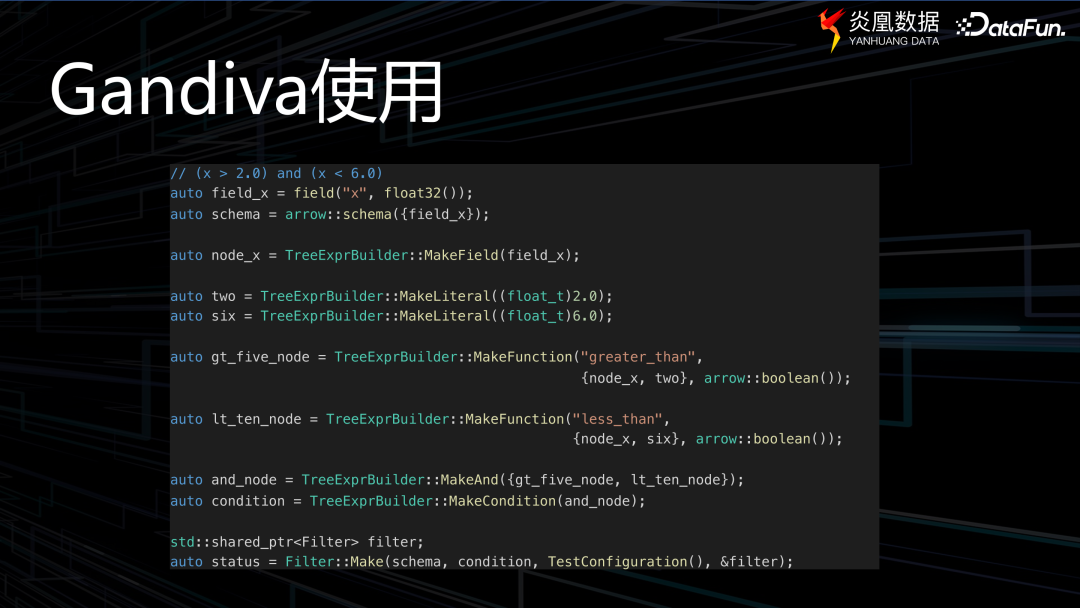
上圖中是一個簡單的 C++ 程序示例,使用了 Gandiva 接口,最上面可以看到表達式為:(x > 2.0) and (x< 6.0)。
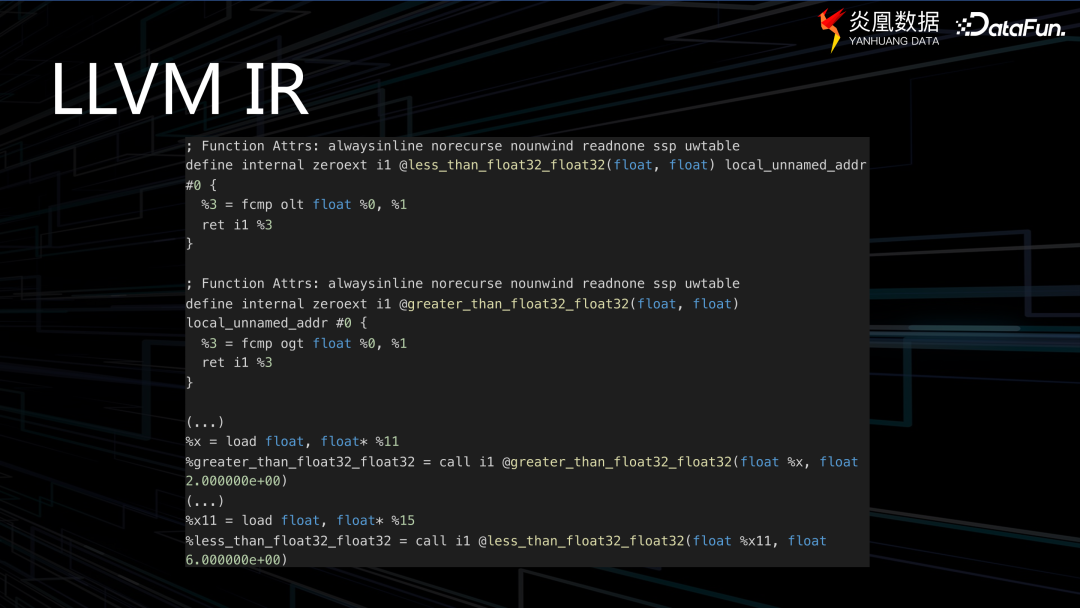
借助 Gandiva 的表達式,可以得到一個類似于 LLVM IR 表達式的結果。然而,在這個表達式及生成的代碼中可以看到,以 @ 開頭的 oat32 等函數形式,這些都是 Gandiva 內置的功能。因此,如果要形象地詮釋 JIT 代碼生成的原理,這里的內置算子與功能便如同齒輪組,當我們將表達式傳達給它們時,Gandiva 就會將這些齒輪組裝和運轉起來,使表達式得以順利執行。
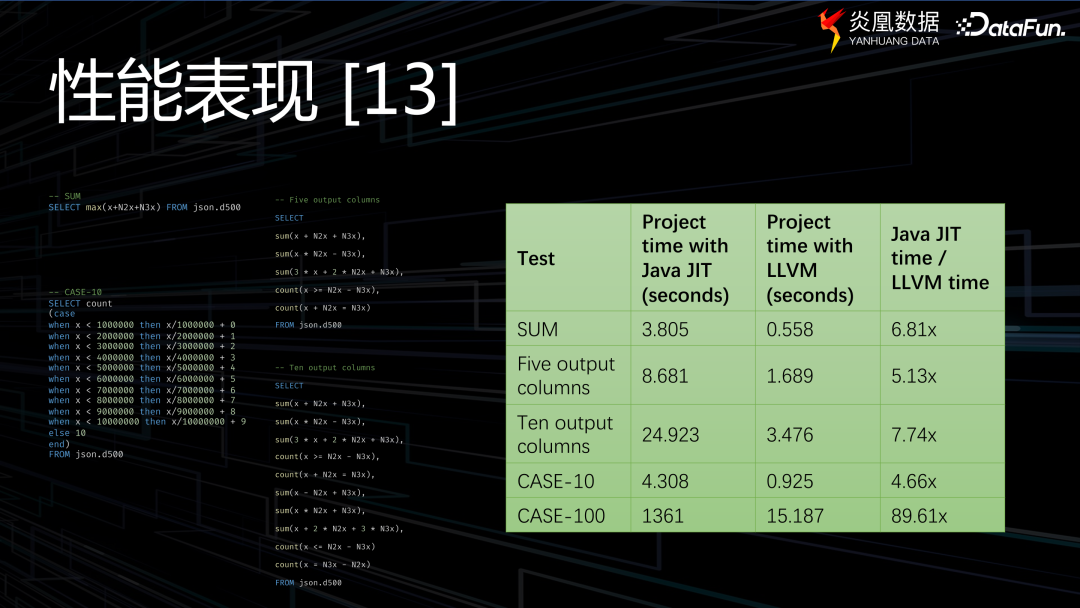
通過上圖數據可以看到,LLVM 技術的整體效率較之 Java JIT 可實現約 4 至 89 倍的提升。

我們對 Gandiva 進行了一些改進,增添了眾多額外功能,比如對時間戳支持,以及針對數組類型新增了超過 20 種有關函數,同時也增強了對于高階函數的支持,并改進了內存緩存的復用方式。
此外,還有一項極為關鍵的功能,就是前文中提到的 UDF 注冊機制,這也是我們向 Gandiva 項目貢獻的一項技術。
最后回顧一下本次分享的內容。文章第一部分探討了什么是數據庫表達式求值問題;第二部分,介紹了 JIT 即時編譯技術;最后,運用 Gandiva 的 JIT 技術來加速表達式求值。

炎凰數據產品旨在解決異構數據所面臨的復雜場景,歡迎大家關注、試用。
04
Q&A
Q1:Gandiva 生成的 LLVM 是標量值,有用到向量值,就是 SIMD(單指令多數據流)或者 AVX(高級向量擴展)等技術嗎?
A1:這是一個非常好的問題,有些人可能會對采用 Gandiva 協助生成 LLVMIR 的代碼存在一定擔憂,是否能達到預期的性能要求。因為在常規執行過程中,人們通常期望擁有準確、高效的向量化支持。針對這個問題,Gandiva 已經做出了妥善的處理,生成的 LLVM-IR 中間形式均具備向量化支持,以確保所需的功能得以保留。
這些技術使得處理器能夠同時處理多個數據,從而大大提高了程序的執行效率。在 Gandiva 中,LLVM IR(中間表示)被轉換為可執行代碼的序列,這些代碼可以由 SIMD 指令集執行。因此,Gandiva 生成的 LLVM IR 序列可以在支持 SIMD 指令集的處理器上高效運行。
Q2:Gandiva 一生成出來就是 LLVM 的形式?就是向量化的執行代碼?
A2:是的。它是經過優化的,實際執行的和我剛剛給大家展示的 Arrow code 是不一樣的,后者代表了初始的呈現方式,然而在實際執行過程中都是有向量化支持的。
Gandiva 生成的是 LLVM 的形式,并且可以生成向量化的執行代碼。Gandiva 是一個開源項目,旨在為 Apache Arrow 提供高效的數據處理功能。它使用 LLVM 作為后端,通過 LLVM 編譯器將源代碼編譯為高效的機器碼,并利用 SIMD 指令集實現向量化的執行代碼,從而提高數據處理性能。因此,Gandiva 生成的代碼可以在支持 SIMD 指令集的處理器上高效運行,實現高性能的數據處理。
Q3:Arrow 社區提供了 以及各種語言的高性能實現以供基于 Arrow 格式進行數據操作的向量化復用,跟 Gandiva 生成的 LLVM 的形式的向量化有什么區別和聯系?
A3:這也是一個很好的問題,Arrow 有自己的一套執行框架,叫做 ,它對向量化的支持是非常友好的。
Arrow 社區提供的 compute API 以及各種語言的高性能實現,是基于 Arrow 格式進行數據操作的開發人員可以直接復用的工具。這些工具可以幫助開發人員更高效地處理數據,并提高程序的執行效率。
而 Gandiva 生成的 LLVM 形式,是利用 LLVM 編譯器將源代碼編譯為高效的機器碼,并利用 SIMD 指令集實現向量化的執行代碼。這種生成方式可以使得 Gandiva 生成的代碼在支持 SIMD 指令集的處理器上高效運行,從而提高數據處理性能。
兩者的主要區別在于,Arrow 社區提供的工具主要是提供API和各種語言的高性能實現,而 Gandiva 生成的 LLVM 形式則是通過編譯源代碼來實現高效的數據處理。另外,Gandiva 生成的 LLVM 形式是向量化的執行代碼,可以充分利用處理器的 SIMD 指令集,而 Arrow 社區提供的工具則不一定是向量化的。
所以我們的整個執行引擎在經過了很多次迭代之后完全切到了一個新式的、對流式計算有一個更好的支持的引擎,這個引擎也是基于 Arrow compute 構建的。
Q4:是否有嘗試過這樣使用表達式求值的方法,因為它代表的是解釋執行加向量化的方式,每個算子會把 SIMD 指令解釋成向量化的執行代碼?
A4:是的。這部分我們也會用,我們是結合在一起用的,不是說單獨或者只使用這個,而不使用就是不是以數據執行。從數據從磁盤上讀取出來,就是經過過濾、投影再到給用戶呈現這個結果的過程中,有很多可以優化的地方。在最開始的時候一定要確保讀出來的那個數據集是最小的。然后在這個內存當中或者是在計算過程當中進行過濾時,我們可以通過 JIT 技術對它進行優化,優化是分為多個階段,就是看你當前所面臨的點哪個是最大的瓶頸。
這樣使用表達式求值的方法,是解釋執行加向量化的方式。每個算子會把 SIMD 指令解釋成向量化的執行代碼,從而充分利用處理器的并行處理能力,提高程序的執行效率。這種方法的優點是可以方便地擴展到支持向量化的指令集,如 AVX 或 SSE 等。此外,由于使用了向量化的執行代碼,還可以在多核處理器上實現真正的并行計算,進一步提高程序的性能。因此,表達式求值的方法在某些情況下可以提供比傳統解釋執行更高效的性能。
Q5:問一個表達式相關但與JIT無關的問題,是否有一種方法可以判斷某個表達式肯定為 true 或者肯定為 false。有沒有這樣的庫或者方法?
A5:此環節往往在項目初期便已完成,若是庫的問題,或許仍需根據具體情況著手實施。當前較為常用的解決方案是 Apache 旗下的 Calcite,它可用于實現 SQL 語句的語法解析。Apache Calcite 是一款開源 SQL 解析工具,能夠將各類 SQL 語句解析為抽象語法樹( Syntax Tree,AST),隨后通過對 AST 的操縱,可將 SQL 所蘊含的算法及關系映射到具體的代碼中。然而,我們并未采用此類方法,而是獨立開發了自己的解決方案。在物理執行計劃轉化為實際代碼之前,我們已經對其進行了全面優化,這個優化過程貫穿始終。
Q6:分享一下思路吧,我們在做的過程中產生困擾,比如 x>0 and x <0 這樣的篩選條件?
A6:對,這是一個比較典型的場景,這個可能得和具體的產品結合來看。就是(x>0 and x <0)這個明顯是一個 false 的場景。
當遇到 x>0 and x <0 這樣的篩選條件時,語法解析器會將其視為無效的語法。因為在一個邏輯表達式中,and 操作符連接的兩個條件必須都是真值,即 x>0 和 x <0 兩個條件必須同時滿足,這在邏輯上是矛盾的,因此無法解析這樣的表達式。
語法解析器在解析 SQL 語句時,會根據語言的語法規則將輸入的字符串轉換成抽象語法樹 AST( Syntax Tree)。在解析 AST 時,語法解析器會根據語法規則對 AST 進行驗證,確保 AST 符合語法的約束條件。
在處理 and 操作符時,語法解析器會檢查其左右兩個操作數的真值性。如果兩個操作數都是真值,則整個 and 表達式為真值;如果其中一個操作數為假值,則整個 and 表達式為假值。因此,當遇到 x>0 and x <0 這樣的表達式時,由于兩個條件在邏輯上是矛盾的,因此整個表達式為假值。
在處理篩選條件時,語法解析器會根據表達式的類型和上下文信息來解析。對于比較操作符(如 >、<、= 等)連接的兩個表達式,語法解析器會先解析每個表達式,確定其類型和值,然后根據比較操作符的類型進行比較運算。如果比較運算的結果是真值,則該條件可以被篩選出來;如果比較運算的結果是假值,則該條件不能被篩選出來。
總之,語法解析器在解析 SQL 語句時,會根據語言的語法規則對輸入的字符串進行解析和驗證,確保生成的 AST 符合語法的約束條件。對于無效的語法,語法解析器會報錯并提示用戶進行修正。
對于這種情況可以采用的一個辦法是假設法,即假設 x > 0 為真,在這個假設的基礎上去判斷 x < 0 是否為真,如果不成立那么兩者 and 的結果一定為假。