

說到 Excel 函數,就不得不提 VLOOKUP,它可能是各位“表”哥、“表“姐工作中最熟悉的一個公式了。我第一次接觸 vlookup 的時候簡直是大呼神奇,像是打開了新世界的大門。然而,一時 vlookup 一時爽,一直 vlookup 可不爽。
運行一百萬行 vlookup 是種怎樣的體驗?
卡出翔
說 VLOOKUP 之前,請允許我先談談 Excel的卡。
Excel 的卡,在我看來,其實分為三種。
第一種卡,是有條不紊的卡:
看起來有個百分比,很有規劃的亞子,實際上時快時慢,根本不能反映真實的進度;這個配方其實有點熟悉的味道,記得小時候安裝游戲,進度條是一格一格的藍色或者綠色方塊,剛開始速度很快,后來差一點就完成的時候也是會卡超久
網上找的圖,大概這個樣子
當時以為進度條只是騙小孩子的把戲,后來工作了,發現公司導數據的進度條,有時甚至會從 20% 跳到 0%,終于明白,進度條不僅騙小孩,大人也騙。
第二種卡,是那種無能為力的卡
未響應
如果您繼續等待,程序可能會相應哦!
如果您繼續等待,女神可能會回你哦!

第三種卡,是戛然而止的卡
類似這樣的,也有一個紅色的警告,但是字的行數更多,而且是出現在你運行程序的 過程中,沒有一點點的防備,就這樣出現。
只要按一下確定,Excel進程就直接關閉了(也就是說你打開的所有表格都直接關閉),沒有重試,沒有取消,沒有跳過。
"爺不干了!"
你可以按一下【確定】,表示收到,也可以任性地不按確定,“我偏要按右上角的關閉!我偏不收到!”
反正結局也沒什么不一樣。
所以按下 ctrl+s 是你在進行大規模運算,并僥幸沒有崩潰跳出的情況下,該做的第一件事,對 Excel 一定要有敬畏之心,珍惜它的勞動成果,及時保存。
另外還有一點,謹慎刪除工作表(sheet)。
我們都知道人生沒有后悔藥,但程序都有撤回鍵(Ctrl+Z ),然而凡事都有例外。
刪除工作表這種不尊重 Excel 的行為,是要受到懲罰的:刪除工作表是不可以撤回的。
如果你不想見到它,請隱藏;如果它太大了,請備份(另存為);務必三思而后刪。
這只是個小細節,不要問我怎么發現的。
好了,廢話不多說了。我們進入正題,對了,我們要講什么來著?
沒錯,挑戰百萬 VLOOKUP!
首先,要進行百萬條 VLOOKUP運算,我們先得準備一下數據吧。
直接上代碼:
1import?pandas?as?pd
2import?random?
3
4def?GB2312():
5????words?=?[]
6????for?i?in?range(3):
7????????head?=?random.randint(0xb0,?0xf7)
8????????body?=?random.randint(0xa1,?0xf9)???#?在head區號為55的那一塊最后5個漢字是亂碼,為了方便縮減下范圍
9????????val?=?f'{head:x}{body:x}'
10????????word?=?bytes.fromhex(val).decode('gb2312')
11????????words.append(word)
12????words?=?''.join(words)
13????return?words
14
15l?=?[GB2312()?for?i?in?range(1000000)]
16
17#打亂順序
18l_shuffle?=l.copy()
19
20random.shuffle(l_shuffle)
21
22values?=?[random.randint(1,2000)?for?i?in?range(1000000)]
23
24df?=?pd.DataFrame({'A':l,'B':values,'C':l_shuffle})
25df.to_excel('Million?vlookup?data.xlsx',index=False)
啥?不懂代碼?沒關系!
生成的文件我給你們準備好了,公眾號對話框回復【vlookup】獲取相關課件。
出來的數據長這樣:
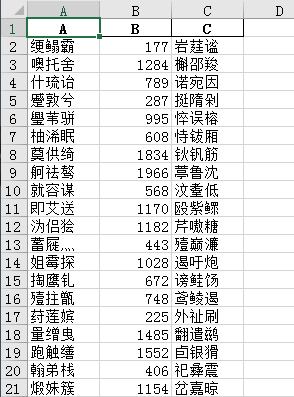
A列是條件(隨機生成的漢字組合,你就當他是個名字吧),B列是值(隨機生成的),C列是打亂順序的A列
我們要做的是在 D 列匹配,C 列對應的值。
當然了,一般情況下, VLOOKUP 都不會放在同一個工作表里(sheet),但是為了演示方便,我就姑且把它們放到一起。
VLOOKUP 本身并不難,只是這數據有點多,百萬行的。
公式計算由電腦的CPU負責,所以我們要客觀地反映“有多卡”,需要監控 CPU 的利用率。
于是我首先想到用系統自帶的資源管理器,發現不太好用,還是用 Python 吧,畢竟除了生孩子 Python 啥都能干。
網上挑挑揀揀,擼出一小段代碼,用來監控 CPU 的使用率
資源管理器上的CPU使用率
1import?psutil
2import?time
3
4while?True:
5
6????now_time?=?time.strftime('%H:%M:%S',?time.localtime(time.time()))
7????cpu?=?(str(psutil.cpu_percent(1)))?+?'%'
8????free?=?str(round(psutil.virtual_memory().free?/?(1024.0?*?1024.0?*?1024.0),?2))
9????total?=?str(round(psutil.virtual_memory().total?/?(1024.0?*?1024.0?*?1024.0),?2))
10????memory?=?round(int(psutil.virtual_memory().total?-?psutil.virtual_memory().free)?/?float(psutil.virtual_memory().total)*100,2)
11????print(f"{now_time}\t{cpu}\t{memory}%")
12????time.sleep(1)?
接著就是見證奇跡的時候了,先運行 py 代碼,讓程序跑起來以監控 CPU,然后打開百萬行數據的 Excel,在 D2 寫好公式:
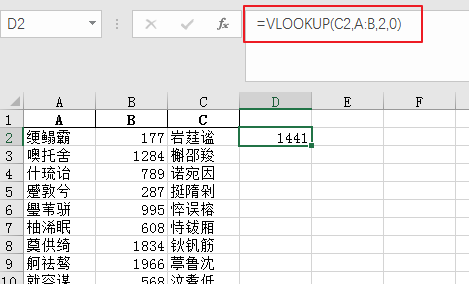
雙擊 D2 單元格的右下角,自動向下填充
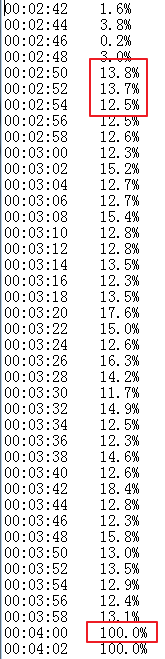
左邊是時間,右邊是CPU總利用率
可以看到 CPU 利用率先是快速達到 13%,然后維持了一分鐘的 13%-15%,接著猛地升到了100%

維持了好久,等到我洗完澡后發現還在運行,于是我就安心睡覺去了,想著 CPU 很難燒壞的。
不過我在床上躺著的時候想起來,這塊 E3-1230(四核八線程) 就是我在燒了上一個 CPU 后,親手涂硅脂安裝上的。
第二天早上,醒來之后我第一時間跑到電腦桌,快速搖晃鼠標,喚醒屏幕,查看運行情況
想必讀到這里(您真有耐心!),你現在的心情也和我那時一樣,迫切地想知道運行完了沒有,翻看記錄:

完成了!
7 小時!
有時候,一轉身就是一輩子;
有時候,未響應便是7小時。
我已經不敢再這么測試一次了,怕 CPU 和 Excel 一樣霸道總裁,突然就罷工了。
那么要怎么優化呢?
首先,在正式優化前,我又重新寫了一段代碼,單獨檢測 Excel 進程的 CPU 利用率情況,以排除其它程序的干擾
1import?psutil
2import?time
3import?os
4
5start?=?time.time()
6while?True:
7????for?proc?in?psutil.process_iter():
8????????if?proc.name()?==?'EXCEL.EXE':
9????????????percent?=?round(proc.cpu_percent()/psutil.cpu_count(),2)
10????????????spent?=?round(time.time()-start,0)
11????????????print(f"{spent}s\t{percent}%")
12????????????time.sleep(1)
接著,我們嘗試著做一些優化
I5-8400 vs E3-1230
剛好有條件,我就換了臺電腦運行,這次 CPU 是 I5-8400(六核六線程),應該會強一些。
一百萬數據直接上!沒在怕的!
這次運行,可能由于電腦硬件增強了,并沒有馬上卡死,我得以觀察整個運行過程,還可以順便截圖復盤。
首先,進度條出現,而且按 ESC 還可以取消,要感動哭了
但是,我們通過上文都應該懂得了一個道理:進度條只是個掩飾
果不其然,進度條一分多鐘后跑完,運算貌似已經完成
看一下 CPU 使用情況:
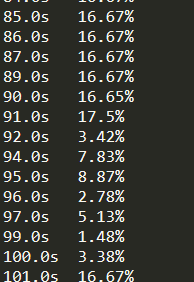
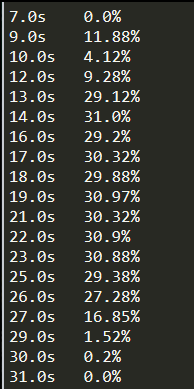
雖然在 91 秒的時候降了下去,但是在 101秒的時候又升上去了,說明還在運行中,并且占用率維持在 16.6%上下,也就是 1/6,我估計是有一個核心在全力奮戰。
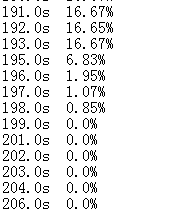
過了不久,我驚奇地發現,程序運行完了!查看運行情況,發現在 199 秒的時候,CPU 已經運算完畢,下落到 0% 了。
7小時 vs 200 秒!
我已經很久沒折騰過硬件了,也沒仔細查看兩個 CPU 參數上的差別,但百萬 vlookup 的測試結果已經能很直觀地體現兩者的差別了。

不過,我們這篇文章主要探討的還是工具和技巧,而不是硬件(我也不懂),所以接著還是要從技術手段上著手。
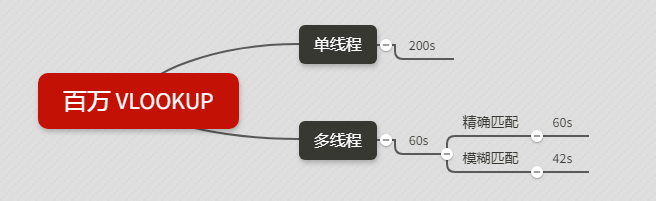
單線程 vs 多線程
通過查看剛剛的運行日志,我發現運算百萬 VLOOKUP 的時候,峰值一直在 1/6 左右,也就是一個核心,那么如何才能物盡其用,發揮出其它核心的性能呢?
答案就是開啟多線程計算!
Excel 中的多線程運算:
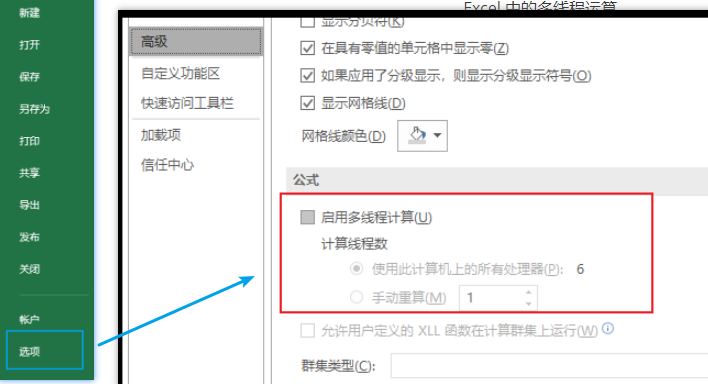
開啟了多線程計算后,我們再次進行測試
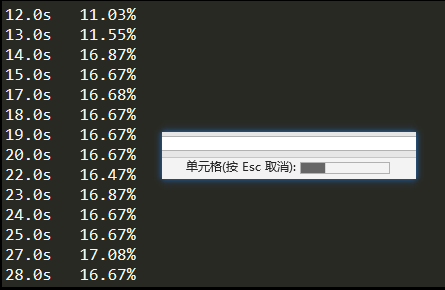
一開始還是老樣子,煞有介事的進度條,這時候峰值還是 16% 上下
進度條消失后,看到 6 個線程的字樣,百分比進展飛快,趁著完成前趕緊截個圖,沒過幾秒就運行成功了
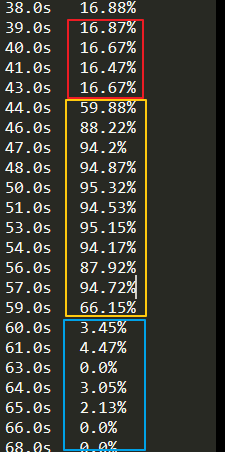
多線程總用時約 60 秒,比單線程自然要強不少
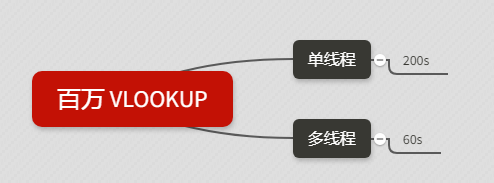
精準匹配 vs 模糊匹配
接下來,我們嘗試使用 vlookup 的模糊匹配
我們平時用 vlookup 的時候,最后一個參數都會設為0 (False),表示精確匹配。如果第四項不填或者填1( True ),會進行模糊匹配:
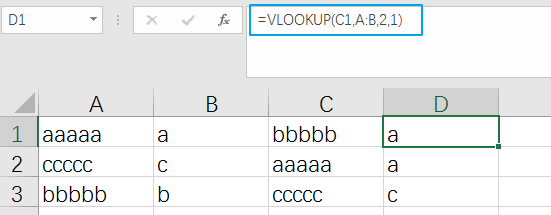
模糊匹配
顯然,如圖所示,模糊匹配出來的結果是不準的,畢竟它叫模糊匹配嘛,那這個模糊匹配設計出來有什么卵用呢?
它快啊!
讀到這里,你可能已經一臉懵逼了,結果都算不準,算得快有什么用?
您別著急,聽我慢慢道來。其實模糊匹配是可以匹配到正確結果的,前提是要對數據源進行排序!而且必須是升序!

先排序再模糊匹配
瞧,將A列以升序排列后,再用模糊匹配,結果就沒有問題了。我發誓絕對沒有偷偷用精準匹配,不信你試試看。
所以,對百萬 vlookup 而言,先排序,再模糊匹配,會不會對運算效率有提升呢?
我直接上結果!

在第一個占用率陡升的兩秒里,我在 Excel 里操作了升序排序;接著從21秒開始,進行 vlookup 的模糊匹配
那么你猜猜看,從第 8 秒到第 19 秒,程序在干嘛呢?為什么沒有開始運算呢?
因為,這時候,它在等我寫公式!

直到第60s,猛升了一秒后,迅速降下來,標志著運算完成。總耗時(減去我寫公式的時間)約 42 秒,比多線程略快一些。
多條件匹配
用 Excel 的絕大部分人都用過 vlookup 函數,但是我保證用 vlookup 函數的大部分人都沒用過 vlookup 的多條件查找!
我也是在寫這篇推文的時候學到的,所以也和大家分享一下。
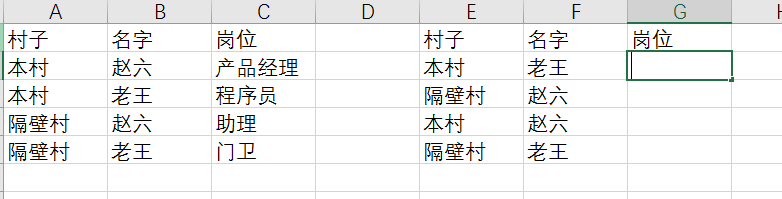
如果我們公司有兩個老王和趙六,怎么才能通過,村子和名字,這兩個條件來判斷他的崗位呢?
方法一,也是我之前的方法:
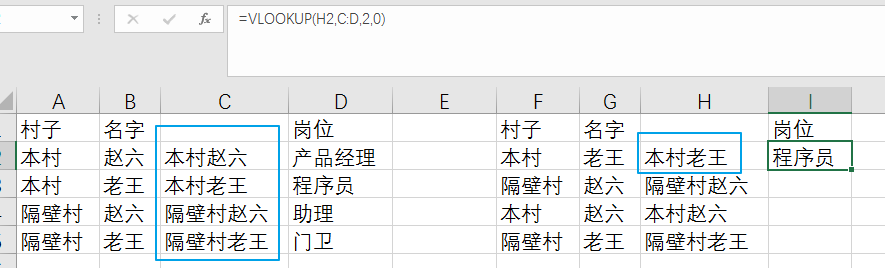
將兩個條件連接起來組成新的輔助列
輔助列大法好!
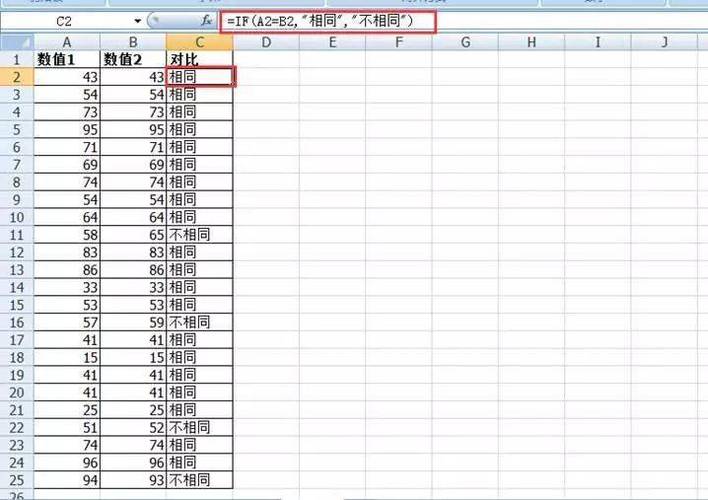
聰明如你一定不用我多解釋
方法二:
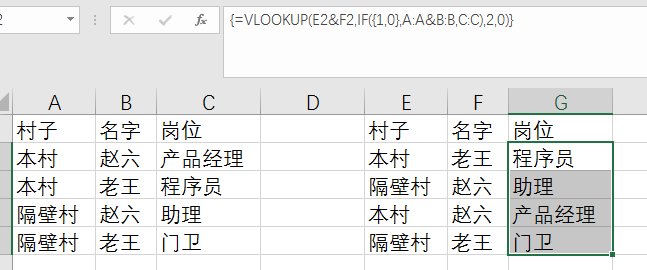
數組大法
(具體數組公式的用法我就不多解釋了,請同學自行學習)
需要提醒的一點是,最外面的一對大括號不是用手打上去的,而是輸完公式后,同時按下 Ctrl + Shift + Enter,以表示這是個數組公式,如果直接像正常公式一樣按 Enter會顯示 #NA
介紹多條件查詢并不是想跟你們單純分享數組公式,而是因為我有個大膽的想法!
你想到了嗎?
千萬 VLOOKUP 數組運算!
還是要先準備數據,這次就不搞花里胡哨的漢字了,直接 pandas 搞定(文末有資源提供)
1import?pandas?as?pd
2import?numpy?as?np
3
4df?=?pd.DataFrame(np.random.randn(1000000,6),columns=list(range(1,7)))
5print(df)
6
7shuffle?=?df.iloc[:,:5].sample(frac=1).reset_index(drop=True)
8print(shuffle)
9
10mix?=?pd.concat([df,shuffle],axis=1)
11columns?=?list(range(1,12))
12
13columns[5]?=?'value'
14mix.columns=columns
15
16
17mix.to_excel('10Xmillion.xlsx',index=False)
以達到這種效果
生成之后,文件這么大
打開文件的時候,CPU 占用率是這樣
經過十幾秒的努力,終于一睹真容
我們的目的,是要通過 7-11 列的數據去匹配 1-5 列的條件,得到F列的值
總共是 個單元格,愛我你怕了嗎?
說干就干,數組走起
被斷然拒絕(公式寫錯了請忽視)
這一次,Excel拒絕的理由很得當,我原諒你了。畢竟是在崩潰前告訴了我 “我不行。”,而不是運行到一半的時候,大喊一聲 “我真的不行了!”,然后直接閃退出來。
后面我又降低難度,嘗試了10 萬單元格的數組運算,運行狀態是這樣的:
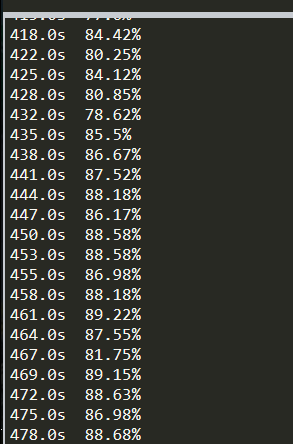
遲遲沒有結果,才10 萬的數據,我已經疲于等待,于是我果斷地選擇關掉 Python,萬一它再計算個7小時我可等不了。
我以為關掉 Python 后,眼不見心不煩,還能把 Excel 掛后臺處理,逛逛 b 站,然而當我停止運行 Python 的一瞬間,電腦立即卡死,鼠標都動不了了。
我好不容易打開了資源管理器:
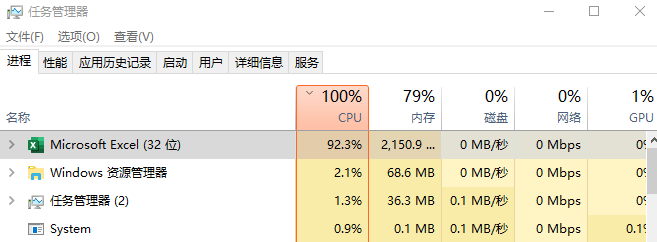
發現占用率已經飆升到 90%,似乎是把我原本運行 Python 的資源都搶了過去。
這時候我已經放棄運算了,想著馬上結束掉這罪惡的進程,結果鼠標這次真的完全動不了了。
最后我不得不長按電源鍵,結束我這飽經挫折的一天。
最后總結:百萬行的 vlookup,如果你電腦 CPU 還可以的話,通過開啟多線程加上模糊匹配的操作,運算時間還是可以忍受的。但對于數組公式來說,上萬個單元格的計算估計就不太樂觀了。
這一期,主要是講了一下 Excel 在處理百萬 vlookup 時候的一些技巧,但是君子善假于物,光靠 Excel 是不能成為一個優秀的數據分析師的,所以下一期,我將會帶著大家測評一些熱門選手,來處理百萬 vlookup,千萬 vlookup, 多條件查找!敬請期待!
幾個月沒更新了,說一下近況:
沒更新公眾號的這幾個月以來,我也沒有悶聲發大財、閉關修煉,只是工作開始忙起來了,回到家基本只想玩玩游戲休閑一下。爬蟲方面,一直也沒有好好深入,之前在爬蟲、后端和數據分析的職業選擇上徘徊了無數次,一會兒覺得這個好,過兩天又覺得那個好,事實就是無論哪一個都不能勝任,頗有一點小時候糾結清華和北大去哪間大學比較好的感覺。
不過現在至少,我已經做好選擇了,決定在數據分析的方向上走下去。主要有兩個原因,一個是數據分析的可操作性比較大,更有施展的空間,發展面也比較廣,而且也可以利用自己的技術特長輔助業務;做個程序員的話,以我微末的道行估計只能做個工具人了吧;第二個是爬蟲多多少少還是有一定風險的,我慫。
所以公眾號以后的方向肯定是數據分析,而且我打算一周至少更新一篇文章,把公眾號撿起來,培養自己寫文章的習慣,來逼迫自己走出局限,接觸更多新事物。為了完成這個目標,我打算建一個讀者群,規定自己每周發一篇文章,如果沒能完成,就在群里發個 100 塊紅包懲罰一下自己,試行 2 個月。(萬一最后統計是 -800,估計就要因為交不起網費無限期斷更了。)
想要進群的讀者加我好友扣個1,湊齊十個人就正式把群運營起來了!最后,友情提示:發送【vlookup】到公眾號對話框獲取本文課件。
