

什么是爬蟲?
實踐來源于理論,做爬蟲前肯定要先了解相關(guān)的規(guī)則和原理,要知道互聯(lián)網(wǎng)可不是法外之地,你一頓爬蟲騷操作搞不好哪天就…
首先,咱先看下爬蟲的定義:網(wǎng)絡(luò)爬蟲(又稱為網(wǎng)頁蜘蛛,網(wǎng)絡(luò)機器人,在FOAF社區(qū)中間,更經(jīng)常的稱為網(wǎng)頁追逐者),是一種按照一定的規(guī)則,自動地抓取萬維網(wǎng)信息的程序或者腳本。一句話概括就是網(wǎng)上信息搬運工。
我們再來看下爬蟲應(yīng)該遵循的規(guī)則:協(xié)議是一種存放于網(wǎng)站根目錄下的ASCII編碼的文本文件,它通常告訴網(wǎng)絡(luò)搜索引擎的漫游器(又稱網(wǎng)絡(luò)蜘蛛),此網(wǎng)站中的哪些內(nèi)容是不應(yīng)被搜索引擎的漫游器獲取的,哪些是可以被漫游器獲取的。一句話概括就是告訴你哪些東西能爬哪些不能爬。
了解了定義和規(guī)則,最后就是熟悉爬蟲的基本原理了,很簡單,作為一名靈魂畫手,我畫個示意圖給你看下就明白了。
(⊙o⊙)…尷尬,鼠標(biāo)寫字咋這么丑,都不好意思說自己學(xué)過書法,好一個臉字打得呱呱響。
項目背景
理論部分差不多講完了,有些小朋友估計要嫌我啰嗦了,那就不廢話,直接講實操部分。本次爬蟲小項目是應(yīng)朋友需求,爬取中國木材價格指數(shù)網(wǎng)中的紅木價格數(shù)據(jù),方便撰寫紅木研究報告。網(wǎng)站長這樣:
所需字段已用紅框標(biāo)記,數(shù)據(jù)量粗略看了下,1751頁共5萬多條記錄,如果你妄想復(fù)制粘貼的話,都不知道粘到猴年馬月了。而只要運行幾分鐘就能把所有數(shù)據(jù)保存到你的excel里網(wǎng)絡(luò)爬蟲軟件是做什么的,是不是很舒服?
項目實戰(zhàn)
工具:
版本: 3.7
瀏覽器: (推薦)
對于第一次寫爬蟲的朋友可能覺得很麻煩,咱不慌,由淺入深,先爬一頁數(shù)據(jù)試試嘛。
一.爬取一頁
首先,我們需要簡單分析下網(wǎng)頁結(jié)構(gòu),鼠標(biāo)右鍵點擊檢查,然后點擊,刷新網(wǎng)頁,繼續(xù)點擊Name列表中的第一個。我們發(fā)現(xiàn)此網(wǎng)站的請求方式為GET,請求頭反映用戶電腦系統(tǒng)、瀏覽器版本等信息。
接著,把爬蟲所需的庫都pip安裝一下并導(dǎo)入,所有庫的功能都有注釋。
import csv #用于把爬取的數(shù)據(jù)存儲為csv格式,可以excel直接打開的
import time #用于對請求加延時,爬取速度太快容易被反爬
from time import sleep #同上
import random #用于對延時設(shè)置隨機數(shù),盡量模擬人的行為
import requests #用于向網(wǎng)站發(fā)送請求
from lxml import etree #lxml為第三方網(wǎng)頁解析庫,強大且速度快
構(gòu)造請求url,添加頭部信息即復(fù)制前文標(biāo)記的User-Agent,通過.get方法向服務(wù)器發(fā)送請求,返回html文本。添加目的在于告訴服務(wù)器,你是真實的人在訪問其網(wǎng)站。如果你不添加直接訪服務(wù)器,會在對方服務(wù)器顯示在訪問,那么,你很可能會被反爬,常見的反爬就是封你ip。
url = 'http://yz.yuzhuprice.com:8003/findPriceByName.jspx?page.curPage=1&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB'
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36",
}
response = requests.get(url, headers=headers, timeout=10)
html = response.text
print(html)
我們運行下以上代碼,看下效果:
看到這個,第一次接觸爬蟲的朋友可能會有點懵。

其實這就是網(wǎng)頁源代碼,咱們右鍵打開下源代碼看一哈。
長這樣:
而我們需要提取的數(shù)據(jù),就潛藏在這網(wǎng)頁源代碼中,我們要用lxml庫中的etree方法解析下網(wǎng)頁。
parse = etree.HTML(html) #解析網(wǎng)頁
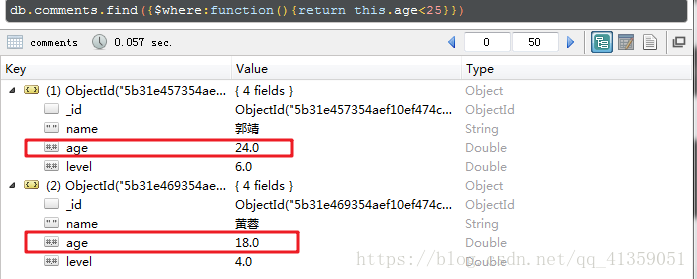
解析完之后,就可以開開心心的提取我們所需要的數(shù)據(jù)了。方法很多,比如xpath、、 soup,還有最難的re(正則表達式)。本文爬取的數(shù)據(jù)結(jié)構(gòu)較為簡單,就直接用xpath玩一下吧。
我們發(fā)現(xiàn),每一行數(shù)據(jù)對應(yīng)源碼里的一個id=的tr網(wǎng)絡(luò)爬蟲軟件是做什么的,那就先把這些tr都提取下來。
all_tr = parse.xpath('//*[@id="173200"]')
有些小伙伴不會寫xpath。
那就找個簡單辦法,直接copy所需的xpath。
所有tr都提取下來了,接下來就得依次從tr里面提取具體字段了。比如提取商品名稱字段,點開第一個tr,選中商品,copy其xpath。其他字段同理。
以下要注意幾點,tr={key1 : , key2 : }是的字典數(shù)據(jù)類型(你也可以根據(jù)自己興趣或需要存為列表或元組類型)。‘’.join是指把獲取到的列表轉(zhuǎn)為字符串。./是指繼承前面的//*[@id=“”],strip()表示對提取的數(shù)據(jù)進行簡單的格式清洗。
for tr in all_tr:
tr = {

'name': ''.join(tr.xpath('./td[1]/text()')).strip(),
'price': ''.join(tr.xpath('./td[2]/text()')).strip(),
'unit': ''.join(tr.xpath('./td[3]/text()')).strip(),
'supermaket': ''.join(tr.xpath('./td[4]/text()')).strip(),
'time': ''.join(tr.xpath('./td[5]/text()')).strip()
}
咱們打印一下print(tr),看下效果。
此時,你的心情也許是這樣的:
但還沒完,數(shù)據(jù)有了,咱們還得保存csv格式到本地,這一步比較簡單,直接貼代碼。
with open('wood.csv', 'a', encoding='utf_8_sig', newline='') as fp:
# 'a'為追加模式(添加)
# utf_8_sig格式導(dǎo)出csv不亂碼
fieldnames = ['name', 'price', 'unit', 'supermaket', 'time']
writer = csv.DictWriter(fp, fieldnames)
writer.writerow(tr)
打開下剛生成的wood.csv,長這樣:
二.爬取多頁
別開心的太早,你還僅僅是爬了一頁數(shù)據(jù),人家復(fù)制粘貼都比你快。咱們的志向可不在這,在詩和遠方,哦不,是秒速爬海量數(shù)據(jù)。
那么,怎么才能爬取多頁數(shù)據(jù)呢?沒錯,for循環(huán)。
我們再回過頭來分析下url:
:8003/.jspx?page.=1&=%E7%BA%A2%E6%9C%A8%E7%B1%BB
我們把里面的page.改成2試試,如下:
你也許發(fā)現(xiàn)玄機,只要改變page.就可以實現(xiàn)翻頁。OK,那我們直接在url前面加個循環(huán)就好啦。(x)是一種格式化字符串的函數(shù),可以接受不限個數(shù)的參數(shù)。
for x in range(1,3):
url = 'http://yz.yuzhuprice.com:8003/findPriceByName.jspx?page.curPage={}&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB'.format(x)
至此,你只要改變range想爬多少頁就爬多少頁,開不開心?意不意外?
三.完善爬蟲
如果僅僅按照以上代碼爬蟲,很有可能爬了十幾頁程序就崩了。我就多次遇到過中途報錯,導(dǎo)致爬蟲失敗的情況。好不容易寫出的爬蟲,怎么說崩就崩呢。
報錯原因就很多了,玩爬蟲的都知道,調(diào)試bug是很麻煩的,需要不斷試錯。這個爬蟲的主要bug是。因此,我們需要進一步完善代碼。
首先,要將以上代碼封裝成函數(shù),因為不用函數(shù)有以下缺點:
1、復(fù)雜度增大
2、組織結(jié)構(gòu)不夠清晰
3、可讀性差
4、代碼冗余
5、可擴展性差
其次,在可能出現(xiàn)報錯的地方都加上異常處理。即try…。
完善之后,截取部分,如下圖。限于篇幅,我就不貼所有代碼了,需要完整代碼的小伙伴可以微信掃描下方CSDN官方認證二維碼免費領(lǐng)取【保證100%免費】。
關(guān)于技術(shù)儲備
學(xué)好 不論是就業(yè)還是做副業(yè)賺錢都不錯,但要學(xué)會 還是要有一個學(xué)習(xí)規(guī)劃。最后大家分享一份全套的 學(xué)習(xí)資料,給那些想學(xué)習(xí) 的小伙伴們一點幫助!
一、所有方向的學(xué)習(xí)路線
所有方向的技術(shù)點做的整理,形成各個領(lǐng)域的知識點匯總,它的用處就在于,你可以按照上面的知識點去找對應(yīng)的學(xué)習(xí)資源,保證自己學(xué)得較為全面。
二、必備開發(fā)工具
四、視頻合集
觀看零基礎(chǔ)學(xué)習(xí)視頻,看視頻學(xué)習(xí)是最快捷也是最有效果的方式,跟著視頻中老師的思路,從基礎(chǔ)到深入,還是很容易入門的。
五、實戰(zhàn)案例
光學(xué)理論是沒用的,要學(xué)會跟著一起敲,要動手實操,才能將自己的所學(xué)運用到實際當(dāng)中去,這時候可以搞點實戰(zhàn)案例來學(xué)習(xí)。
這份完整版的全套學(xué)習(xí)資料已經(jīng)上傳CSDN,朋友們?nèi)绻枰梢晕⑿艗呙柘路紺SDN官方認證二維碼免費領(lǐng)取【保證100%免費】
