

本發明屬于與文本無關的說話人辨認(n,si)技術領域,具體涉及到深度神經網絡(,dnn)與高斯混合模型(,gmm)相結合的說話人識別方法。
背景技術
語音信號中不僅包含著文本內容的信息,也包含了說話人的身份信息,并且每個說話人的語音信號都具有獨特性,這使得說話人辨認技術得以實現。常用的說話人識別方法有基于模板模型的動態時間規整方法、矢量量化方法、基于概率模型的隱馬爾可夫模型法(,hmm)和高斯混合模型法。其中,高斯混合模型得到了最為廣泛的應用,也是最為成熟的方法。2006年提出的將gmm結合svm用于說話人識別的方法成為當時的主流技術。
深度學習作為機器學習的一個分支,近年來極大地促進了人工智能的發展,它是從人工神經網絡發展出來的新領域。深度學習發展至今,已經應用到圖像處理、語音處理、自然語言處理等多個領域,并取得了巨大的成功。現有的研究表明利用dnn來進行說話人識別工作是可行的,而利用dnn來進行說話人識別的方法大體上可分為兩類,即“直接應用”和“間接應用”。前者是將dnn單純地作為一個分類器用于識別任務中,而后者則是把dnn作為一個工具來提取特征,隨后利用其它分類器來進行語音識別。上述的gmm-svm和dnn這兩種方法都是單獨地應用于說話人辨認中,但各自又存在較為明顯的弱點,嚴重限制了說話人辨認的準確性和系統能效。
技術實現要素:
本發明針對gmm-svm模型中傳統超矢量沒有充分利用各個高斯分量均值矢量之間的關聯性,目的旨在提出一種融合gmm和dnn這兩種方法的新技術用于實現說話人辨認。
本發明實現上述目的的技術解決方案為:一種基于dnn與gmm模型的說話人識別方法,其特征在于包括:
步驟一:在給定特征參數mfcc的前提下,基于gmm-svm提取超矢量實現數據降維,并擬構建相關超矢量來提取攜帶更豐富的說話人身份信息的特征;
步驟二:構造深度信念網絡體系結構來提取說話人深度特征;
步驟三:結合相關超矢量和瓶頸特征以構建新的說話人辨認系統。
進一步地,其中步驟一包含:
s11、對語音信號進行預處理后提取mfcc參數;

s12、提取gmm超矢量并關聯預設范圍內的均值矢量形成相關超矢量;
s13、在gmm模型基礎上搭建svm實現分類,并且通過實驗對比選擇最合適的svm核函數。
更進一步地,所述預處理至少為預加重、加窗、分幀和端點檢測。
進一步地,其中步驟二包含:
s21、構造兩端寬中間窄的dbn模型,先進行預訓練再通過有監督的方式進行精細調整以得到訓練好的深度信念網絡;
s22、將訓練和測試語音經過預處理后提取的mfcc參數作為這個深度信念網絡的輸入以提取瓶頸層的特征。
進一步地,其中步驟三在gmm-svm模型的基礎上,將步驟一、二中所提出的相關超矢量和瓶頸特征同時應用到這個模型中,得到最優的說話人辨認系統,其中瓶頸特征隨dbn模型的結構參數變化可調,相關超矢量隨預設范圍內高斯關聯數變化可調。
應用本發明的該說話人識別方法,較之于傳統此類單獨方法具備突出的實質性特點和顯著的進步性:該方法提出的深度神經網絡結構可以充分表征語音信號中更深層次的能表征語音說話人特性的信息,從而克服了傳統特征幀間信息被忽略、不能挖掘語音信號深層結構信息的缺點;與傳統gmm超矢量相比,相關超矢量在實現數據降維的同時在一定程度上提高了識別率,并且減少了系統建模時間。
附圖說明
圖1是說話人識別的基本框圖。
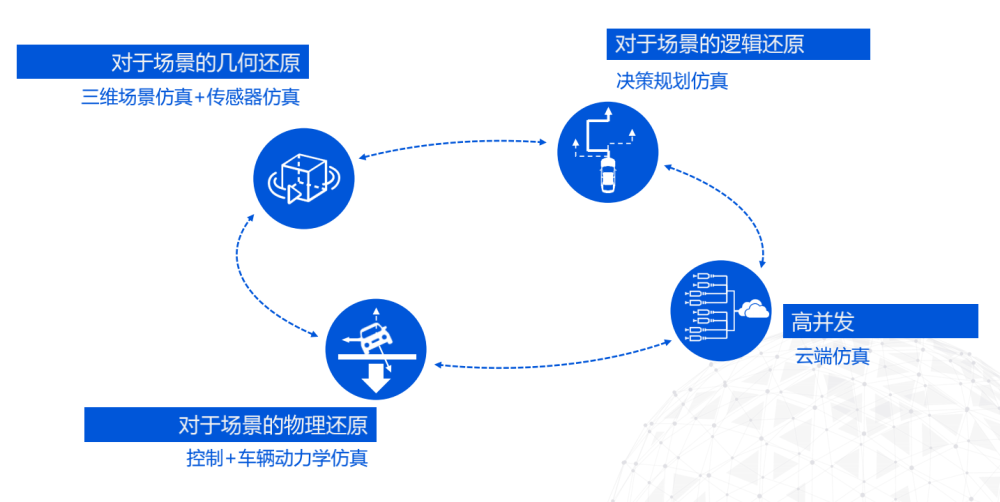
圖2是傳統mfcc特征參數條件下說話人識別率隨高斯關聯數的變化情況。
圖3是深度信念網絡的結構圖。
圖4是本發明的整體結構框圖。
圖5是瓶頸特征條件下說話人識別率與高斯關聯數的關系。
圖6是系統建模時間隨高斯關聯數的變化。
具體實施方式
以下便結合實施例附圖,對本發明的具體實施方式作進一步的詳述,以使本發明技術方案更易于理解、掌握說話人識別 模型包括,從而對本發明的保護范圍做出更為清晰的界定和支持。
下面結合圖1所示說話人識別的基本框圖,對本發明的具體實施方式做進一步的具體說明。
步驟一:基于改進的gmm-svm模型實現說話人識別。
本發明采用筆者所在團隊在消音室錄制的語料,該數據庫包含210個說話人的語音,每個人有180條語音,語音信號的采樣頻率為16khz。對語音進行分幀處理時,為了使數據的過渡更為平滑,幀長取256點,幀移取128點。本發明的試驗采用10說話人,每人80條語句,其中訓練語句60條,平均時長3s。將預處理后的語音幀經過fft、dct等變換后就可以得到mfcc參數。
每幀信號我們提取24維的mfcc參數和24維的一階差分mfcc參數,高斯混合數固定為1024。在輸入特征參數為mfcc前提下提取gmm超矢量,由于原始的gmm-svm系統沒有考慮到各個高斯分量的均值矢量之間的關聯性,每個均值矢量樣本的信息量也不夠,我們對組成gmm超矢量的各個均值向量進行重新組合。每個高斯分量的均值矢量為
,并且
是維數為48的向量,即超矢量
。若選擇高斯關聯數的個數是
,并且
,則我們得到的第一個新的均值向量為:
,依次遍歷整個超矢量,得到相關超矢量。相關超矢量具有的新的均值向量個數為p,并且滿足關系:
。則相關超矢量
為
。本發明中可選的高斯關聯數有
,并且訓練樣本和測試樣本的相關超矢量選擇相同的高斯關聯數。

將訓練階段提取的相關超矢量用于svm的訓練,在測試階段語音也經過預處理、特征參數以及超矢量的提取,最后構建相關超矢量與訓練階段得到的svm模型來進行匹配從而得到識別結果。svm的性能很大程度上取決于核函數的選擇,但是目前沒有很好的方法來針對具體問題指導選擇特定的核函數。常用的核函數有線性核函數、多項式核函數、徑向基核函數和核函數。從圖2中我們可以看出使用徑向基核函數時系統的識別率最好,而多項式核函數時,系統的識別率最差。就核函數為徑向基的情況下,高斯關聯數
為1的時候,即相關超矢量等于原始超矢量,這時系統識別率最低。隨著高斯關聯數遞增至64和128,系統識別率達到最高為96.125%。可以看出將相關超矢量應用于系統當中,均比應用原始超矢量的系統的識別率高。根據所提供的數據可看出,本發明提出的相關超矢量能夠確切的提高系統的識別率。
步驟二:構造深度信念網絡體系結構來提取說話人深度特征。
為了能夠得到語音中“不變”的、足夠“頑健”的說話人個體特征參數,構建一種中間的某個隱層的神經元個數遠小于輸入層和其它隱層神經元個數的深度信念網絡,并將這一隱層稱為瓶頸層,具體結構如圖3所示。深度信念網絡是一個概率生成模型,由多個受限玻爾茲曼機(rbm)堆疊而成。我們通過無監督的逐層貪婪算法訓練dbn,隱層單元訓練的目的是為了捕捉可視層單元表現出來的高階數據的相關性,從而更好地擬合可視層的輸入數據。通過預訓練的方式我們就可得到dbn的模型參數,這也就是深度神經網絡的初始參數,然后對這個深度神經網絡進行有監督的fine-之后就得到訓練好的dbn。相比傳統的對神經網絡采用隨機初始化網絡參數的方式,采用預訓練的方法有效解決了傳統神經網絡易陷入局部極小值等缺點。
首先對每幀信號提取48維的mfcc參數(即零階24維和一階24維),隨后對mfcc特征參數采用零均值、標準差歸一化的方式進行數據的歸一化處理。對于如圖3所示的dbn,除瓶頸層之外的所有隱藏層的神經元個數為200,輸出層神經元的個數與分類類別數一致,即為10。而為了更有利于分類信息的壓縮,瓶頸層節點數要比其他隱層節點數少的多。實驗中第一個隱藏層的學習率為0.0002,其余隱藏層的學習率為0.002。訓練好dbn后,就可以用dbn分別對訓練語音和測試語音提取深度特征,瓶頸特征的維數與瓶頸層神經元的個數一致。
步驟三:基于相關超矢量和瓶頸特征實現說話人辨認。
為了充分利用上述的相關超矢量和深度特征的優勢,構建一個結合gmm-svm和dbn新的說話人辨認系統,如圖4。首先對每幀語音信號提取48維的mfcc特征參數,將mfcc作為dbn的輸入提取瓶頸特征,然后基于瓶頸特征利用gmm提取超矢量并進一步構建相關超矢量,最后利用svm實現模式匹配和分類。
為了優化說話人辨認系統的性能,本發明探索了不同dbn結構參數對識別率的影響。首先固定隱層層數為3層,中間一層為瓶頸層,改變瓶頸層的神經元個數,通過多組實驗發現當瓶頸層節點數為48,即與輸入mfcc特征參數的維數一致時,說話人的識別率是最高的。一般來說越深的網絡結構模型越能取得好的效果,緊接著本發明在瓶頸層節點數固定為48的前提下,討論了網絡深度對識別率的影響。我們分別設置了隱層層數為2層、3層、4層和5層,其中擁有2個隱層的網絡把第一隱層設為瓶頸層,而擁有3、4和5個隱層的網絡則把第二隱層設為瓶頸層。通過實驗對比,當隱層個數為3層,識別率相對較高。而當隱層層數再增加時,識別率反而下降,因為網絡模型越深,所需的數據量也越大說話人識別 模型包括,從而有限的數據不能充分地訓練dbn。
在dbn性能最優的情況下,即隱層層數為3層、瓶頸層節點數為48個,本文利用dbn提取的瓶頸特征作為改進的gmm-svm模型的輸入特征。從圖5中看出,在徑向基和核函數條件下,當高斯關聯數為64時,說話人的識別率能達到98.125%,相對于前面的基于傳統mfcc參數的改進的gmm-svm模型其值提高了1.875%。
本發明還研究了系統建模時間與高斯關聯數的關系,從圖6可以看出,高斯關聯數越大,系統建模所需的時間越短。因而當高斯關聯數為64時,在達到最大識別率的前提下,建模時間比原始系統的建模時間縮短了很多。
以上實驗結果表明:與傳統的高斯超矢量相比,本文所構建的相關超矢23量可以顯著地提高說話人的識別率。將相關超矢量和瓶頸特征同時應用在gmm-svm模型中時,識別率相對基于mfcc的gmm-svm模型不僅可以進一步提高,還可以減少系統識別說話人身份所需的時間。
以上詳細描述了本發明的優選實施方式,但是,本發明并不局限于上述特定實施方式,本領域技術人員可以在權利要求的范圍內進行修改或者等同變換,均應包含在本發明的保護范圍之內。