

在SQL 中,當訪問數據庫中的數據時,由SQL 確定該表中是否有索引存在。如果沒有索引,那么SQL 使用表掃描的方法訪問數據庫中的數據。查詢處理器根據分布的統計信息生成該查詢語句的優化執行規劃,以提高訪問數據的效率為目標,確定是使用表掃描還是使用索引。
索引的選項
在創建索引時,可以指定一些選項,通過使用這些選項,可以優化索引的性能。這些選項包括選項、選項和選項。
使用選項,可以優化插入語句和修改語句的性能。當某個索引頁變滿時,SQL 必須花費時間分解該頁,以便為新的記錄行騰出空間。使用選項,就是在葉級索引頁上分配一定百分比的自由空間,以便減少頁的分解時間。當在有數據的表中創建索引時,可以使用選項指定每一個葉級索引節點的填充的百分比。缺省值是0,該數值等價于100。在創建索引的時候,內部索引節點總是留有了一定的空間,這個空間足夠容納一個或者兩個表中的記錄。在沒有數據的表中,當創建索引的時候,不要使用該選項,因為這時該選項是沒有實際意義的。另外,該選項的數值在創建時指定以后,不能動態地得到維護,因此,只應該在有數據的表中創建索引時才使用。
選項將選項的數值同樣也用于內部的索引節點,使內部的索引節點的填充度與葉級索引的節點中的填充度相同。如果沒有指定選項,那么單獨指定選項是沒有實際意義的,這是因為選項的取值是由選項的取值確定的。
當創建聚簇索引時,選項清除排序,因此可以減少建立聚簇索引所需要的時間。當在一個已經變成碎塊的表上創建或者重建聚簇索引時,使用選項可以壓縮數據頁。當重新需要在索引上應用填充度時,也使用該選項。當使用選項時,應該考慮這些因素:SQL 確認每一個關鍵值是否比前一個關鍵值高,如果都不高,那么不能創建索引;SQL 要求1.2倍的表空間來物理地重新組織數據;使用選項,通過清除排序進程而加快索引創建進程;從表中物理地拷貝數據;當某一個行被刪除時,其所占的空間可以重新利用;創建全部非聚簇索引;如果希望把葉級頁填充到一定的百分比,可以同時使用選項和選項。
索引的維護
為了維護系統性能,索引在創建之后,由于頻繁地對數據進行增加、刪除、修改等操作使得索引頁發生碎塊,因此,必須對索引進行維護。
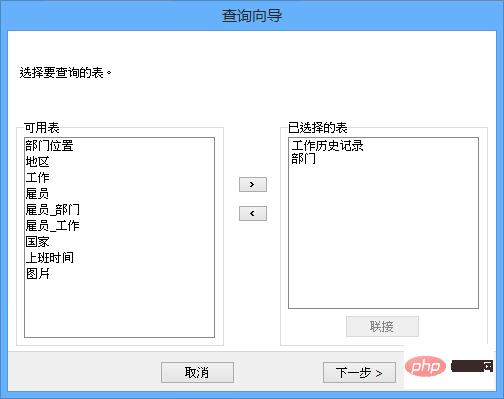
使用DBCC 語句,可以顯示表的數據和索引的碎塊信息。當執行DBCC 語句時,SQL 瀏覽葉級上的整個索引頁,來確定表或者指定的索引是否嚴重碎塊。DBCC 語句還能確定數據頁和索引頁是否已經滿了。當對表進行大量的修改或者增加大量的數據之后,或者表的查詢非常慢時,應該在這些表上執行DBCC 語句。當執行DBCC 語句時索引是對數據庫表中,應該考慮這些因素:當執行DBCC 語句時,SQL 要求指定表的ID號或者索引的ID號,表的ID號或者索引的ID號可以從系統表中得到;應該確定多長時間使用一次DBCC 語句,這個時間長度要根據表的活動情況來定,每天、每周或者每月都可以。
使用DBCC 語句重建表的一個或者多個索引。當希望重建索引和當表上有主鍵約束或者唯一性鍵約束時,執行DBCC 語句。除此之外,執行DBCC 語句還可以重新組織葉級索引頁的存儲空間、刪除碎塊和重新計算索引統計。當使用執行DBCC 語句時,應該考慮這些因素:根據指定的填充度,系統重新填充每一個葉級頁;使用DBCC 語句重建主鍵約束或者唯一性鍵約束的索引;使用選項可以更快地創建聚簇索引,如果沒有排列關鍵值,那么不能使用DBCC 語句;DBCC 語句不支持系統表。另外,還可以使用數據庫維護規劃向導自動地進行重建索引的進程。
統計信息是存儲在SQL 中的列數據的樣本。這些數據一般地用于索引列,但是還可以為非索引列創建統計。SQL 維護某一個索引關鍵值的分布統計信息,并且使用這些統計信息來確定在查詢進程中哪一個索引是有用的。查詢的優化依賴于這些統計信息的分布準確度。查詢優化器使用這些數據樣本來決定是使用表掃描還是使用索引。當表中數據發生變化時,SQL 周期性地自動修改統計信息。索引統計被自動地修改,索引中的關鍵值顯著變化。統計信息修改的頻率由索引中的數據量和數據改變量確定。例如,如果表中有10000行數據,1000行數據修改了,那么統計信息可能需要修改。然而,如果只有50行記錄修改了,那么仍然保持當前的統計信息。除了系統自動修改之外,用戶還可以通過執行 語句或者系統存儲過程來手工修改統計信息。使用 語句既可以修改表中的全部索引,也可以修改指定的索引。
使用和 IO語句可以分析索引和查詢性能。使用這些語句可以更好地調整查詢和索引。語句顯示在連接表中使用的查詢優化器的每一步以及表明使用哪一個索引訪問數據。使用語句可以查看指定查詢的查詢規劃。當使用語句時,應該考慮這些因素。SET 語句返回的輸出結果比SET 語句返回的輸出結果詳細。然而,應用程序必須能夠處理SET 語句返回的輸出結果。語句生成的信息只能針對一個會話。如果重新連接SQL ,那么必須重新執行語句。 IO語句表明輸入輸出的數量,這些輸入輸出用來返回結果集和顯示指定查詢的邏輯的和物理的I/O的信息。可以使用這些信息來確定是否應該重寫查詢語句或者重新設計索引。使用 IO語句可以查看用來處理指定查詢的I/O信息。

就象語句一樣,優化器隱藏也用來調整查詢性能。優化器隱藏可以對查詢性能提供較小的改進,并且如果索引策略發生了改變,那么這種優化器隱藏就毫無用處了。因此,限制使用優化器隱藏,這是因為優化器隱藏更有效率和更有柔性。當使用優化器隱藏時,考慮這些規則:指定索引名稱、當為0時為使用表掃描、當為1時為使用聚簇索引;優化器隱藏覆蓋查詢優化器,如果數據或者環境發生了變化,那么必須修改優化器隱藏。
索引調整向導
索引調整向導是一種工具索引是對數據庫表中,可以分析一系列數據庫的查詢語句,提供使用一系列數據庫索引的建議,優化整個查詢語句的性能。對于查詢語句,需要指定下列內容:
查詢語句,這是將要優化的工作量
包含了這些表的數據庫,在這些表中,可以創建索引,提高查詢性能

在分析中使用的表
在分析中,考慮的約束條件,例如索引可以使用的最大磁盤空間
這里指的工作量,可以來自兩個方面:使用SQL 捕捉的軌跡和包含了SQL語句的文件。索引調整向導總是基于一個已經定義好的工作量。如果一個工作量不能反映正常的操作,那么它建議使用的索引不是實際的工作量上性能最好的索引。索引調整向導調用查詢分析器,使用所有可能的組合評定在這個工作量中每一個查詢語句的性能。然后,建議在整個工作量上可以提高整個查詢語句的性能的索引。如果沒有供索引調整向導來分析的工作量,那么可以使用圖解器立即創建它。一旦決定跟蹤一條正常數據庫活動的描述樣本,向導能夠分析這種工作量和推薦能夠提高數據庫工作性能的索引配置。
索引調整向導對工作量進行分析之后,可以查看到一系列的報告,還可以使該向導立即創建所建議的最佳索引,或者使這項工作成為一種可以調度的作業,或者生成一個包含創建這些索引的SQL語句的文件。
索引調整向導允許為SQL 數據庫選擇和創建一種理想的索引組合和統計,而不要求對數據庫結構、工作量或者SQL 內部達到專家的理解程度。總之,索引調整向導能夠作到以下幾個方面的工作:
通過使用查詢優化器來分析工作量中的查詢任務,向有大量工作量的數據庫推薦一種最佳的索引混合方式
分析按照建議作出改變之后的效果,包括索引的用法、表間查詢的分布和大量工作中查詢的工作效果
為少量查詢任務推薦調整數據庫的方法
通過設定高級選項如磁盤空間約束、最大的查詢語句數量和每個索引的最多列的數量等,允許定制推薦方式
圖解器

圖解器能夠實時抓取在服務器中運行的連續圖片,可以選取希望監測的項目和事件,包括-SQL語句和批命令、對象的用法、鎖定、安全事件和錯誤。圖解器能夠過濾這些事件,僅僅顯示用戶關心的問題。可以使用同一臺服務器或者其他服務器重復已經記錄的跟蹤事件,重新執行那些已經作了記錄的命令。通過集中處理這些事件,就能夠很容易監測和調試SQL 中出現的問題。通過對特定事件的研究,監測和調試SQL 問題變得簡單多了。
查詢處理器
查詢處理器是一種可以完成許多工作的多用途的工具。在查詢處理器中,可以交互式地輸入和執行各種-SQL語句,并且在一個窗口中可以同時查看-SQL語句和其結果集;可以在查詢處理器中同時執行多個-SQL語句,也可以執行腳本文件中的部分語句;提供了一種圖形化分析查詢語句執行規劃的方法,可以報告由查詢處理器選擇的數據檢索方法,并且可以根據查詢規劃調整查詢語句的執行,提出執行可以提高性能的優化索引建議,這種建議只是針對一條查詢語句的索引建議,只能提高這一條查詢語句的查詢性能。
系統為每一個索引創建一個分布頁,統計信息就是指存儲在分布頁上的某一個表中的一個或者多個索引的關鍵值的分布信息。當執行查詢語句時,為了提高查詢速度和性能,系統可以使用這些分布信息來確定使用表的哪一個索引。查詢處理器就是依賴于這些分布的統計信息,來生成查詢語句的執行規劃。執行規劃的優化程度依賴于這些分布統計信息的準確步驟的高低程度。如果這些分布的統計信息與索引的物理信息非常一致,那么查詢處理器可以生成優化程度很高的執行規劃。相反,如果這些統計信息與索引的實際存儲的信息相差比較大,那么查詢處理器生成的執行規劃的優化程度則比較低。
查詢處理器從統計信息中提取索引關鍵字的分布信息,除了用戶可以手工執行 之外,查詢處理器還可以自動收集統計這些分布信息。這樣,就能夠充分保證查詢處理器使用最新的統計信息,保證執行規劃具有很高的優化程度,減少了維護的需要。當然,使用查詢處理器生成的執行規劃,也有一些限制。例如,使用執行規劃只能提高單個查詢語句的性能,但是可能對整個系統的性能產生正面的或者付面的影響,因此,要想提高整個系統的查詢性能,應該使用索引調整向導這樣的工具。
結論
在以前的SQL 版本中,在一個查詢語句中,一個表上最多使用一個索引。而在SQL 7.0中,索引操作得到了增強。SQL 現在使用索引插入和索引聯合算法來實現在一個查詢語句中的可以使用多個索引。共享的行標識符用于連接同一個表上的兩個索引。如果某個表中有一個聚簇索引,因此有一個聚簇鍵,那么該表上的全部非聚簇索引的葉節點使用該聚簇鍵作為行定位器,而不是使用物理記錄標識符。如果表中沒有聚簇索引,那么非聚簇索引繼續使用物理記錄標識符指向數據頁。在上面的兩種情況中,行定位器是非常穩定的。當聚簇索引的葉節點分開時,由于行定位器是有效的,所以非聚簇索引不需要被修改。如果表中沒有聚簇索引,那么頁的分開就不會發生。而在以前的版本中,非聚簇索引使用物理記錄標識符如頁號和行號,作為行的定位器。例如,如果聚簇索引(數據頁)發生分解時,許多記錄行被移動到了一個新的數據頁,因此有了多個新的物理記錄標識符。那么,所有的非聚簇索引都必須使用這些新的物理記錄標識符進行修改,這樣就需要耗費大量的時間和資源。
索引調整向導無論對熟練用戶還是新用戶,都是一個很好的工具。熟練用戶可以使用該向導創建一個基本的索引配置,然后在基本的索引配置上面進行調整和定制。新用戶可以使用該向導快速地創建優化的索引。