

本文通過一個命令行轉換 pdf 為詞云的例子,給你講講 軟件包安裝遇挫折時,怎么處理才更高效?
遭遇
前兩天,有位讀者留言求助。
起因是他讀我的《如何用做詞云?》一文。按照樣例成功做出詞云后,覺得很興奮。不過,他不滿足于照貓畫虎做出結果,找到了 的 頁面,查看附加功能。
對這一點,我是非常贊賞的。因為這種按圖索驥,很多時候,都能有意外收獲和驚喜。
例如你偶然讀到一篇好文章,于是找到該作者的專欄或者公眾號,很大概率就可以讀到更多高品質的文章。當年我就是用這種方法,讀到陽志平先生和萬維鋼先生的系列文章,收獲頗豐。
同樣,一個軟件提供了一項你喜歡的功能,你找到它的網站,可能會找到其他感興趣的功能。甚至有時候,還能發現同一作者的更多優秀工具。
果不其然,這位讀者,就找到了一個令自己很興奮的功能。下圖中,我用紅線給你標出了這個功能。
對, 不僅可以在 代碼中作為模塊引入,幫你分析文本,繪制詞云;它還可以在命令行方式下,從 pdf 里面直接提取詞云出來。
就像這個樣子:
我估計,他喜歡這個功能,或許是因為最近讀 pdf 格式的論文太多了,想偷個懶吧。
這個操作,只需要終端下面的一行命令。連簡單的 編程,都不需要。
他于是興奮起來,立刻開始嘗試這個功能。
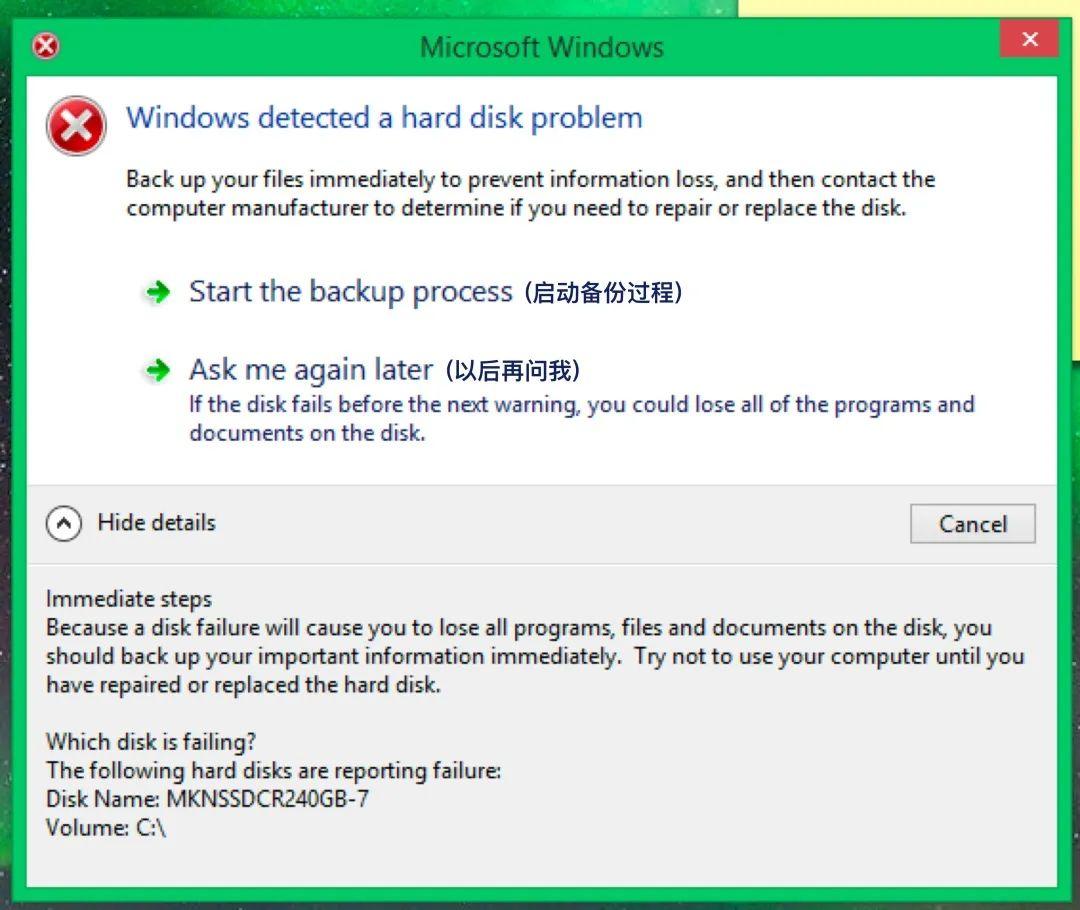
然而,這句命令一執行,就報錯。提示他的系統里面,沒有 。
他于是想,既然 ,是需要 pip 命令安裝的,那么這個 ,看來也需要 pip 安裝,對不對?
他嘗試執行:
pip install pdftotext
pip 確實找到了這個名稱的軟件包,開始安裝。他瞬間成就感爆棚。
但是,一盆冷水,很快就被潑了下來。
無論如何反復試驗,用 pip 安裝 這個軟件包,總是報錯。
他沒有氣餒,還專門用搜索引擎查了網上的資料。對于技術問答社區里,類似問題下面提及的每一種可能辦法,他都做了嘗試。
結果,也無非是報錯的提示稍微有了區別,但是問題依舊。
他無計可施了,于是來問我怎么辦。
分析
其實,他不該有挫敗感。遭遇軟件安裝困難的時候,能走到他這一步,已經難能可貴。
許多初學者,接觸 編程或者命令行操作,往往在自學時,會直接倒在第 0 步,也就是軟件安裝與環境設置上,直接放棄了。
這位讀者求助的,是遇到上圖所示的報錯時,應該怎么樣對應操作,才能讓錯誤消失。
我很愿意幫助他,但不是這個幫法。
因為他從網上找來的這些方法,都沒能解決問題。不僅如此,許多操作可能會改變系統環境(例如安裝了不同版本的依賴包,或者編譯工具等)。這些操作,可能致使現在想回到問題的初始狀態,都回不去了。
同一個報錯,背后可能有若干種原因。這就是為什么你電腦壞了,往往無法通過電話或者網上技術支持來解決,得需要現場處理,才能讓維修人員充分掌握具體情況,做出正確的處理。
當然,報錯搞不定,并不意味著問題無法有效解決。
還記得我那篇《什么是第一性原理?》嗎?我開門見山地告訴你,應該嘗試:
將事情縮減至其根本實質。
你的目的,不應該是跟報錯信息較勁,而應該弄明白,到底出了什么問題。
出問題的包,是 對吧?
那你試試,在 上搜索一下,它對應的 repo 頁面。
你很容易就找到這個網址。
下面請你下拉頁面,看跟安裝相關的部分。如下圖所示:
注意,在安裝()一部分,操作非常簡單,只需要一條 pip 命令就好。
pip install pdftotext
跟你剛剛的操作,一模一樣,對吧?
那怎么會出錯呢?
請你往上看。

這里有個“系統依賴”(OS )部分。它用了比安裝命令多出數倍的篇幅,告訴你在不同的操作系統上,需要安裝的依賴包。
如果你之前嘗試過我的那篇《貸還是不貸:如何用和機器學習幫你決策?》教程,應該記得,你遇到過類似問題。
[圖片上傳失敗…(image--51)]
對,就是最后步驟,嘗試繪制這幅決策樹可視化圖的時候,也遭遇到報錯。
錯誤出現的原因,我已經在《編程遇問題,文科生怎么辦?》一文中為你詳細解釋過了。就是因為不少 包,實際上是包裹了其他軟件、甚至是系統級別的功能,方便你使用。要正常安裝使用這種 包,你首先需要確保系統擁有這些功能,或者已經安裝了相應的軟件。這就叫做依賴()。
好了,問題找到了。因為這位讀者,沒有安裝對應的依賴。
所以,他雖然下了很大功夫,搜索問題病癥和解決方案,但是都是從具體的報錯信息出發的。因此一直跟 gcc 、頭文件這些編譯相關的內容較勁兒。找到的解決方案,其實跟遇到的問題,并不匹配。他其實本不需要見識各種各樣的報錯信息,而只需要把相應的依賴軟件安裝就好了。
這位讀者,用的是 macOS 。
回顧一下官網給出的依賴要求:
那么,他需要執行:
brew install pkg-config poppler
寫到這里,似乎應該是個大團圓的結局了。對吧?
未必。
因為他非常可能,立即會遇到新的報錯。
新問題
怎么又報錯了?!
因為 brew 命令,屬于 套件,它不是 macOS 系統里自帶的工具。
好吧,他可以去搜索引擎查找 brew 是怎么回事兒,繼而到 的官網成功下載,然后學習如何安裝……
最終,估計他可以走到正確的路徑上來了。
你可以替他高興,但是我們不要過早歡呼。
因為這種解決方案,其實只是個例,不具備可推廣性。
更多人用的操作系統,是 對不對?
回過頭來看看,剛才的系統依賴清單里面,有 嗎?
沒有。
是不是因為作者忘了寫?
又或者,是不是因為 本身已經有了相關軟件集成,無須安裝?
都不是。
現實是殘酷的。
打開 官方 頁面的答疑記錄來看, 干脆就無法像 Linux 或者 macOS 一樣,一行命令安裝好依賴。
軟件作者給你指出的方向,居然是安裝 這樣的編譯器,然后自己編譯出來。
對于文科生來說,這不厚道啊!
……
你別急著放棄啊!我還沒說完呢。
曲徑
遇到問題,不要第一時間只想到“放棄”這種方法。
雖然學會止損很重要。但是如果因為有困難,就放棄解決問題,那就背離初衷了。
倘若人類的祖先都這樣處理問題,今天我們或許都在樹上呆著,跟大自然“和諧相處”呢。
但那恐怕只是我們的美好幻想——更大的可能性,是我們這個物種早就滅絕了。
面對新的問題,請你再度拿出“第一性原理”的思考方式。
注意我們的問題已經從“如何應對報錯信息”,轉換到了“如何正確安裝 ”軟件包。
但是如果你在 平臺,似乎這個軟件包跟你緣分不是很密切。
怎么辦?
我們再思考一步,真的必須要安裝 這款軟件包嗎?
這樣一問,答案呼之欲出:不一定啊!
許多功能,都有不同的軟件包可以做到。
之前的教程里,你已經看到了許多的例子。
例如繪圖,你既可以用 ,也可以用 ;
中文分詞,你既可以用 boson NLP,也可以用結巴分詞;

深度學習,你既可以用 ,也可以用 Keras,還可以用 。
這里,重新給你回放一下 官方 repo 上面的那行示例語句:
pdftotext mydocument.pdf - | wordcloud_cli --imagefile wordcloud.png
思考一下,使用 這個軟件包,用來做什么?
對,是用來把 pdf 文件,變成文本。
有了文本,喂給 工具,它就能做成詞云。
我們需要的,根本就不是正確安裝 ,而是找到一個工具,把 pdf 給我們轉換成為文本。
好了,“把 pdf 轉換成為文本”讓你想到了什么?
如果你沒有想到我給你寫過的《如何用批量提取PDF文本內容?》,那就需要“學而時習之”了。
文中,我給你介紹過一款可以完成上述功能的 軟件包,叫做 .six 。
當時,我們采用的方法,是 編程,調用 .six 軟件包作為模塊載入。
現在我們需要看看,它是否也支持命令行直接操作。
這里是它的 頁面。
下拉頁面,可以看到專門有一個部分,給你介紹如何使用 .six 命令行完成文本提取功能。
好了,我們的猜想被證實了。它完全可用。
另外請注意, .six 的安裝說明里,根本就沒有提到操作系統依賴。
這就意味著,不管你用的是 、Linux,還是 macOS ,都可以在不必安裝依賴軟件的情況下,直接用 pip 工具安裝 .six 。
步驟
下面我們來看看,如何用下面的簡單步驟,實現我們的目的——直接用命令行而非編程方式,從 pdf 文件,分析并繪制詞云。
先確保你的系統里面 3 已經安裝。如需全新安裝,請參考這個視頻教程。
然后,用 pip 命令安裝 軟件包:
pip install wordcloud

注意如果你在安裝過程中遇到問題,請參考我的另一份視頻教程。
之后,執行下述語句,安裝 .six 。
pip install pdfminer.six
你可以自己新建一個測試目錄,拷貝進入一個 pdf 文件。
或者,你也可以直接下載這個壓縮文件,解壓后有一個現成的 pdf 文件。后文還有對應生成詞云結果,供你測試和對比。
我們打開這個樣例 pdf 文件(名稱為 test.pdf ),看看內容:
之后在終端下進入該測試目錄(方法依然參考這個視頻教程),執行:
pdf2txt.py test.pdf | wordcloud_cli --imagefile wordcloud.png
對比一下,我們只是把原先 官方頁面上的命令:
pdftotext mydocument.pdf - | wordcloud_cli --imagefile wordcloud.png
前半部分進行了替換,使用了 .six 軟件包。
轉瞬間,.png 這個圖像文件就在當前目錄下生成了。打開看看:
沒毛病,對吧?
小結
如你所見,完成從 pdf 提取詞云這個功能,原本只需要上面一個小節里,幾行命令而已。即便你從 開始全新安裝解析程序包出錯,所需的時間也遠遠不到一個小時。
但是,就像這位提問的讀者一樣,如果你遭遇到了安裝中的錯誤提示,然后跟錯誤提示展開各種斗爭,并且最終無功而返。那耽誤的時間,可能遠遠不止一個小時。
你可能會辯駁,說自己從這個折騰的過程中,也學到了東西。沒錯,你會學到如何采用 來安裝 macOS 上的軟件,了解 gcc 這款開源編譯工具的使用方法,甚至是如何在 上面編譯源代碼……但是獲得這些經驗,你付出了過高的代價。你的機會成本,是原本可以用這幾個小時好好讀一兩篇高水平論文,甚至是寫作自己的工作報告或者論文初稿。
用這時間解析程序包出錯,通過不斷折騰來嘗試解決問題,還遠不是最糟糕的結果。對很多初學者來說,這種長時間反復的挫折,會嚴重打擊你嘗試新軟件、新功能的信心和興趣,甚至干脆放棄了探索的欲望。這對你的損害就太大了。
希望讀過本文,你收獲的遠不僅僅是“如何從 pdf 提取詞云”這種簡單的技巧,而是在生活、學習和工作中,充分運用第一性原理思維工具,把自己從紛繁復雜的表象里面抽身出來,擴大格局和視野,關注更本質的需求,做出明智而高效的選擇。
最后給你留一道思考題:
本文給你展示的,是從 pdf 提取詞云的最好方法嗎?
歡迎你把自己的思考結果,留言告訴我,也分享給其他人。
